




AI has changed how we build software, but it hasn’t changed how we control what ships. The LaunchDarkly 2026 AI Control Gap Report reveals that 94% of engineering leaders say AI has increased the pace of code generation. Today, teams can do code scaffolding, test generation, and implementation in minutes—work that used to require a few days. For delivery pipelines optimized around speed, this shift is positive.
At the same time, 91% of respondents said their teams have become more cautious about pushing changes to production. That caution reflects a recurring problem: while build and deployment velocity have improved, production reliability has not. The same report shows that 69% of teams roll back or hotfix at least once per week, and only 12% can resolve production issues in under an hour. The majority require between 4 and 12 hours per incident.
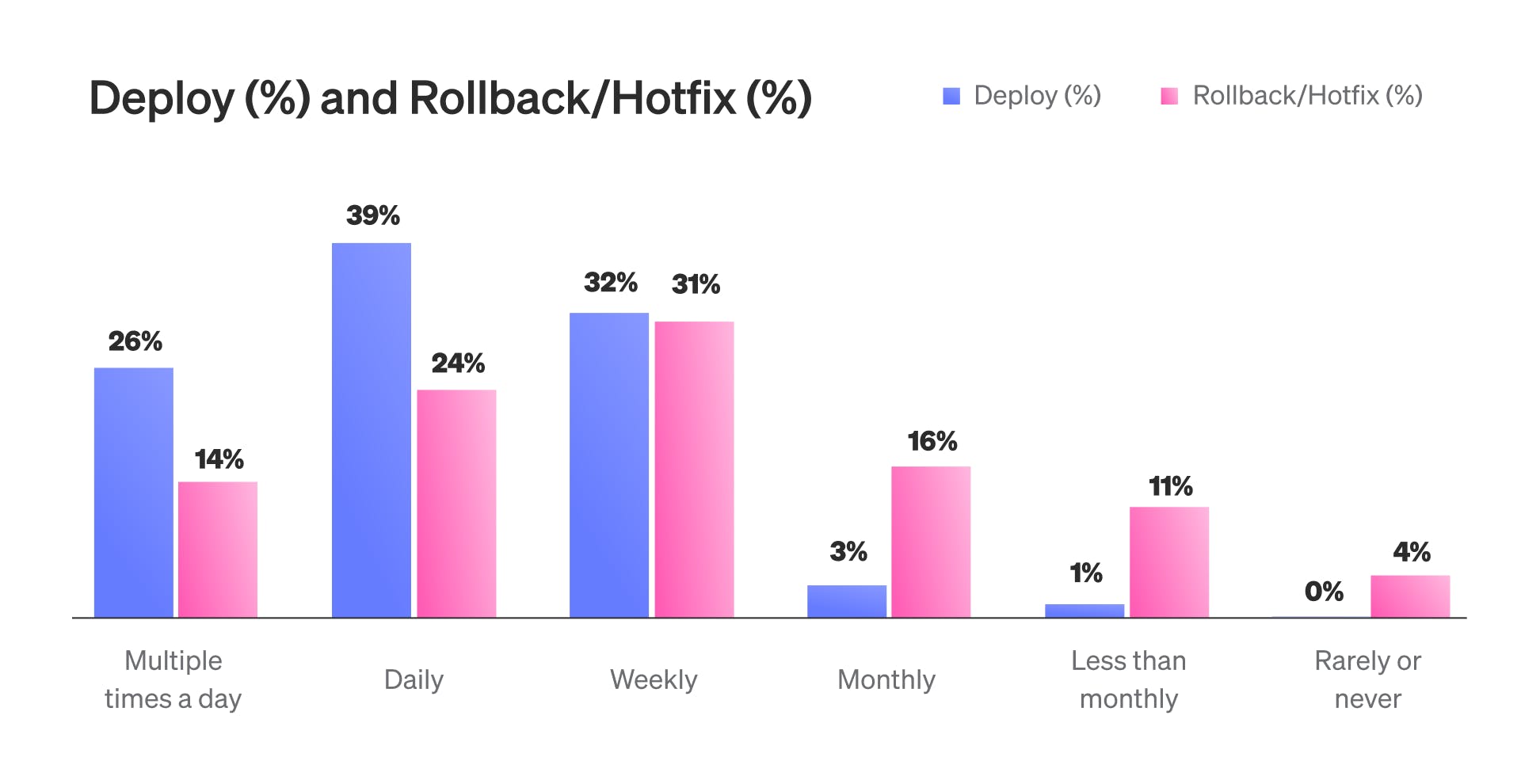
Shipping is faster, but recovery isn’t. That mismatch creates friction, especially as more teams rely on AI-generated artifacts with less predictability and fewer deterministic guarantees. Faster code generation has moved risks into production, where traditional delivery pipelines provide limited control. Build-time safeguards don’t address the need to manage change when it goes live.
