Sometimes, experimentation is thought of as a standalone tool (Figure A). And the way you typically use these tools is you add some code with the experiment, run the experiment, and then, when it’s done, rip out the code. Unfortunately, this process introduces a lot of risk.
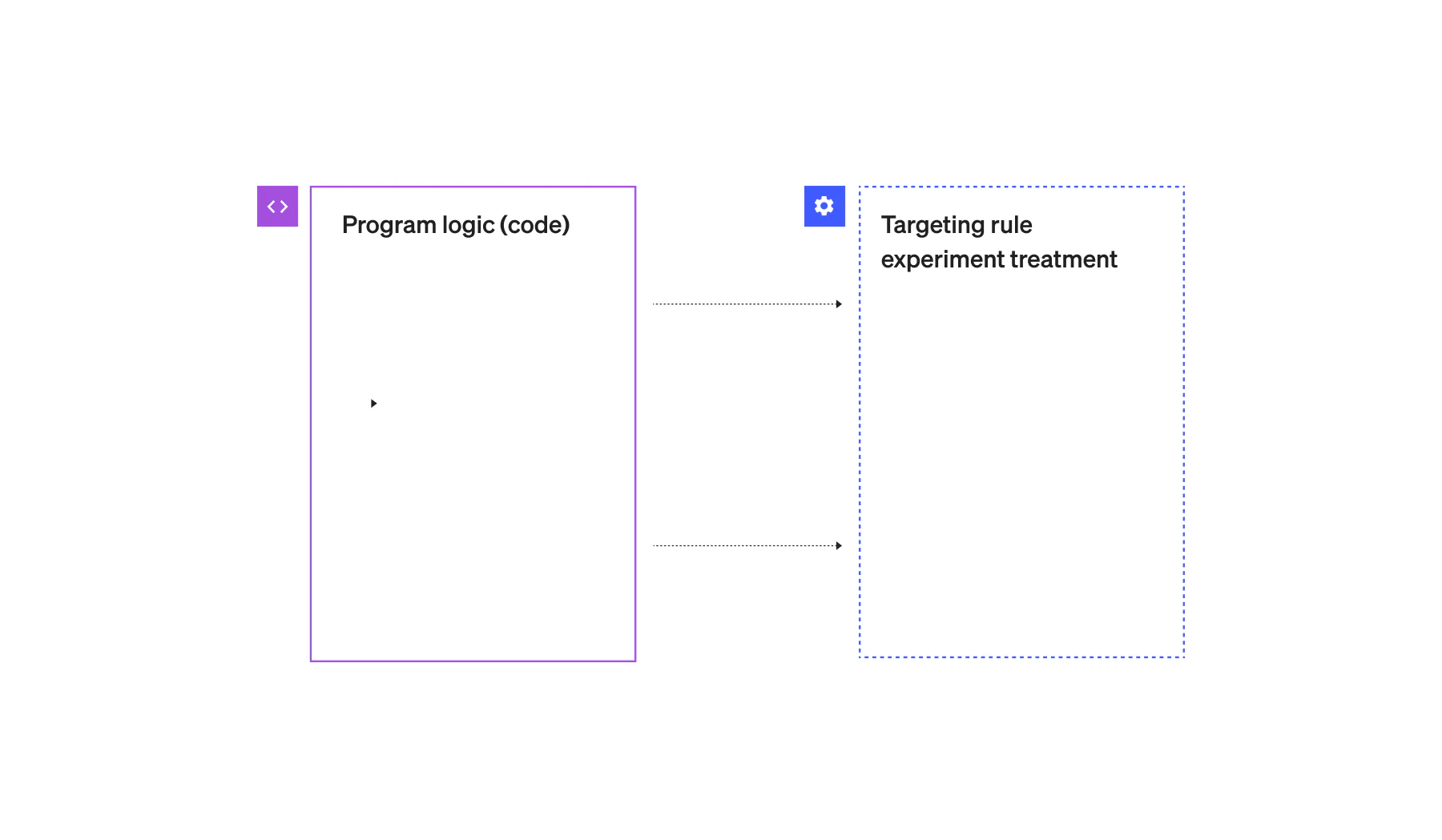
(Above: Figure A: Standalone, monolithic, experimentation tool. Here, the targeting rules, parameterization, and experiment code are all together. So when the experiment is removed the targeting is removed as well.)
In this post, I want to talk about why it’s much better to think of experimentation as a layer (Figure B) on top of your parameterization system. By parameterization system I mean a system that allows you to remotely control parameters or feature flags in your software. And by rules engine I mean a tool that allows you to configure business rules without changing code.
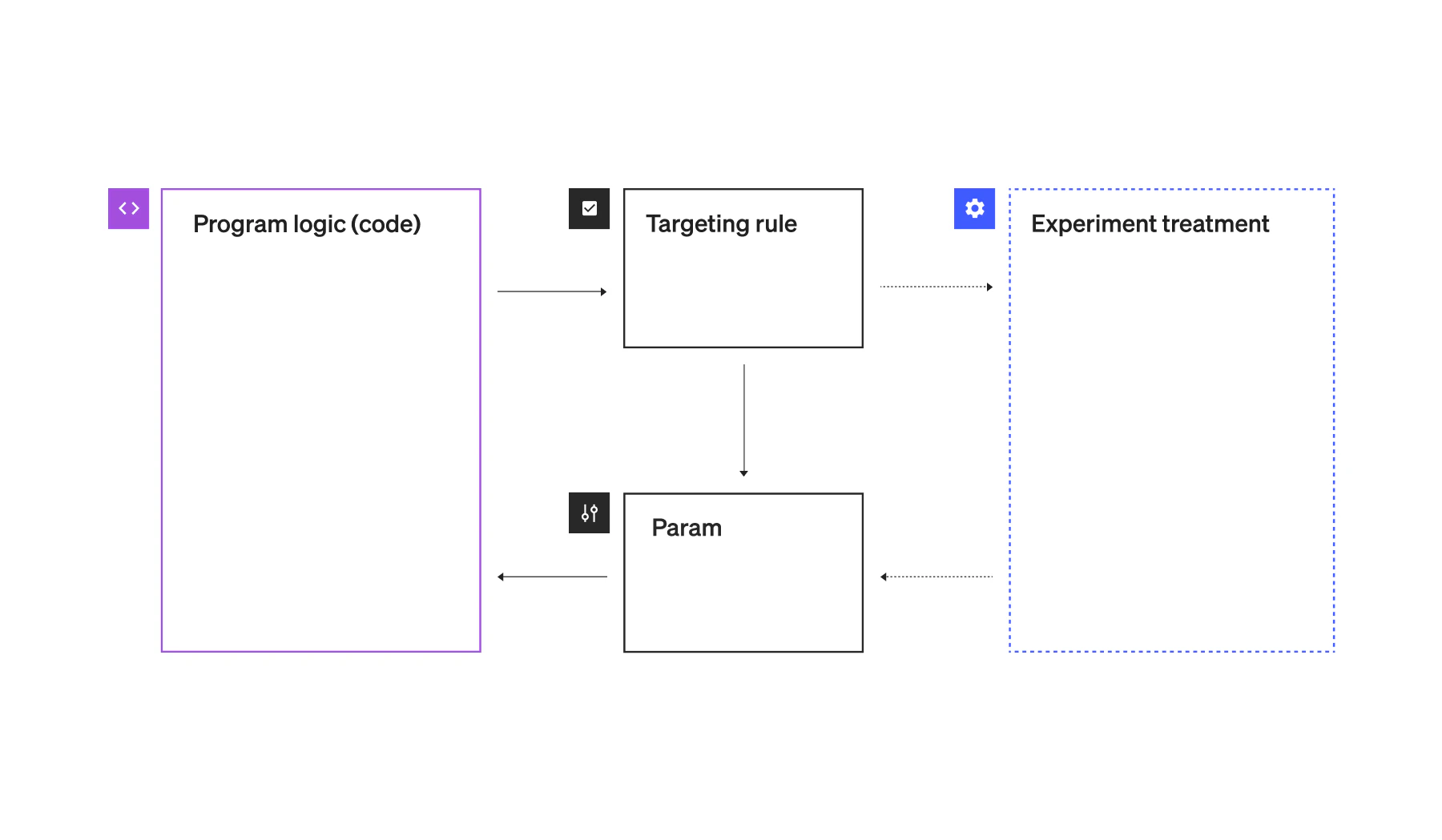
(Above: Figure B: Layered tooling. Here, the targeting rule and parameterization are a base layer which experimentation runs on top of. So when an experiment is stopped, the targeting and parameterization persist. This follows more of a single responsibility principle pattern.)
