A guide to using feature flags to maintain high system stability, migrate your infrastructure, recover from incidents quickly, and more.
An operational feature flag manages and controls the behavior of a system. Operational feature flags are often called kill switches or circuit breakers.
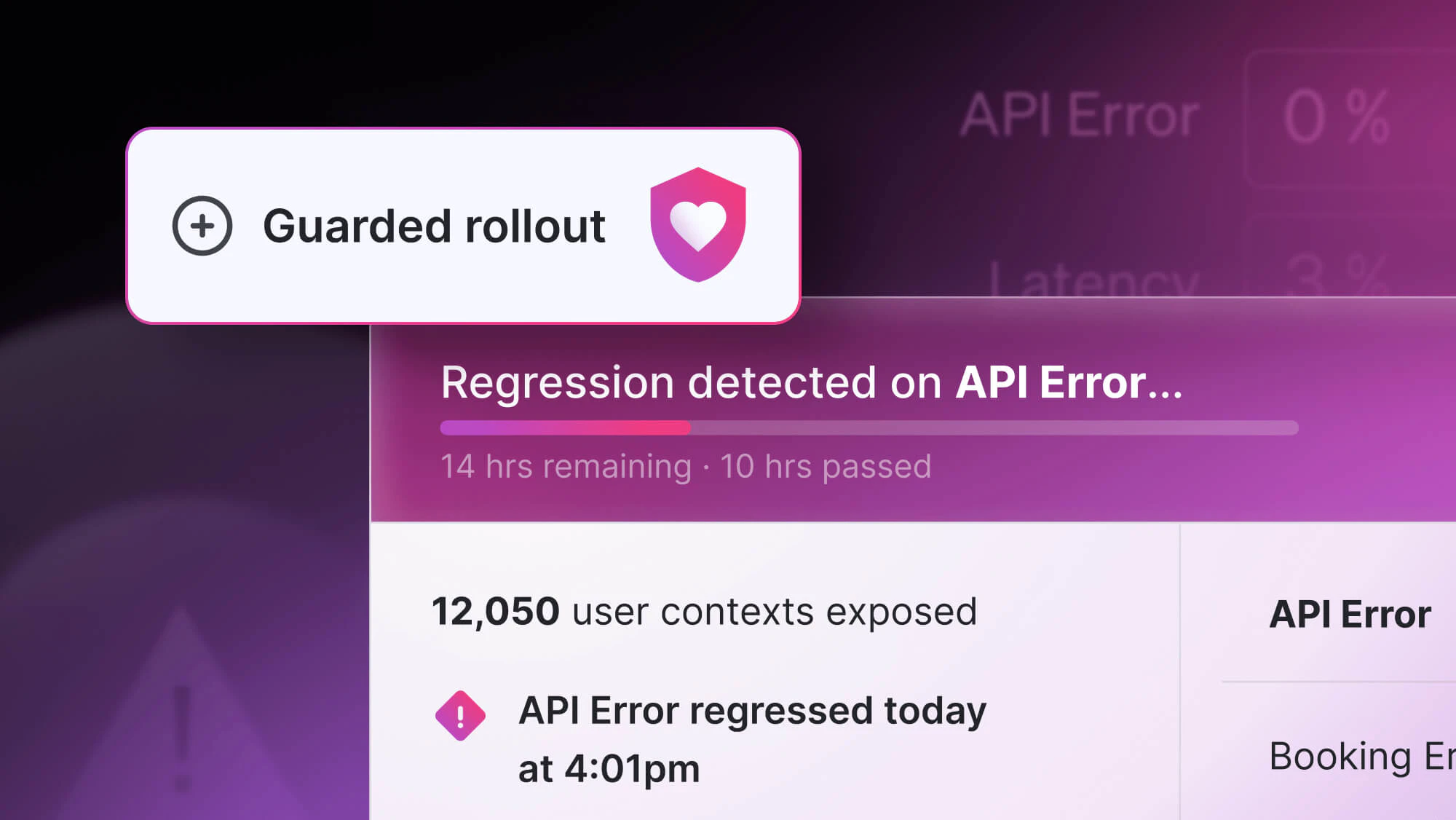
The premise of both is to disable a poorly performing feature. How they go about it is slightly different. A kill switch typically refers to a short-term flag used during a release to turn a feature off if something goes wrong. A circuit breaker is considered a permanent flag and is activated based on an event. For example, a monitoring tool generates an alert when orders fail to complete. The alert toggles a flag that sets the site to 'read-only.'
