





Most engineering teams report having runtime safety mechanisms in place. According to the LaunchDarkly 2026 AI Control Gap Report, 99% of surveyed software organizations use some form of delivery guardrail during or after feature rollout, such as feature flags, progressive rollouts, observability tooling, or kill switches.
Despite this widespread adoption, incidents are still common. 69% of teams roll back or hotfix production issues at least once a week. 40% have knowingly shipped risky changes once or twice in the last 6 months, while 42% report having done so multiple times. Only 9% say they have consistently avoided this issue altogether.
Guardrails are present, but they don’t guarantee successful deployments. Some teams assume that guardrails exist to prevent incidents, but prevention is not their core purpose. Failure is inevitable in complex systems. Good guardrails help teams reduce the impact when things go wrong. They contain the blast radius, speed up response time, and provide a way to manage risk in real-world conditions. When guardrails are built into the delivery process and—most importantly—used consistently, they help teams recover quickly without slowing down. When they are used inconsistently or added too late, they provide little protection. Guardrails do not eliminate failure, but they make it safer to move fast.
Some teams have made guardrails part of their daily workflow. They ship quickly, catch issues early, and spend less time on recovery. This post looks at why that’s still uncommon, and what gets in the way for most teams.
Why guardrails alone aren’t enough
Most teams have the essential tools in place. In the same report, 72% of respondents say they use feature flags. 64% rely on real-time monitoring, and 62% say they employ progressive rollouts. On paper, these capabilities should prevent high-blast-radius failures and reduce mean time to recovery.
In practice, the systems often lack coordination, integration, or enforcement. They are used inconsistently, applied manually, or introduced late in the development cycle. For many teams, these controls exist more as options than defaults.
Several contributing factors emerge:
- Fragmented tooling. Many teams use different flagging systems or custom rollout logic across services. This increases cognitive overhead and reduces reliability during high-pressure scenarios.
- Inconsistent practices. Guardrails may be available but not applied consistently across teams, environments, or release types.
- Limited observability. Monitoring exists, but it is often not directly tied to feature states, rollout phases, or user cohorts.
- Manual intervention. Rollouts and rollbacks are often reactive. Kill switches exist but may require manual changes, code pushes, or cross-tool coordination.
The result is a fragile safety net. Capabilities are present, but not operationalized in a way that reduces actual risk.
AI increases the pressure to deliver
Guardrails are most valuable during periods of rapid change or uncertainty. These are also the moments when teams are most likely to bypass them. 81% of respondents reported shipping changes with unresolved risks due to pressure to deliver. That pressure grows as AI tools accelerate how quickly teams generate code and how often they’re expected to ship it. Teams face mounting pressure to keep up with roadmap targets, respond to market shifts, and launch AI-powered features that are often still being tested in production.
In these cases, speed overrides process. Rollout best practices are skipped. Validation is reduced to smoke testing. Flags are toggled broadly or turned on without progressive exposure.
In these moments, teams tend to fall back on whatever is easiest. If guardrails are not deeply integrated into the release workflow, they are often ignored. The tradeoff is familiar: short-term speed, long-term risk.
This pattern plays out across organizations of different sizes. In mid-sized orgs with 11 to 20 delivery teams, deployment frequency is high—75% ship daily—but only 22% keep incidents to a monthly cadence or lower.