Teams that want to ship AI-generated code safely and quickly need control in production: the ability to limit exposure, observe real-world impact, and change behavior while systems are live, without rebuilding or redeploying. When this runtime control is in place, teams can release smaller changes more frequently, detect issues earlier, and stop or adjust features before incidents spread.
AI introduces new runtime risks
Beyond compiled code, teams now ship model prompts, configuration files, parameters, and embeddings: elements that are harder to test in isolation and more dynamic in production.
91% of developers surveyed believe AI-generated code is equally or more likely to introduce production issues than human-written code. This statistic aligns with observed outcomes: higher incident rates, longer MTTR, and slower rollback cycles.
Traditional safety practices—such as test coverage, static analysis, and peer review—still apply, but they provide limited protection when non-deterministic behavior reaches production. Teams need mechanisms to identify, isolate, and remediate issues after deployment. Without those mechanisms, production becomes the debugging environment.
Most teams say they have runtime safety systems in place. 99% report using at least one of the following: feature flags, progressive rollouts, kill switches, or real-time monitoring. Yet outcomes suggest inconsistent implementation and uneven usage.
Common breakdowns include:
- Feature flags being applied inconsistently across teams or services
- Manual rollout coordination across environments
- Monitoring tools that surface metrics without linking to feature exposure
The controls are in place, but a lack of integration and standardization undermines their reliability.
A small number of teams combine speed with control
Only 15% of surveyed teams deploy changes daily (or more frequently) while keeping incidents to a monthly or lower frequency. These teams tend to structure releases around runtime control from the start. They use dynamic targeting, staged rollouts, and production observability that is tied to feature state, not just infrastructure.
The operational benefits are measurable. LaunchDarkly users, for example, are 2.2 times more likely to meet this performance benchmark than the average team. 71% of LaunchDarkly users spend at least a quarter of their time on feature development, compared to 56% among peers using other platforms.
Runtime control enables these teams to run smaller, safer experiments and respond more quickly when something breaks. A staged rollout to 1% of users can uncover issues early. If telemetry indicates a spike in latency or an unexpected behavior, teams can pause the rollout or turn off the flag entirely without a redeploy or hotfix. This level of control improves both engineering efficiency and customer experience.
The productivity impact compounds over time. Fewer incidents mean less context switching. Faster remediation reduces team downtime. Greater confidence in release safety supports continuous delivery without increasing risk.
Runtime control isn’t optional anymore
The core delivery problem most teams face is the lack of integrated systems that support safe change in production. Velocity is only useful if teams can maintain stability at the same time. Runtime control enables this by giving teams the ability to shape, observe, and adjust feature behavior after deployment.
Runtime control entails:
- Gradual rollouts based on user attributes or cohorts
- Feature-aware monitoring with real-time impact signals
- Instant kill switches and rollback without redeployment
These are baseline capabilities for teams shipping AI-generated features that evolve over time or respond to live input.
Most mature engineering teams can now deploy daily, or even multiple times per day. However, post-deployment control remains unsolved, especially for AI-related features where regression risks are harder to catch in advance. Teams that embed runtime control into their delivery workflows can more easily maintain both speed and stability. Those that treat control as a manual or optional layer usually revert to reactive behavior: full rollbacks, emergency patches, and long debugging cycles that consume development time.
With AI accelerating the complexity of software development, the cost of not closing this control gap will increase over time. The most successful teams will be the ones that can routinely adapt live systems without relying on hope or heroics. For more insights on how those teams are moving forward, download the report.