Reducing risk
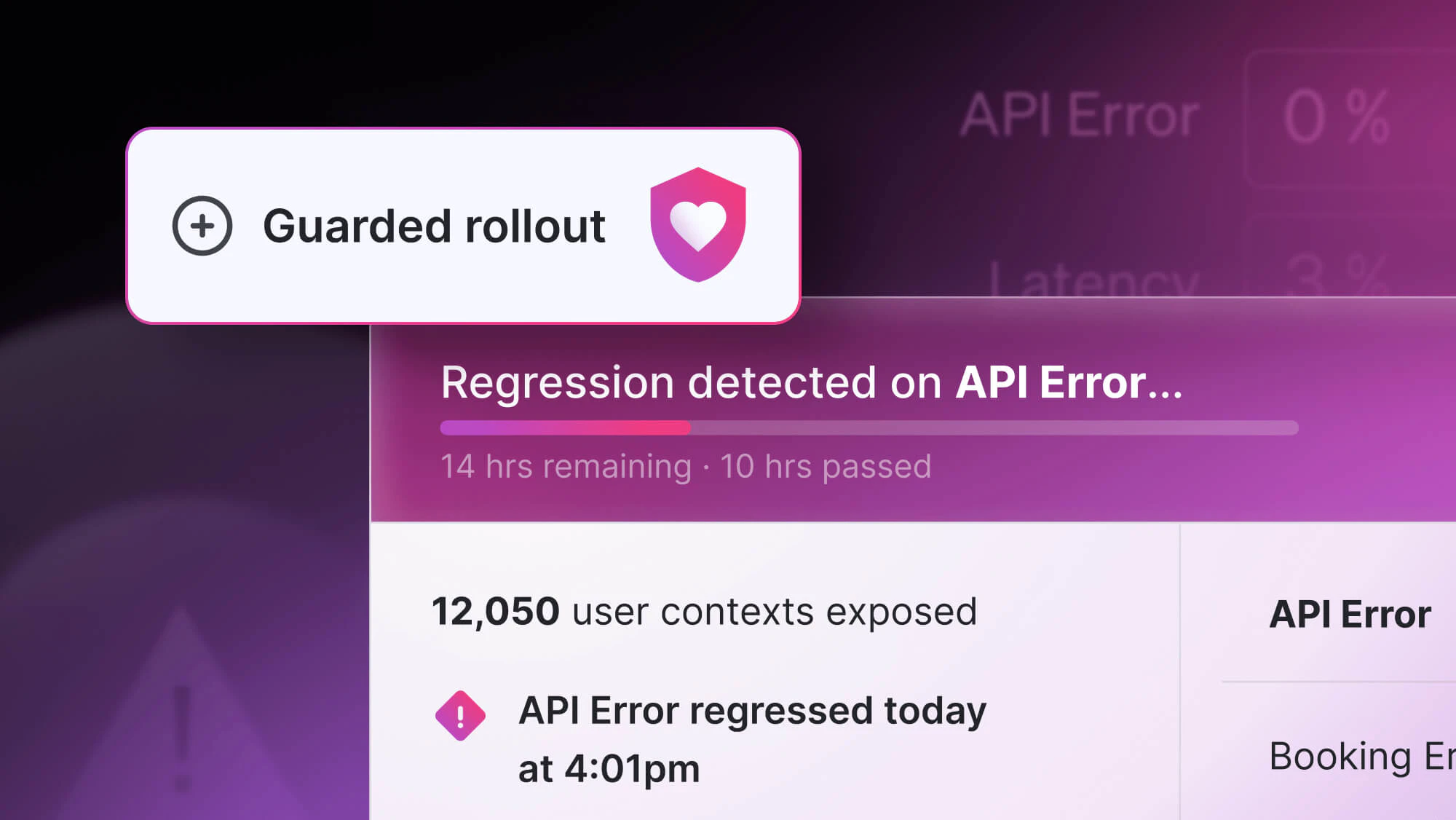
A big reason to run experiments is to understand whether a change really is better than what’s currently in production. And you do this to reduce the risk of releasing some bad software, which could then hurt important business metrics. But with an independent experimentation tool, after the experiment is finished, you have to go remove the code because it was specifically created for the experiment. Removing that code, however, introduces risk, because you can’t be confident the code is removed in such a way that the behavior of the software is exactly like it was during the experiment.
Instead, in many cases, you could parameterize your code. For example, maybe the parameter is something as simple as a button color or a reference to a machine learning model. Or maybe it’s a reference to a new javascript bundle, or images, copy, etc. The idea here is that the value is served from your parametrization platform, and not hard-coded as part of an if/else statement.
(Above: An example of using the value of a feature flag as the value of a variable in your code. This allows you to parameterize your system and modify the parameter values, or run experiments on the parameter values, without changing code.)
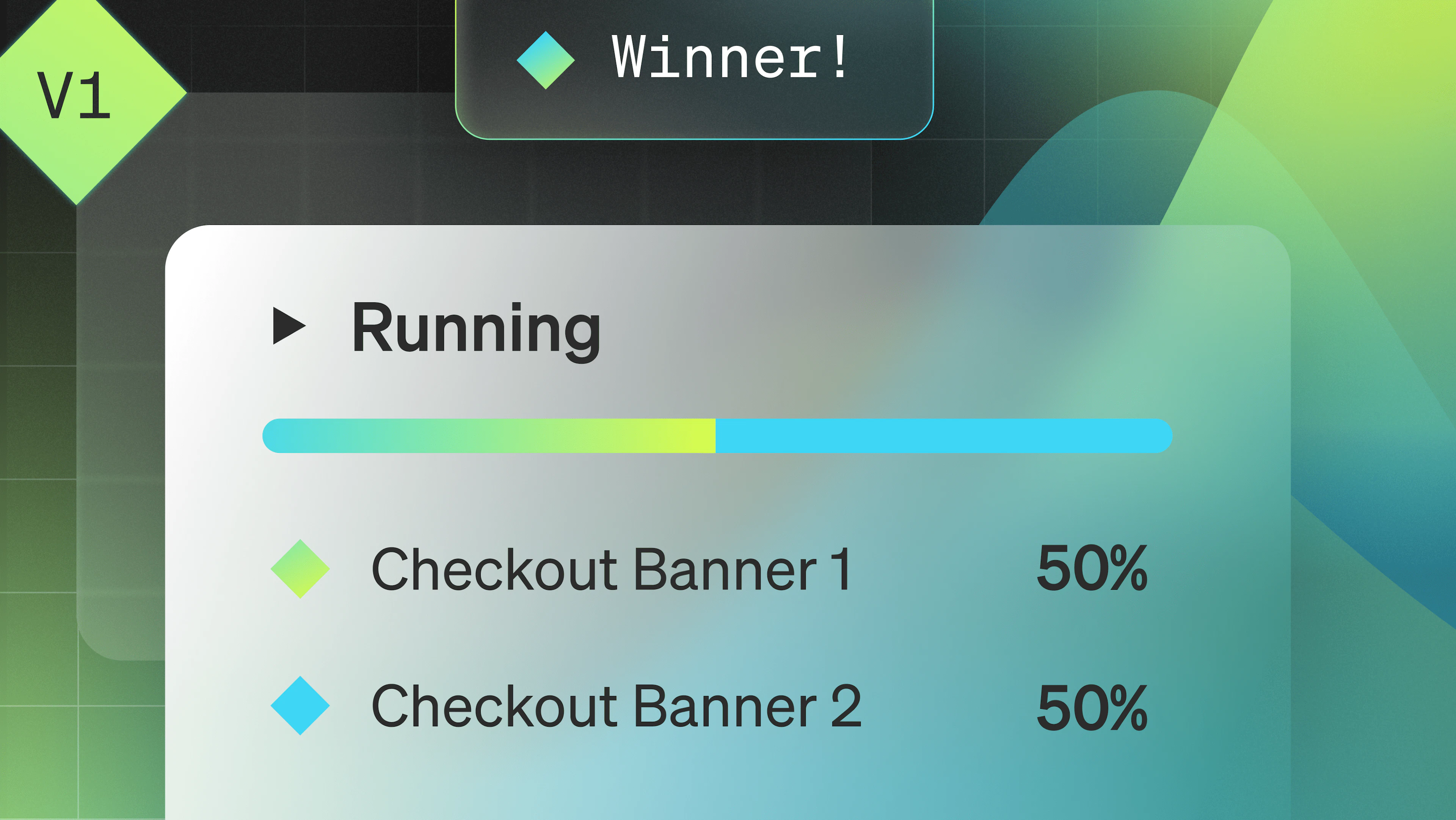
