





AI iteration tends to move quickly and informally. Prompts evolve, models get swapped, parameters are tweaked. Progress is often judged by re-running the same input and seeing how the output shifts. Decisions happen in context, but the reasoning is rarely documented, so it’s easy to lose track of why one version was chosen over another.
The LaunchDarkly LLM Playground for AI Configs gives teams a place to experiment before anything gets locked in. You can test prompts, models, and parameters in isolation, explore behavior across inputs, and get a feel for what works, without the pressure to ship. When an exploration proves useful, it can be moved into a managed configuration and treated as something durable.
Making early experiments traceable
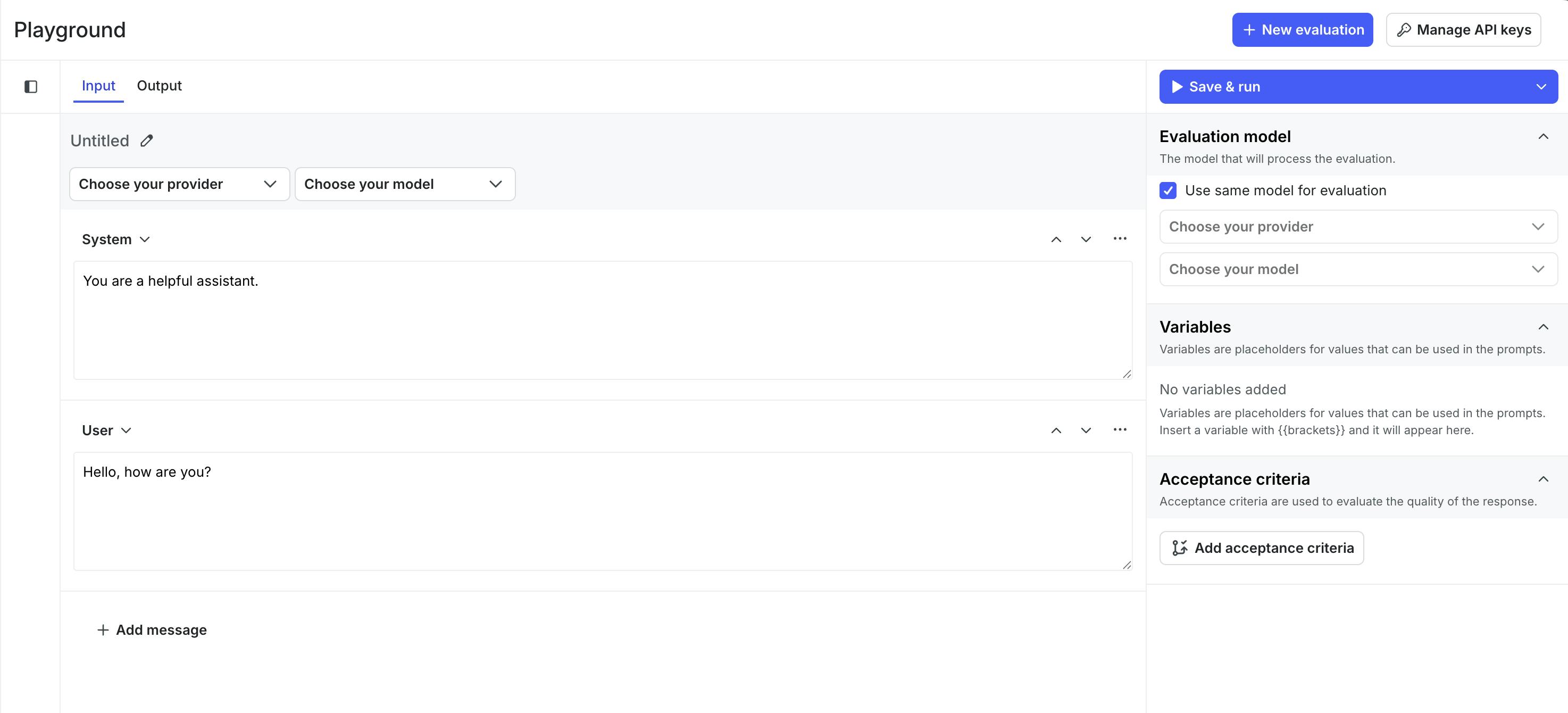
With LLM Playground, teams test prompt and model variations one at a time, evaluate them against built-in quality metrics, and promote a chosen variation into a managed configuration for production. Each run keeps its context intact, including the prompt, model, parameters, and evaluation results, so iterations can be compared side by side rather than judged in isolation.
Each run captures the full configuration that produced the result, along with the output and the evaluation method. A single run becomes something you can return to later, compare against, or reference when needed, rather than a one-off test that only made sense in the moment.
Where quality tradeoffs become visible
A math tutor agent has to answer questions correctly, explain reasoning clearly, and avoid language that could mislead students. A prompt might look reasonable at first, and a test question may generate a solid response. At that point, it would be easy to ship and move on. A small wording change can improve clarity but degrade accuracy. Another variation can restore accuracy, but introduces phrasing that feels risky to ship.
Without a record, the decision comes down to a gut feeling or which response seemed best at the time. With LLM Playground, the same input can be run across each variation, and the outputs compared side by side. This makes shifts in accuracy, relevance, and safety signals clearly visible; the tradeoffs are no longer implicit.
A customer support assistant needs to stay grounded in policy while still sounding empathetic. A recommendation system needs to balance relevance against tone. Small changes can improve one dimension while quietly degrading another, making it hard to see from a single output alone.
That record becomes useful later, when those decisions need to be revisited. LLM Playground lets you see not just what was chosen, but also what was tested and why it was left behind.
Why history matters after release
A few weeks after launch, the math tutor agent is still answering questions correctly, but feedback starts to come in that explanations feel longer than they need to be. A recent prompt tweak or a model update from the provider might be responsible, but it isn’t obvious which change caused the shift.
Because the configuration was promoted directly from the Playground, it can be traced back to the runs that shaped it. The tested alternatives remain, along with the scores and trade-offs that informed the original decision. That makes it easier to decide what to try next, whether that means revisiting a previous variation or adjusting a parameter left untouched during the original iteration.
Prompts that worked well at launch may need adjustment as user behavior shifts or models change under the hood. When that happens, teams can test new variations using the same criteria used before, without starting from scratch or guessing based on a handful of production examples.
The first step into offline evals
LLM Playground is available now in AI Configs. Teams can test prompt and model variations one at a time, evaluate them against built-in quality metrics like quality, toxicity, and relevance, and promote working variations into managed configurations for production.
Single runs today are the starting point for offline evals in AI Configs, with plans for LLM Playground to support more robust, scaled offline evals in the future.
Explore our docs to learn how LLM Playground works, or start a free trial to try it in your workspace.
Like what you read?
Get a demo