
Even the best development teams can get bogged down by complex branching strategies, merge conflicts, and slow release cycles. Fortunately, there's a solution: trunk-based development.
Trunk-based development can streamline workflows, boost productivity, and help you ship features faster. Below, we'll explore what trunk-based development is, its benefits, and how you can start implementing it in your team.
What is trunk-based development?
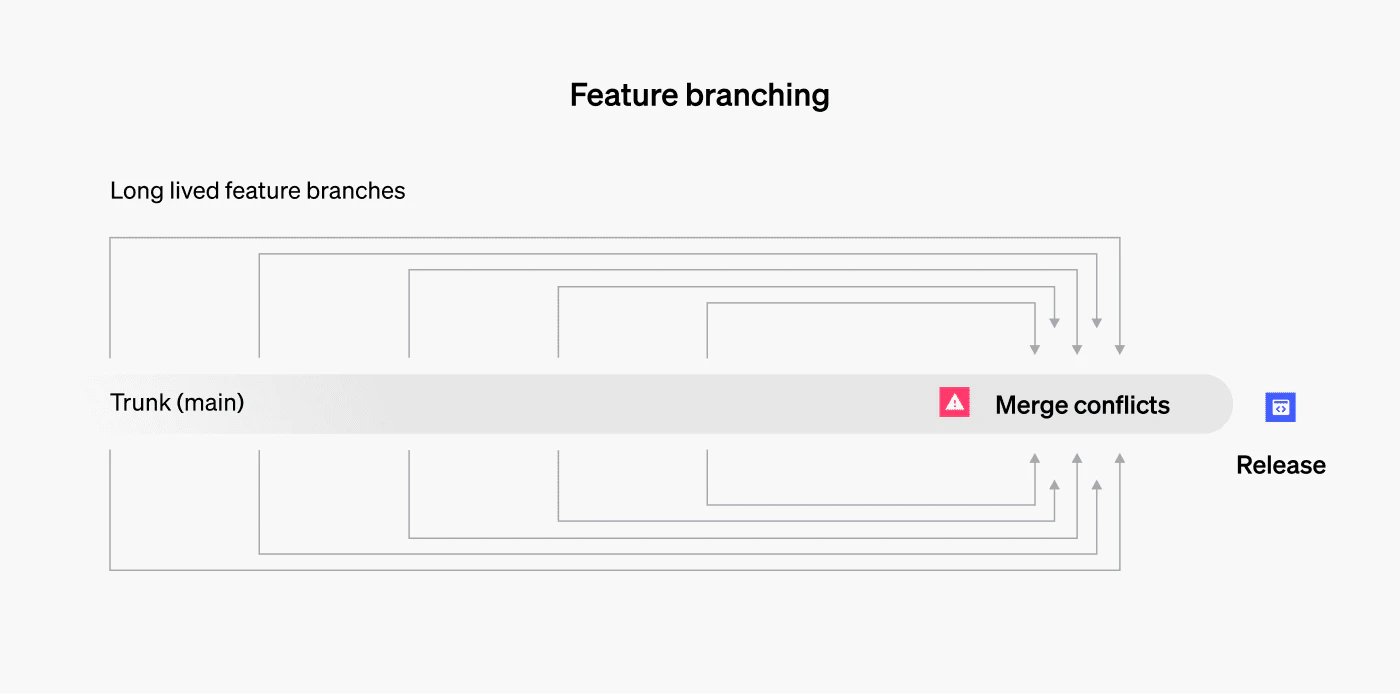
Trunk-based development is a version control management strategy that simplifies the development process by eliminating long-lived feature branches. Instead of maintaining multiple complex branches, developers work primarily on a single branch called the "trunk" (also known as "main" or "master").
In this approach, developers:
- Make frequent, small commits directly to the main branch
- Use short-lived feature branches that are quickly merged back to the trunk
- Employ feature flags to control the visibility of new or incomplete features
This method contrasts with traditional feature branching or GitFlow strategies, which often involve multiple long-lived branches (like development, QA, release-candidate, and release branches).
A trunk-based development flow is simple. There are only two primary sources of branches:
The trunk branch (hence the name of the branching strategy). This is the branch that’s deployed to any integration environments—the branch that’s deployed to production, the one that’s deployed to user acceptance environments.
Feature branches for new work or bug fixes. These branches are just like the feature-branch development branches. This is where developers make changes. When they’re done, they create a pull request to the trunk branch.
Here's how it works:
- Developer creates a short-lived branch from trunk for a bug fix or feature.
- After making changes, developer creates a pull request to merge back into trunk.
- Code is reviewed and approved by another developer.
- Changes are merged into trunk and verified in an integration environment.
- Code progresses through QA and user acceptance environments using tags.
- Once verified, the tagged changes are promoted to production.
- An automated system deploys the new code to production.
This streamlined process reduces complexity and allows for faster, more frequent deployments while maintaining quality control.
The benefits of trunk-based development
The ‘lead time for changes’ is much shorter in a trunk-based development strategy, but that’s not the only advantage. Let’s run through the benefits of adopting a trunk-based strategy.
- Short-lived branches: Developers work with a single touchpoint (the trunk), reducing overhead and minimizing friction in the pull request process. This streamlines the flow from writing code to delivering it to customers.
- Fewer merge conflicts: With only one main branch, the potential for conflicts is significantly reduced. This minimizes the risk of human error during conflict resolution, which can introduce bugs or accidentally delete features.
- Quicker releases: Trunk-based development facilitates Continuous Integration and Continuous Delivery (CI/CD), enabling faster shipping of new changes to production. According to the DevOps Research and Assessment (DORA) group, teams that reduce the time between writing and shipping code tend to build more features that customers love, ship fewer bugs, and increase their development velocity
- Improved productivity: By avoiding "merge hell" and reducing the complexity of branch management, developers can focus more on writing and improving code.
- Better code quality: Frequent integrations and shorter feedback loops help catch and resolve issues earlier in the development process.
How to get started with trunk-based development
Transitioning to trunk-based development isn't an overnight process, but it's worth the investment. Here's a quick step-by-step guide to help you get started:
- Strengthen your testing infrastructure: Implement comprehensive automated testing (unit, integration, and end-to-end tests). Set up continuous integration to run tests on every commit.
- Implement feature flags: Use feature flags to hide incomplete features in production. This allows integration of work-in-progress code without affecting users.
- Start small: Begin with a pilot project or a subset of your team. Gradually expand as you gain experience and confidence.
- Shorten your release cycle: Aim for smaller, more frequent releases. This reduces the risk associated with each deployment.
- Improve code review processes: Implement pair programming or more frequent code reviews. This helps catch issues early and spreads knowledge across the team.
- Monitor and adjust: Keep track of metrics like deployment frequency and lead time for changes. Use this data to continuously improve your processes.
- Invest in developer tools: Provide tools that make it easier for developers to work with the trunk. This might include advanced IDEs, merge tools, and feature flag management systems (like LaunchDarkly).
Trunk-based development enables DevOps and unlocks team potential
There’s a lot more to learn about trunk-based development. If you want to explore the subject further, I recommend checking out the Trunk Based Development homepage.
As you explore, remember that one of the key tenets of trunk-based development (and the DevOps workflow that inspired it) is that of incremental improvement. Your goal shouldn’t be to jump in with both feet but instead to get a little better every day.
One of the ways you can do that is by exploring feature flagging for your application, no matter your workflow. See how LaunchDarkly can enable your team to engage in trunk-based development and dramatically increase their productivity.
Request a demo of the LaunchDarkly Feature Management Platform.


