Operational feature flags use cases
Operational flags can be either short-term or long-term flags. Read about some common use cases below.
Operational interaction testing
You can't always predict how a new microservice or third-party tag will perform. These need to be tested in production to fully see how everything interacts. If the migration does not go as planned or if unexpected interactions are occurring you can use a kill-switch to turn the service off quickly. Flags used for operational interaction testing are short-term flags. Once the service is entirely in production, remove the flag.
API rate limiting
A flood of API requests can make a highly reliable API less reliable. Whether the API requests are coming from a misconfigured endpoint, a misbehaving script, or a DDoS attack, operational flags can help you limit the requests on the fly. You can change the number or types of requests allowed with a long-term operational flag.
Modify logging level
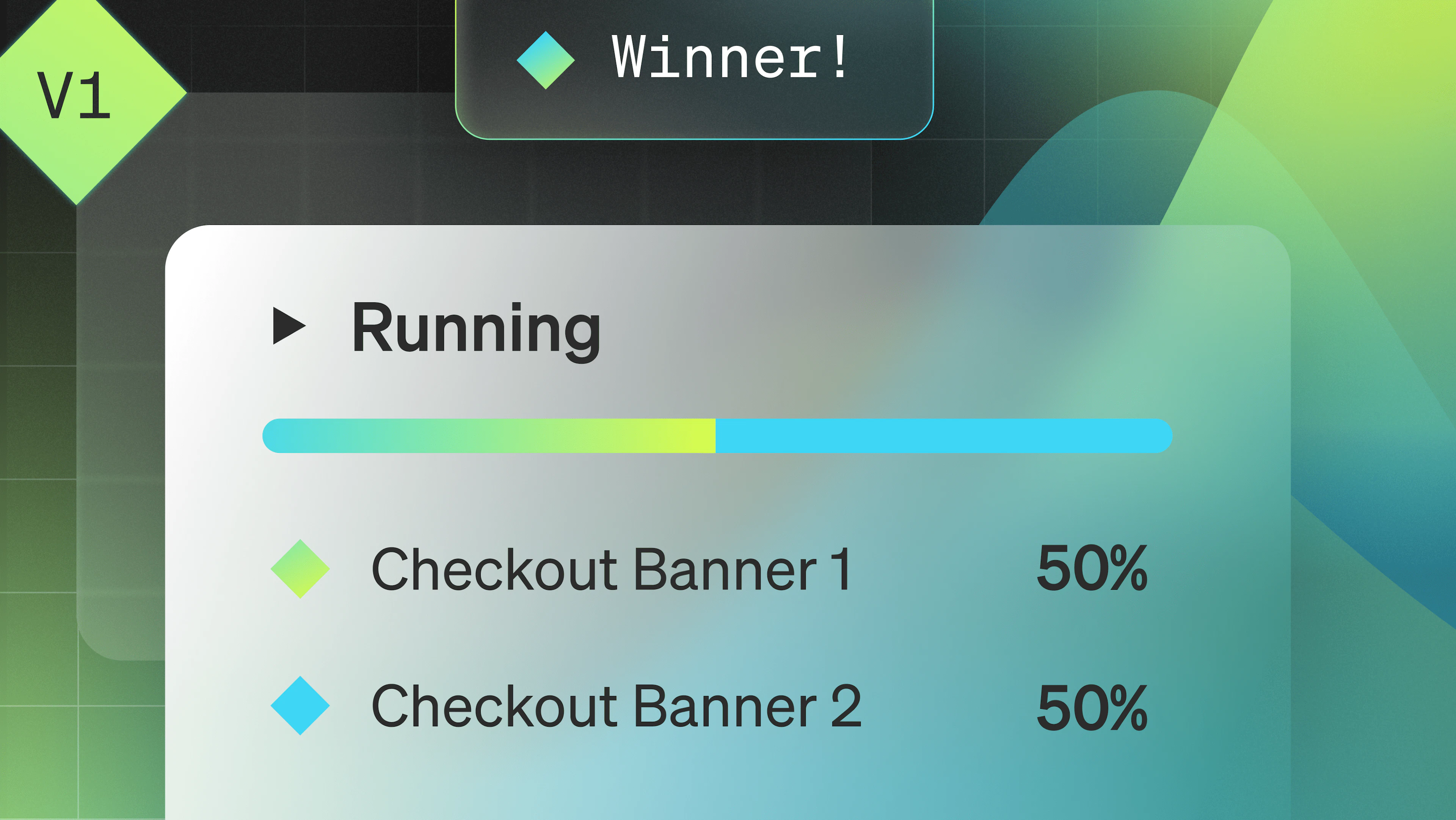
Verbose logs are great for debugging and troubleshooting but always running an application in debug mode is not viable. The amount of log data generated would be overwhelming. Changing logging levels on the fly typically requires changing a configuration file and restarting the application. A multivariate operational flag enables you to change the logging level from WARNING to DEBUG in real-time.
