Autogenerated metrics
Overview
This topic explains the metrics LaunchDarkly automatically generates from SDK events and how you can use them to monitor the health of your applications.
Metric events
An “event” happens when someone takes an action in your app, such as clicking on a button, or when a system takes an action, such as loading a page. Your SDKs send these metric events to LaunchDarkly, where, for certain event kinds, LaunchDarkly can automatically create metrics from those events. You can use these metrics with experiments and guarded rollouts to track how your flag changes affect your customers’ behavior.
LaunchDarkly autogenerates metrics:
- from events sent from AI SDKs used in conjunction with AI Configs
- from events sent from telemetry integrations, such as the JavaScript telemetry integration used in conjunction with JavaScript-based client-side SDKs
- from events sent as part of OpenTelemetry traces using the OpenTelemetry feature for server-side SDKs
Autogenerated metrics are marked on the Metrics list with an autogenerated tag. You can view the events that autogenerated these metrics from the Metrics list by clicking View, then Events.
Randomization units for autogenerated metrics
LaunchDarkly sets the randomization unit for autogenerated metrics to your account’s default context kind for experiments. For most accounts, the default context kind for experiments is user. However, you may have updated your default context kind to account, device, or some other context kind you use in experiments most often. To learn how to change the default context kind for experiments, read Map randomization units to context kinds.
All autogenerated metrics are designed to work with a randomization unit of either user or request. Depending on your account’s default context kind for experiments, you may need to manually update the randomization unit for autogenerated metrics as needed. The recommended randomization units for each autogenerated metric are listed in the tables below. To learn how to manually update the randomization unit for a metric, read Edit metrics.
Metrics autogenerated from AI SDK events
An AI Config is a resource that you create in LaunchDarkly and then use to customize, test, and roll out new large language models (LLMs) within your generative AI applications. As soon as you start using AI Configs in your application, you can track how your AI model generation is performing, and your AI SDKs begin sending events to LaunchDarkly.
AI SDK events are prefixed with $ld:ai and LaunchDarkly automatically generates metrics from these events.
Some events generate multiple metrics that measure different aspects of the same event. For example, the $ld:ai:feedback:user:positive event generates a metric that measures the average number of positive feedback events per user, and a metric that measures the percentage of users that generated positive feedback.
This table explains the metrics that LaunchDarkly autogenerates from AI SDK events:
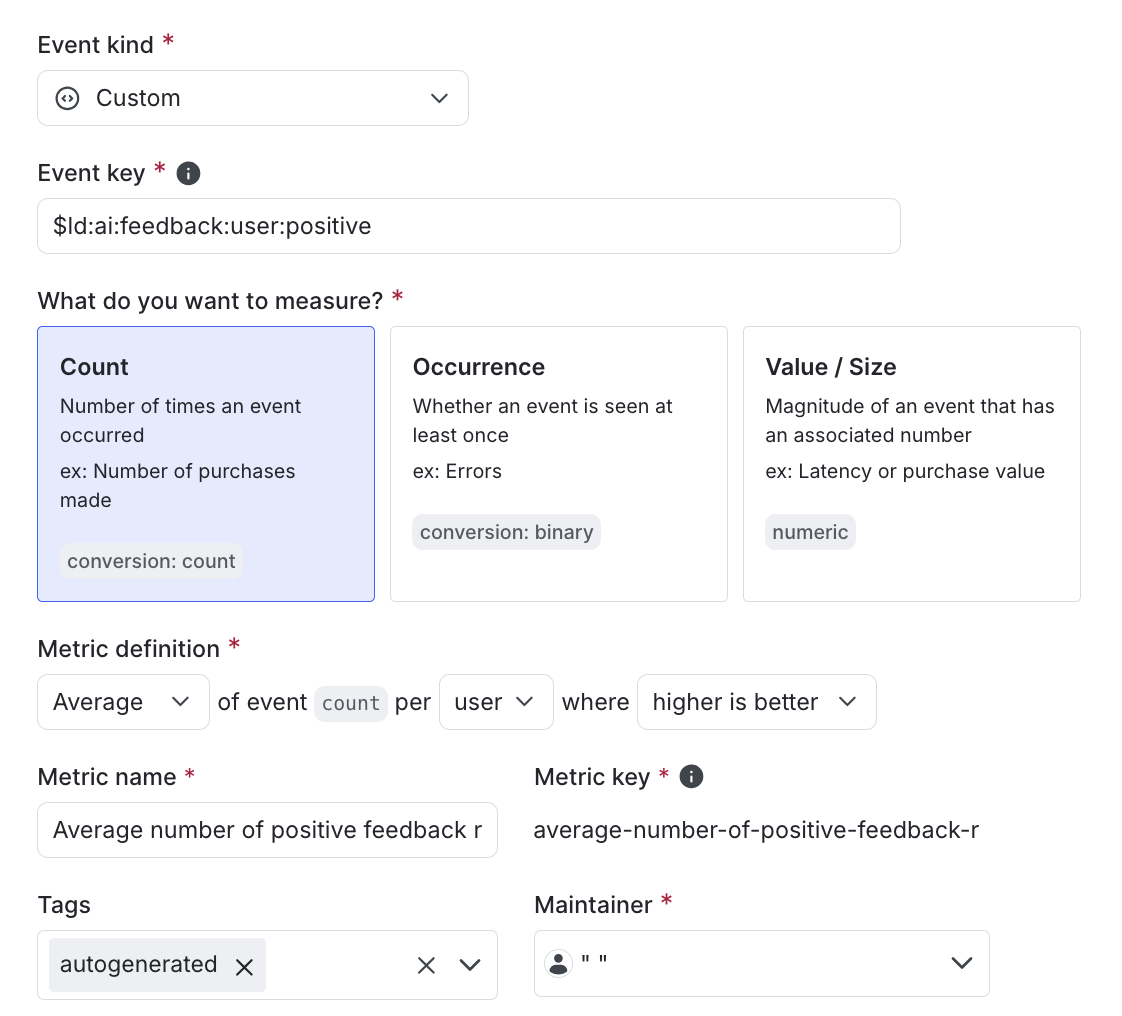
Example: Average number of positive feedback ratings per user
The autogenerated metric in the first row of the above table tracks the average number of positive feedback ratings per user.
Here is what the metric setup looks like in the LaunchDarkly user interface:
Metrics autogenerated from telemetry integration events
The LaunchDarkly telemetry integrations provide error monitoring and metric collection. Each telemetry integration is a separate package, which you install in addition to the LaunchDarkly SDK. After you initialize the telemetry integration, you register the LaunchDarkly SDK client with the telemetry instance. The instance collects and sends telemetry data to LaunchDarkly, where you can review metrics, events, and errors from your application.
Telemetry integration events are prefixed with $ld:telemetry and LaunchDarkly automatically generates metrics from these events.
This table explains the metrics that LaunchDarkly autogenerates from events recorded by the telemetry integration for LaunchDarkly browser SDKs:
Metrics autogenerated from server-side SDKs using OpenTelemetry
LaunchDarkly’s SDKs support instrumentation for OpenTelemetry traces. Traces provide an overview of how your application handles requests. For example, traces may show that a particular feature flag was evaluated for a particular context as part of a given HTTP request. To learn more, read OpenTelemetry and Sending OpenTelemetry traces to LaunchDarkly.
OpenTelemetry events are prefixed with otel and LaunchDarkly automatically generates metrics from these events.
This table explains the metrics that LaunchDarkly autogenerates from OpenTelemetry traces: