
Key Takeaways
- Learn the benefits and shortcomings of several common Git branching strategies.
- Get an overview of trunk-based development and understand its advantages over feature branching.
- Learn how to unlock trunk-based development with feature flags.
What is a branching strategy?
A “branching strategy” refers to the strategy a software development team employs when writing, merging, and shipping code in the context of a version control system like Git. Software developers working as a team on the same codebase must share their changes with each other. But how can they do this efficiently while avoiding malfunctions in their application? The goal of any branching strategy is to solve that problem and to enable teams to work together on the same source code without trampling on each other. A branching strategy defines how a team uses branches to achieve this level of concurrent development.
This article will first review the benefits and shortcomings of several common Git branching strategies. Then, we’ll compare those to trunk-based development to learn how the latter solves those shortcomings and enables modern software delivery practices through feature flag management.
Why you need a branching strategy
A branching strategy ensures everyone on the team is following the same process for making changes to source control. The right strategy enhances collaboration, efficiency, and accuracy in the software delivery process, while the wrong strategy (or no strategy) leads to hours of lost effort.
Here are some common use cases to consider when devising a branching strategy.
Typical development workflow
The typical day-to-day flow includes normal changes that developers make to the code, changes that do not bring any heightened sense of urgency. These changes are ordinary in terms of size and complexity for your codebase and, generally, will make up the bulk of all the changes your developers make. Since this flow will be used the most frequently, your strategy here must ensure proper coordination among the developers and support all relevant policies such as automated testing, pull requests, and deployments.
Emergency hotfixes
An emergency hotfix is when a particular incident or issue has been expedited to deal with some emergent situation, normally bug fixes. Your flow must account for a developer who needs to make an urgent change and get it all the way through your process and into production while still aligning with your typical development workflow.
Small vs. large changes
As the industry has evolved, the emphasis on developers working on smaller changes and limited batch sizes has increased due to broader use of flow-based delivery practices. However, there are still times when you must make large, complex changes, and your branching strategy must accommodate those situations.
Standard vs. experimental changes
Developers feel greater certainty about how standard code changes will perform than with experimental code changes. For example, if you’re evaluating a new library or framework, you may feel uncertain about how well it integrates with your codebase. In that case, your change may or may not actually go to production but still needs to be shared with other developers. Your branching strategy must account for these types of experimental changes.
Git branching
How Git handles branches
In Git, all branches are simply tags or pointers. Unlike other source control systems, Git doesn’t create copies of files to track changes. Instead, Git tracks all changes as a directed acyclic graph where each node is a set of changes made at one time. Any such node can be a branch, which allows changes to diverge from other parts of the tree. A merge simply modifies the Git object graph without any file-system impacts as in other source control systems. As such, branches in Git are very lightweight to create and manage.
Common types of branches
Trunk branch
Every Git repository has a trunk (also referred to as main, mainline, or the master branch). When a Git repository is created, the trunk exists automatically as the implicit first branch. The use of a trunk and the timing of changes landing on it vary depending on the exact branching strategy being used. In trunk-based development, the trunk is the central branch to which all developers send their code changes.
Development branch
The development branch is a long-lived feature branch that holds changes made by developers before they’re ready to go to production. It parallels the trunk and is never removed. Some teams have the development branch correspond with a non-production environment. As such, commits to the development branch trigger test environment deployments. Development and trunk are frequently bidirectionally integrated, and it’s typical for a team member to bear the responsibility of integrating them.
Feature branch
A feature branch can be short- or long-lived depending on the specific branching flow. The branch often is used by a single developer for only their changes, but it is possible to share it with other developers as well. Again, the branching strategy will determine how exactly you define a “feature branch”.
Release branch
A release branch can be either short-lived or long-lived depending on the strategy. In either case, the release branch reflects a set of changes that are intended to go through the production release process.
Hotfix branch
A hotfix branch is a branch that’s used generally to hold changes related to emergency bug fixes. They can be short-lived or long-lived, though generally they exist as long-lived branches split off from a release branch. They tend to be more common in teams with explicitly versioned products, such as installed applications.
Merge conflicts and pain
It’s easy for development teams to find themselves with a tangled mess of branches that need to be merged with the mainline all at once. And the longer multiple developers keep their code changes from mixing with each other, the higher the risk that those changes will conflict (through changes to common code).
It’s changes to common code that prevent Git from handling merges automatically and cause developers to experience the classic horrors of source control management: merge conflicts that waste time, lost changes that vanish entirely, and regression defects from removed code that somehow finds its way back in. Part of why trunk-based development has grown in popularity is because it helps avoid these painful merge conflicts. We’ll unpack trunk-based development in greater detail later.