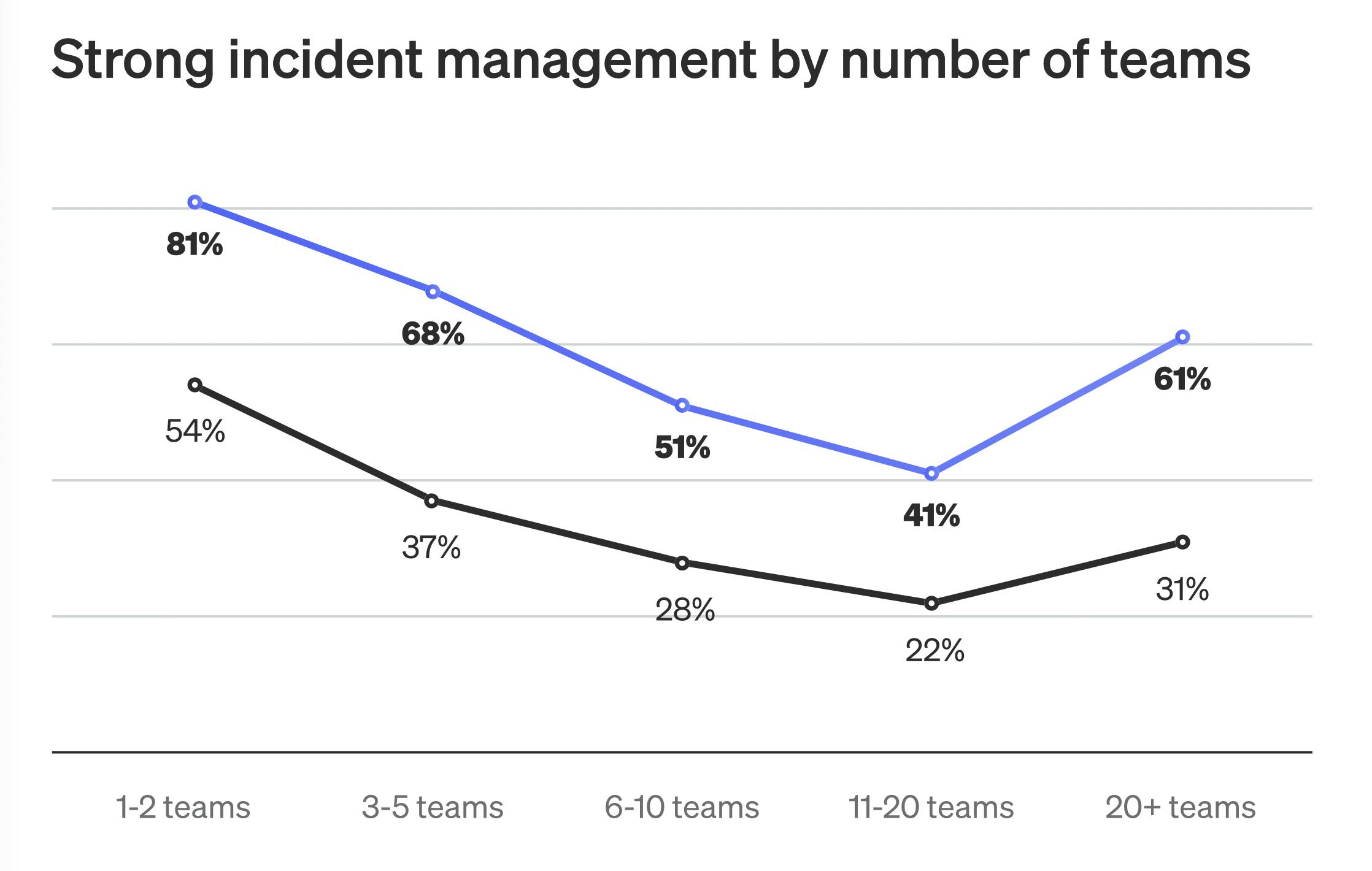
Safety requires consistent day-to-day usage
The presence of guardrails is not always a reliable predictor of safety outcomes. The deciding factor is how those guardrails are implemented and maintained. In teams that deploy safely and recover quickly, guardrails are treated as part of the delivery infrastructure, not as optional tools.
High-performing teams share a few common patterns:
- Feature flags are used consistently across all services, including backend, frontend, and infrastructure components
- Rollout rules are predefined, peer-reviewed, and enforced across environments
- Monitoring and alerting are tied to flag states and user targeting, not just service-level metrics
- Rollbacks are automated or near-instant, and do not require a redeploy
These practices can reduce the time required to diagnose and resolve failures, but they don’t slow down delivery. Teams that use guardrails effectively can maintain production velocity because safety is built into the process rather than added on after the fact. As expectations for faster releases grow, the goal is not to move more slowly, but to move with more control.
Only 15% of teams cited in the report achieve the benchmark of deploying daily or more while experiencing incidents no more than once a month. Among surveyed LaunchDarkly users, that number is more than twice as high. These teams spend less time on incident remediation and more time building. 71% of LaunchDarkly users spend at least 25% of their time on feature development, compared to just 56% for those using other platforms.
