As developers, we try to avoid it, but from time to time, downtime is needed to perform an upgrade or maintenance. Downtime is sometimes needed to upgrade the hardware running an application (or some part of it), change database engines, or to change the data model underlying your application (in cases where the old code can’t understand the new model, and the new code can’t deal with the old model). Other times, you might need to regenerate a derived data model (such as a search index). During these times, all or part of your application may need to be either taken offline, or put into a degraded mode (such as read-only mode).
At LaunchDarkly, we recently needed to reindex the user search feature for all of our customers. Since we have a pretty new product, we didn’t yet have a history of doing this in any particular way. What follows is a description of the problem we faced (and what similar maintenance problems might crop up), and how we solved it.
Types of maintenance modes
Depending on the task, you may need to use different types of maintenance:
- Whole-site maintenance, where you need to take the entire site offline,
perhaps to migrate data structures in your main datastore, or move the site
from one datacenter to another. Of course, this is the most disruptive to
your service, and is the least palatable. - Whole-feature maintenance, where you need to take a portion of your site down entirely, but other parts of the site can remain up. For example, you might need to reindex your search cluster for all content on your site—search will be down during this period, but the rest of the site can remain up. This is better than taking the whole site down, but it does affect all of your users at once.
- Per-user feature maintenance, is when you can perform the maintenance such that it affects only one user at a time. To use the search reindexing example again, perhaps you can reindex just one user’s content at a time. Depending on your project, this may be the least disruptive type of maintenance, since only one user is (partially) down at any given time, and presumably that user is down for a much shorter time that it would take to perform the maintenance for all users. The drawback is that your application and the specific maintenance needs to be structured so that you can perform the task on a per-user basis. This won’t be true in all cases.
What are my options?
Depending on your stack, there might be some existing library that could help:
- There may be a platform-specific option available for you. For Django, there is django-db-tools, which includes a middleware enabling read-only mode. You can think of this as a kind of hybrid whole-site maintenance/whole-feature maintenance, where the ‘feature’ is being able to modify the data, across the whole site. To enable it, you just set an environment variable, and restart the application. Rails has turnout, and in node.js, there is the maintenance package. Both of these work in similar fashions, intercepting all requests, and displaying a maintenance mode page (supporting the whole-site maintenance mode described above). You can also exclude certain paths or source IP addresses so you don’t have to disable the entire site, but you are still disabling entire pages at once.
- You can also switch to maintenance mode at the proxy level, (Heroku offers this, or you can [set something like this up in your own infrastructure). The advantage with this is that there are no code changes necessary, so it might make sense if you need to perform maintenance on the box running your application (since you can take the entire application down). It also makes sense if you are on Heroku since it is so easy. However, this only supports whole-site maintenance, as it takes your entire site out of commission.
- Build your own ‘maintenance mode’ flag into your application, in a configuration property, or database value, etc. I suspect this is the most common option. Lanyrd has a great post about how they put their application into read-only mode to migrate their database. They talk more about the meat of their migration (moving from MySQL to PostgreSQL), but they mention read-only mode as being a critical part of the overall plan. Building your own support for maintenance mode obviously gives you the most flexibility, but it also involves the most work.
How did we do it?
When we needed to reindex our user search feature, we went with a solution that was mostly a ‘build-your-own’ option, because it gave us the most flexibility to only degrade the site as much as was necessary, and no more. This meant that we used the per-user feature maintenance scheme, so that only one user was affected at a time, and that window was much shorter than if we needed to take the feature down for all users, while we reindexed them all.
We dogfood our product all the time, so it didn’t take long to realize that a maintenance mode flag is just a feature flag. (Hopefully this isn’t a case of Maslow’s Hammer, but in hindsight, I think it worked out very well.) First, let’s go over how to think of maintenance mode flags as feature flags (if you don’t use LaunchDarkly, you should still be able to build something similar in-house):
For the simplest type on maintenance, whole-site maintenance, you can check the flag in your top-level request handling code (or whatever is the main entry point in your application). If the flag is on, then display your maintenance page with a 503 status. If the flag is off, then you process the request as usual. (This will give you the same behavior as Turnout in Rails, or the Maintenance module in node.js.) If you are using LaunchDarkly, I suggest creating the feature in with a 100% rollout, but keeping the top-level kill switch turned off.