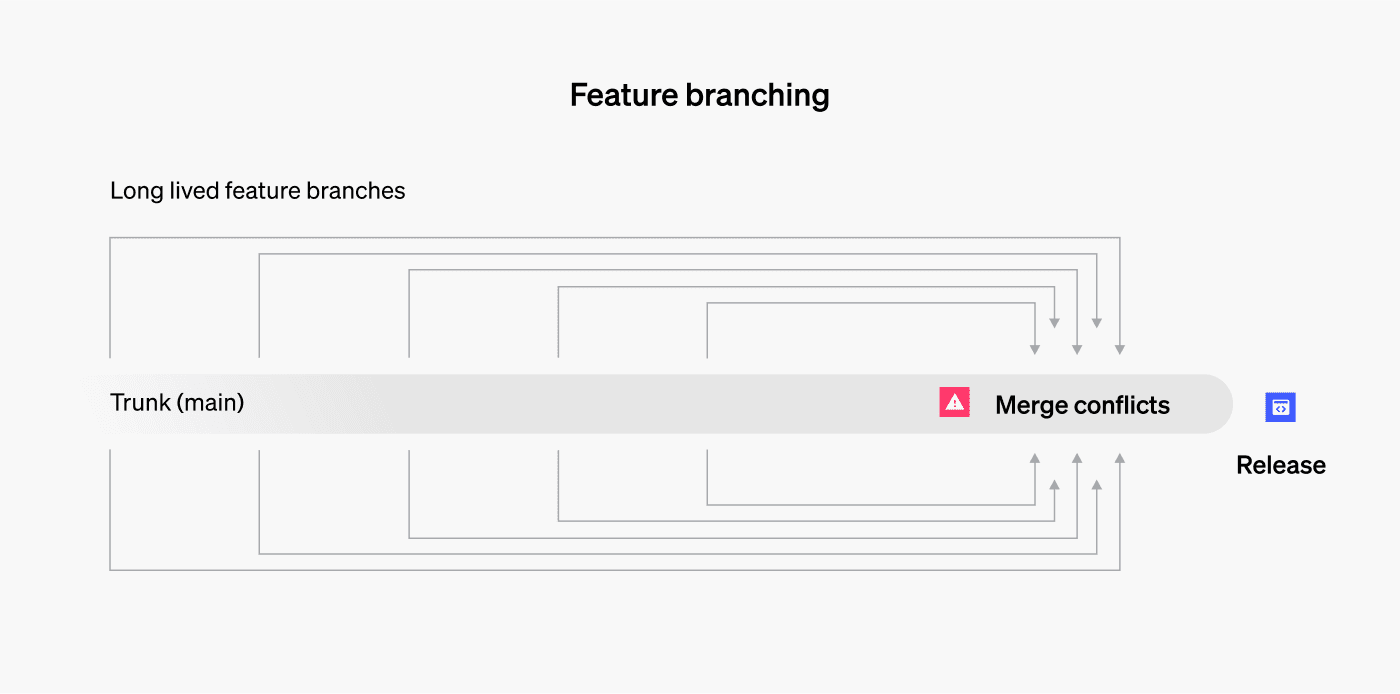
Popular branching flows
GitFlow
GitFlow was introduced by Vincent Driessen in 2010 to share insight into the use of Git for source control as its use became more widespread. GitFlow relies on essentially every type of branch that was discussed previously with the bulk of the development workflow centering on the long-lived development branch as a shared integration branch for all the developers. The trunk, in this case, essentially reflects a history of all the changes that have gone to production.
Pros and cons of GitFlow
GitFlow made it very easy for developers new to Git to learn and apply its branching model to become productive quickly. In that sense, GitFlow was a great step forward. Unfortunately, as the industry has evolved, some of GitFlow’s underlying flaws have been exposed. The sheer volume of branches, especially long-lived branches, is a large maintenance headache for a team.
A team without the proper discipline to keep feature branches small and short-lived will experience considerable challenges in merging into the development branch, with each subsequent developer having to deal with more and more potential merge conflicts. Additionally, the level of effort needed to maintain the branches adds overhead to the team. In 2020, Driessen himself suggested as an addendum to his original post that GitHub Flow was likely a much better starting point for most software teams today than GitFlow due to the surge in web-delivered software as a service instead of installed software.
GitHub Flow
GitHub Flow was popularized by GitHub as a simpler alternative to GitFlow. It calls for the following workflow:
- Trunk is always releasable, and in fact, releases are generally done directly from it.
- Each developer creates a new branch, the feature branch, for their changes from trunk.
- Feature branches can be deployed to a testing environment for verification or pushed directly to trunk and deployed to a non-production environment from there.
- A short-lived release branch may be used off trunk to prepare for and execute a release.