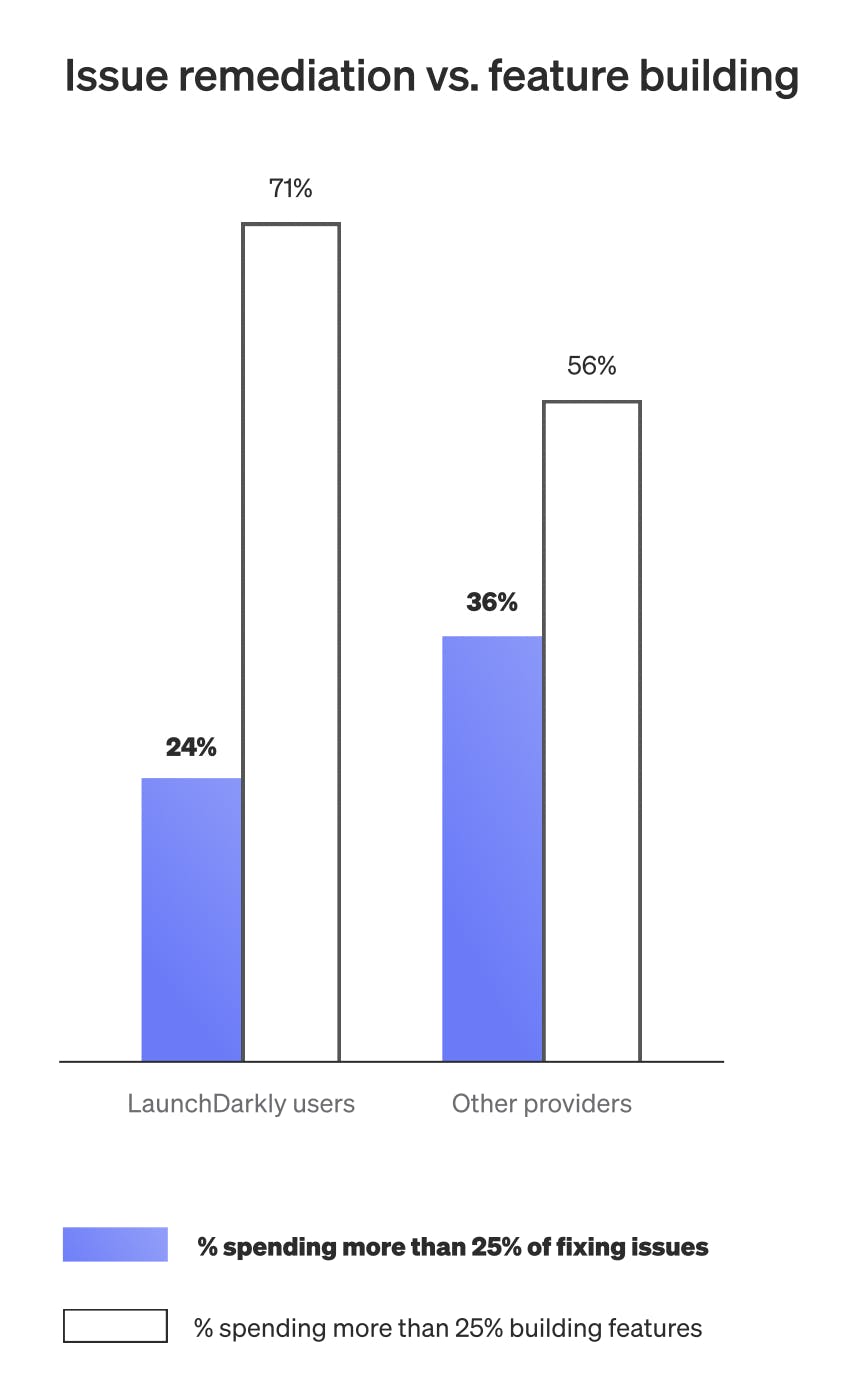
The goal of guardrails: embed control and reduce variance
Closing the gap between the presence of guardrails and their actual effectiveness requires operational maturity and consistency. Teams must treat runtime controls as part of the core release lifecycle, not as reactive mechanisms.
Doing this includes:
- Automating rollouts and rollback patterns so they are not reliant on manual execution
- Connecting observability data to the state of features, flags, and cohorts
- Defining governance standards for how and when to apply safety mechanisms
- Reducing the operational burden of rollout tooling so usage becomes the default behavior
When these practices are in place, guardrails deliver on their promise. Releases become more predictable. Incidents are easier to isolate and recover from. Developers regain confidence in shipping regularly, even in high-risk contexts like AI-enabled applications.
Most teams are equipped to prevent incidents, but until they consistently operationalize guardrails, incidents will continue. The technical challenge is to first install the right systems—and then to make them usable, standardized, and automatic. For more insights, download the AI Control Gap Report.