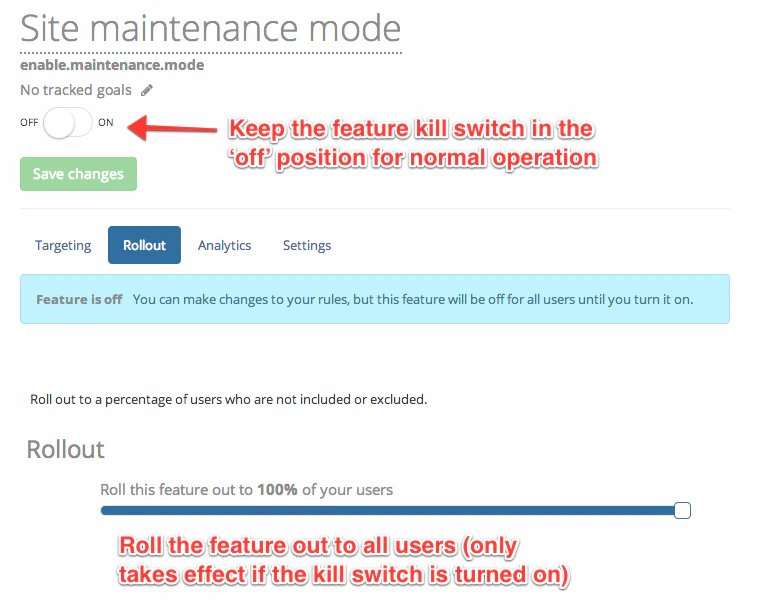
When you need to turn on your maintenance mode, just use the kill switch to activate it, and perform whatever tasks you need to. If you aren’t using LaunchDarkly, you will need to enable maintenance mode in your environment variables or configuration file (for django-db-tools or turnout, respectively), and restart your application. If you are using node.js’s maintenance package, you can enable maintenance mode by hitting a special endpoint, so you don’t need to restart the application. If you are using a custom-built solution, then obviously the mechanism to turn on maintenance mode will vary.
For whole-feature maintenance, the process is essentially the same, except you want to put the feature flag check on the relevant feature in your code. I don’t think this is really possible to do using an out-of-the-box middleware solution like django-db-tools, turnout, or maintenance module, unless you can target the specific feature with a URL pattern. You also might want to have a more specific message displayed to users (eg, explaining that product search is down right now, but the rest of the site is still up). You might want to disable elements throughout your site (like a search box at the top of the page). I will leave it as an exercise to the reader to come up with the ideal user experience in this case.
This means that a custom-integrated solution is needed (either with or without LaunchDarkly). In this case, you would set up the feature in LaunchDarkly in the same way as for whole-site maintenance (with 100% rollout and the kill switch turned off).
For per-user feature maintenance, you will still want to build the feature flag checks into your application as with whole-feature maintenance, but you will need to set up the feature a little differently in LaunchDarkly (or build a more complex system for deciding if a user is in maintenance mode or not, if you are building your own system). For LaunchDarkly in this case, we want the default rollout to be 0%, since we will be explicitly adding users.
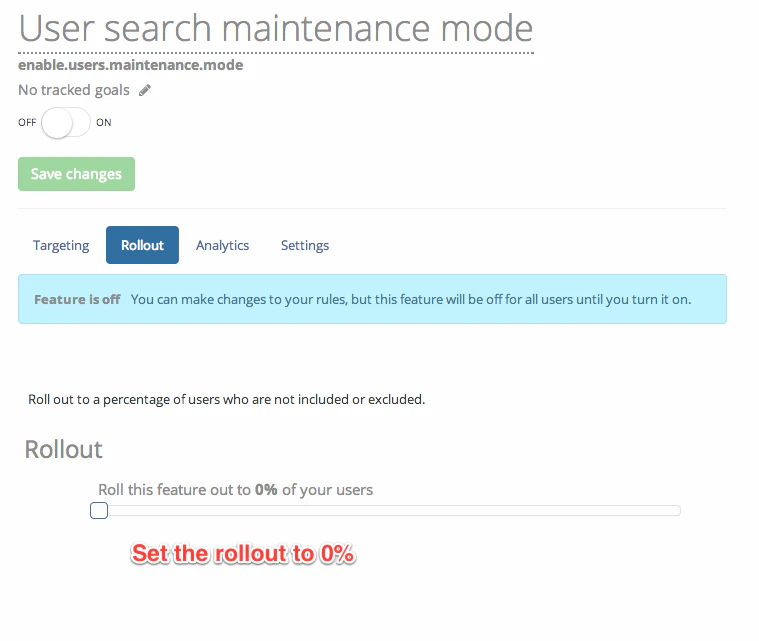
Then, to put an individual user into maintenance mode, just add them to the include list on the ‘targeting’ tab:
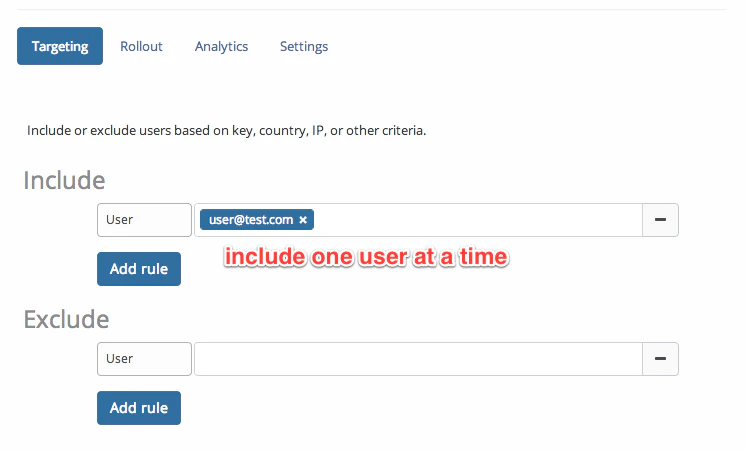
One of the big advantages is that you can toggle the maintenance mode flags without needing to restart the application (or really touch it at all).