Pros and cons of GitHub Flow
Because GitHub Flow treats every change as a feature branch, it has considerably fewer moving parts than GitFlow. The only long-lived branch is trunk, so branch maintenance is far less of a burden. However, an undisciplined team that has feature branches open for several days can still run into merge troubles, and now, those troubles will directly impact the trunk. A bad merge on trunk can leave it in an undeployable state, which is a big no-no in this flow.
Challenges
Both of these branching strategies can work for the right environment, but they have similar downsides. The biggest downside is neither flow adequately supports Continuous Integration. And Continuous Integration is becoming an essential modern development practice. By relying on feature branches, it’s too easy to focus on the benefits of change isolation and ignore the costs. Instead, a better strategy would support Continuous Integration, wherein developers integrate code regularly (i.e., at least every day). Fortunately, there is a branching strategy able to meet all these needs: trunk-based development.
Trunk-based development
Trunk-based development (TBD) is a branching strategy where all developers integrate their changes directly to a shared trunk every day, a shared trunk that is always in a releasable state. No matter what a developer might do on their local repository, at least once each day, they must integrate their code. This practice forces each developer to regularly see and react to the changes being made by their teammates in version control, which drives collaboration around the quality and state of the codebase as a near-constant activity.
TBD allows for the use of other branches, such as a short-lived release branch off the trunk for executing a release and local-only feature branches, but neither are required to practice TBD. As Continuous Delivery and DevOps have become increasingly prominent and even necessary for many software development teams, TBD has the tightest alignment with those modern delivery approaches. In fact, trunk-based development is a prerequisite for CI/CD.
Benefits of trunk-based development over feature branching
True Continuous Integration
TBD puts continuous integration front and center in a developer’s workflow. There’s really no way to avoid it without breaking the team’s policy on using TBD. You simply must integrate your changes every day; realizing that instantly makes you think differently about how you approach your work and your collaboration with your team members. And continuously integrating code changes is essential to innovating at a faster pace.
Small changes
Integrating changes every day means that you must take small steps forward. You cannot start your work by making a sweeping set of changes in a lot of code files that breaks your local compilation. Instead, you must see your work as a series of small steps forward where each step could be released to production. By implementing smaller changes, you limit the blast radius of any changes that cause a problem in production.
Branch by abstraction
For most developers, the previous two concepts make sense and generally are hard to argue with. In practice, though, it becomes challenging when a new feature is simply too big to be done in one day. At that point, the need to integrate changes seems impossible. The TBD solution is “branch by abstraction”, a practice to help developers continue to make and integrate small changes every day even if the overall feature still takes several days to complete.
In trunk-based development, first, you’ll identify the areas where you need to make some changes. Next, you’ll find the point in the code where you can toggle over to different logic. Then, you’ll introduce a new component or interface to establish a seam to capture your changes. As you integrate your changes with trunk, your new code will be integrated to the shared trunk in version control (and could even be deployed), but you haven’t yet wired the code into the working system so it’s not actually being used. Ultimately, when all your changes are completed, you’d wire in your new components and remove the old components. This technique is called branching by abstraction: you rely on a source code abstraction to achieve the effect of a branch without an actual version control branch.
Feature flags
As you become comfortable with branch by abstraction, you’ll realize that sometimes you do want your code changes to be deployed. For example, you may want your changes to go to a non-production environment for verification, but not yet be visible in production. Or maybe you want a limited set of users to see your changes in production (e.g., in a canary launch) but not the entire customer base. You could achieve this with branch by abstraction, but attempting to control environmental configuration in source control is both a mismatch and inflexible.
Instead, feature flags allow you to wire your branch by abstraction to an externally controllable mechanism, such as an application configuration file or even an external database or service. This gives more control over releasing your change outside the codebase itself. Feature flags allow developers to deploy unfinished code to production while hiding it from end-users. Feature flags thus reduce risk when doing trunk-based development.