For instance, suppose you wanted to test the hero image on your homepage on an ongoing basis. Maybe sometimes for holiday specific images and other times just to improve the efficacy of your marketing site. You can add a parameter (or feature flag) named “hero-image” and it can have different variations: serene-setting.jpg, grassy-meadow.jpg, happy-family.jpg. Then when your code is evaluated, it fetches whichever image is served by the parameter. If there’s an experiment, different users might see different images. Then, when the experiment is over, you can update that parameter to send the winning value to everyone. Moreover, next time you want to run an experiment, no code change is needed, you just reuse that same parameter with your new parameter values.
Clear targeting
Similarly, suppose you don’t have a rules engine as part of your platform. If your experimentation tool allows you to target certain users, what happens when your experiment is over? Let’s say you run an experiment and you use the experiment tool to target only users in the U.S. The new variation you tested performs better than control, so you decide to roll it out. When you remove the experimentation code to make the variation the new default, you either lose your targeting rule and everyone sees the new variation (even users outside the U.S.) or you have to implement your own targeting rule which might not capture the same users as the one from your experimentation tool.
In the former case, this could be quite bad for your business. If the variation was better for the U.S., but worse elsewhere, it could have a negative impact overall and you’d be hurting the business without knowing it. In the latter case, it kind of obviates any value the targeting in the experiment tool provides. Since you’d have to implement your rules outside of the experimentation tool anyway, you shouldn’t use them in an experimentation tool where they disappear once the experiment is completed.
Instead you want to use a platform that includes a rules engine at the right level, that is, outside of experimentation. The experiments you run should be scoped within those rules so that when an experiment is over, the rules persist and you don’t inadvertently hurt your business metrics.
It’s important to keep in mind, when building or buying experimentation tools, that the right level of abstraction and the details of the implementation can have significant impacts on both your development velocity and business metrics.
When your business rules and targeting are too tightly coupled to how you establish variations of your product and experiment on them, you can introduce unnecessary risk and make it easy to expose risky variations to the wrong audience. When you build it at the right level of abstraction you can implement new rules, variations, or experiments, without affecting other parts of the system and with no unnecessary risk.
Miss our announcement about LaunchDarkly Experimentation? Check out the blog post for full details.