Sounds tedious. How can I automate this? (or maintenance is like a monad… I mean like a burrito)
Turning on maintenance mode for one user at a time, performing the maintenance, rinsing and repeating is rather tedious. To help with this, we’ve created a simple shell script that will turn the maintenance mode on and perform some other task.
This script is meant to be the middle layer of a three-layer series of scripts:
– One script to iterate through all of your users, and call the next layer with each one. You need to write this part if you are doing a per-user feature maintenance. If you are not doing per-user feature maintenance, you don’t need this layer.
– This maintenance-mode-guard script.
– The script to do the actual work. If you are doing a per-user feature maintenance operation, then this script should take the user key as a command-line argument (the last argument, in fact). If you are not doing doing a per-user feature maintenance, the of course it doesn’t need to know which user it should operate on. You need to write this script, since it will be specific to your application.
For example, suppose you wanted to reindex all products in your application (so you are using a whole-feature maintenance scheme):
maintenance-mode-wrapper.sh -a LD_API_KEY -f 'maintenance.mode.flag'
/path/to/maintenance-function --param 1 --param2 etcIn this example, you just specify your LaunchDarkly API key and the feature flag key that guards the feature you are performing maintenance on (this can be either a whole-feature maintenance flag or a whole-site maintenance flag). The script will turn on the maintenance mode flag, call your maintenance script (/path/to/maintenance-function --param 1 --param2 etc in this example), and then turn off maintenance mode. If something goes wrong with the maintenance script (as detected by a non-zero return code), then a message will be printed to standard output, and maintenance mode will be left on. You can then investigate and correct the problem, and turn off maintenance mode yourself. (If something goes wrong when turning on maintenance mode, like an invalid API key or feature key, then a message will be printed, and your maintenance script will not be called.)
Next, let’s look at an example of a per-user feature maintenance operation:
/path/to/user-enumeration-script |\
while read user; do
maintenance-mode-guard.sh -a $LD_API_KEY -f 'user.feature.maintenance.mode.flag'
-u $user /path/to/user-maintenance-function --param 1 --param2 --user
if [ $? -ne 0 ]; then
exit 1
fi
doneThere is a bit going on here, so let’s dissect it:
- /path/to/user-enumeration-script |\ is meant to be a script (or command) that you write that will enumerate user keys, one per line. This output is then piped to the while loop.
- while read user; do reads the user keys, one line at a time, executing the while block once per user. The user key is assigned to the $user variable.
- The next line can be further dissected
undefinedundefined - if [ $? -ne 0 ]; then ... the rest of the block just checks the return code from the single-user maintenance operation, and halts if something went wrong. This way, the last user is still in maintenance mode, and you can investigate.
A word about TTL values
In general, you want to have non-zero TTL values on your features to avoid external network calls, especially for such critical paths like you would use for a whole-site maintenance flag. However, when you are in maintenance, especially if you are rapidly changing which users are in maintenance mode, you will probably want to pay the (still minor) cost of a network call to the LaunchDarkly server to get the latest version of your feature. I’d suggest the following:
- Under normal operation (ie, non-maintenance windows) keep the TTL high, like 5 minutes.
- 5 minutes before you are ready to start maintenance, log into LaunchDarkly and turn the TTL for the maintenance feature flag you will be using to 0. The important thing is to do this in advance of the maintenance, so all of your servers will be sure to have expired the long-TTL feature from their respective caches, and start making live network calls on every flag request, before you begin maintenance.
– After maintenance is complete, set the TTL back to 5.
– You can use a value even larger than 5 if you want.