How feature flags enable trunk-based development
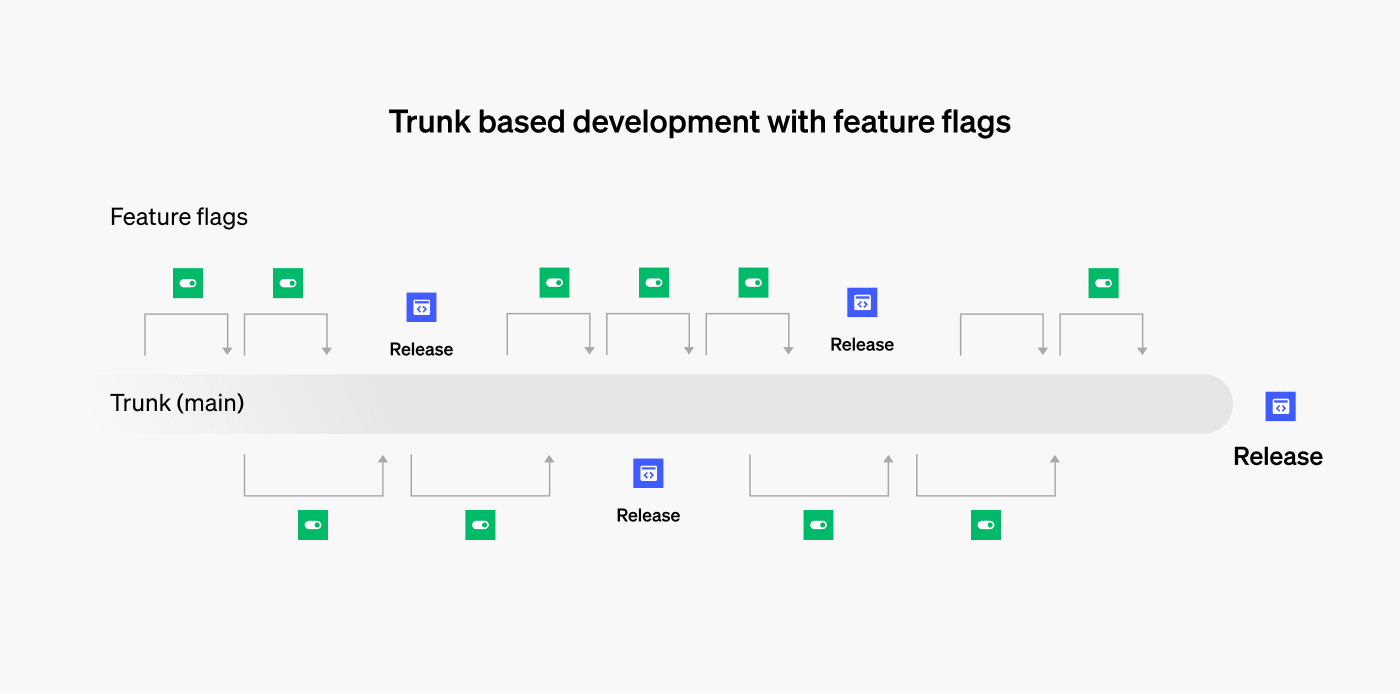
Flags for development only
A common situation in TBD is wanting changes to be visible in a development environment for testing, but not to be visible in production. Since, by definition in TBD, any changes in trunk can go to production, you must distinguish deployed (code moved to an environment) from released (visible in an environment). The typical first step is to link an application configuration setting to your branch by abstraction seam. The configuration can be managed by a build system to release your changes in a non-production environment and keep them disabled in production. This technique gives you the confidence that your changes won’t be prematurely released to production while still letting them be released elsewhere.
Flags for deployment gating
Having mastered the use of feature flags to manage releases between non-production and production environments, the next step is to perform an incremental release of changes into production. For example, you may do a canary release, in which you start by releasing a change in production to internal or pilot users only, or only to a certain geography. You then observe the impact of that change in production, and based on those observations, you release the changes to more and more users until eventually they’re released to your entire customer population.
The challenge here is using feature flags that provide the granularity you’re after and to manage them in a low-overhead way. Continually changing the build system to facilitate releases around feature flags will quickly become taxing for a build engineering or DevOps team. And while many engineering teams may think that they could build their own feature flag management system, they probably shouldn’t. Building such a system takes focus away from the core competency of the organization and the team. Instead, a software development team will ultimately want the benefits of this level of feature flag management, but as a service.
LaunchDarkly for strategic flag management
LaunchDarkly is such a feature flag management provider, and it enables you to do TBD with feature flags. In LaunchDarkly, you can set up feature flags to control releases in almost any way you would need. LaunchDarkly supports many of the elements that are essential to an organizational release such as scheduling a feature flag update, implementing approvals of feature flag updates, integrating feature flag changes with other external metrics or events, and so on. Ultimately, LaunchDarkly allows software organizations to use feature flags in sophisticated ways on a large scale. And it is a key driver of trunk-based development.
Conclusion
More and more software development teams are looking to speed up release cadences to get changes into customers’ hands faster than ever before. This goal exposes the high overhead associated with more classic branching strategies as well as the lack of built-in, granular control over releases. Trunk-based development is the best enabler for improving your code quality through better developer collaboration and real continuous integration.
LaunchDarkly takes TBD to the next level by providing feature flags as a service to seamlessly link in-progress and completed features with dynamic releases. Request a demo today.


