Release management
Releases don't always go smoothly. Some companies use blue-green deployments to maximize good user experience during a release. With a blue-green deployment, there are two nearly identical production environments. One environment is active while the other is idle. A new release is rolled out to the idle environment, and the traffic is cut-over to this environment. If a problem occurs, traffic can quickly be re-routed to the idle environment with the previous version of code.
Blue-green deployments minimize risk with deploys by always having a last-known working configuration available to roll back to if problems occur. That said, one of the challenges of blue-green deployments is all new features and functionality have to be rolled back, not just the feature(s) with issues. Using an operational feature flag as a kill-switch allows you to turn off only the problematic feature while all the other new features remain in production.
The majority of operational flags used for release management should be short-term flags.
Load shedding
Load shedding refers to reducing the load on systems. Non-critical requests are dropped or disabled to make sure that critical tasks complete. When your site is experiencing a traffic spike, turning off some features can help ensure essential tasks complete. If your application is under heavy load, you may need to temporarily disable features that increase latency and stress on the database.
Turning off features that are resource-intensive and you know will not perform optimally under load can circumvent potential problems and a social media backlash. Adding long-term operational flags to turn off non-essential features during times of increased load helps reduce stress on the systems.
Operational feature flags best practices
Consider implementing the following practices when using operational flags.
Document the feature flag
Good documentation is important for permanent operational flags. Accidentally deleting a permanent flag would be a bad thing. Include information on when and why to use the flags in operational and service runbooks. Explain in detail what behavior may change and the impact it may have on your users. Provide information on how to communicate to end-users when toggling features off to eliminate inquiries and complaints that features are missing.
Indicate which feature flags are permanent
A well-defined and documented naming strategy is useful for informing everybody which flags are permanent and which are short-term. We recommend including the following information in a flag name:
- A prefix with a project name or team name.
- Whether the flag is temporary or permanent.
- The creation date of the flag.
Using the above rules if you wanted to create a new permanent operational flag for the comments section, the name might look like this:
opsTeam-comments-widget-permIf you are creating a temporary flag as a temporary kill-switch during a release, the flag name might look like this:
springRelease-comments-widget-temp-June2019In addition to the naming convention, you can also label a flag as permanent from the LaunchDarkly interface.
Control who can change a feature flag
Put processes and controls in place to prevent operational flags from accidentally being flipped or deleted.
Within LaunchDarkly a flag cannot be deleted without confirmation, but that is a partial solution. There are two additional ways to implement access controls for added peace of mind.
Use tags and custom roles to assign permissions to flags within LaunchDarkly quickly.
Set role-based access control (RBAC) to specify who can delete flags in a given environment.
Use a relay proxy
Many operational flags reduce stress on your infrastructure. While not strictly related to operational flags, a relay proxy serves the same function as operational flags.
The LaunchDarkly relay proxy lets several servers connect to a local stream instead of making a large number of outbound connections. If you are concerned about the number of outbound connections from your infrastructure to LaunchDarkly, the relay proxy will drastically reduce the number of concurrent connections.
Are you looking for more best practices? Check out the other blogs in the series.
Feature flagging best practices for short-term and long-term flags