





Why experiment results still take too long to trust
Let’s say you’re running an experiment and it looks promising. Metrics are trending in the right direction. You find yourself waiting. Why? Because traditional Frequentist tests require you to determine a sample size in advance, run the experiment for a full duration, and then check the results only once at the end.
This is known as “fixed horizon” testing. While it can be effective, it often leads to rigid timelines and potentially wasted time.
You can’t make mid-flight decisions
With fixed horizon testing, you can't make adjustments during the experiment.
Sequential testing speeds up experimentation and makes it more flexible. Instead of forcing teams to calculate sample sizes up front or wait for a fixed endpoint, sequential tests continuously evaluate results and can stop early when a clear winner emerges. This means less time waiting, fewer wasted samples, and faster insights without sacrificing statistical confidence.
Smarter math that accounts for “peeking”
Sequential testing modifies the calculations underlying your experiment to enable the safe early review of results. This provides:
- the freedom to look at results multiple times
- the power to stop early if you already have a clear answer
- assurance that your test still has rigorous statistical guarantees
Instead of locking yourself into a set duration, you can adapt. You run your test, check your metrics often, and if the results are strong (or clearly not working), you can call it early, with the math to back it up.
Why sequential testing matters
Say you’re testing a checkout flow. The new design seems better; users are converting more. A week in, you've reached 95% statistical significance on your primary metric. But your test was supposed to run for two more weeks.
In fixed-horizon testing, you’d ignore that and keep running. However, with sequential testing, you can stop because the results already account for the fact that you’re checking early.
This can save time. It may reduce exposure to bad experiences. And it helps you ship faster.
When to use sequential testing
Sequential testing is especially helpful when:
- You want to speed up product iteration.
- You’re resource-constrained and want to cut short underperforming tests.
- You care about statistical rigor and real-world agility.
It’s also a win for trust. Data science teams don’t have to warn product, engineering, or growth teams, “don’t peek,” and now you don’t have to ignore promising results just to stay within protocol.
How it works in LaunchDarkly
When creating a new experiment, you’ll see an option to enable sequential testing.
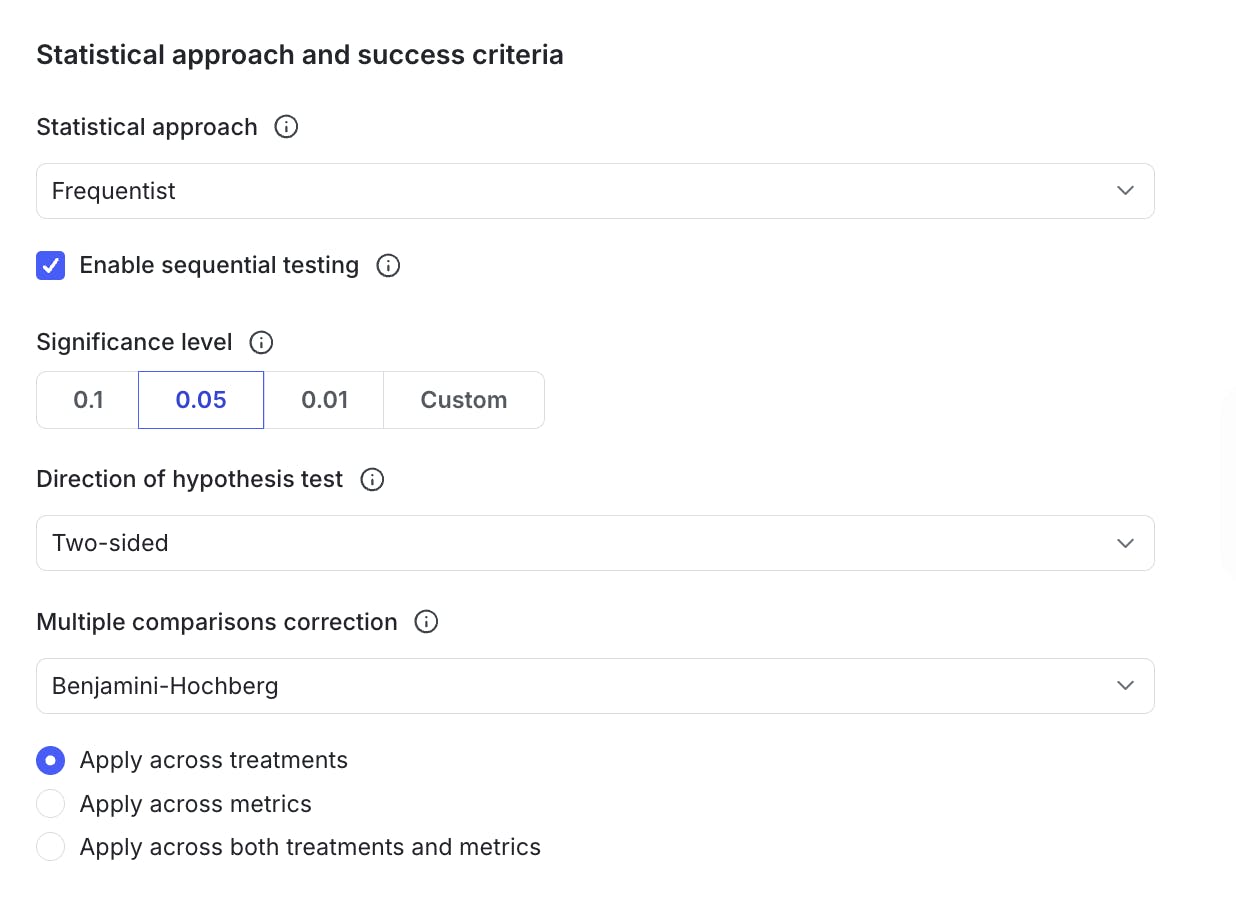
After being selected, p-values and confidence intervals are adjusted behind the scenes.
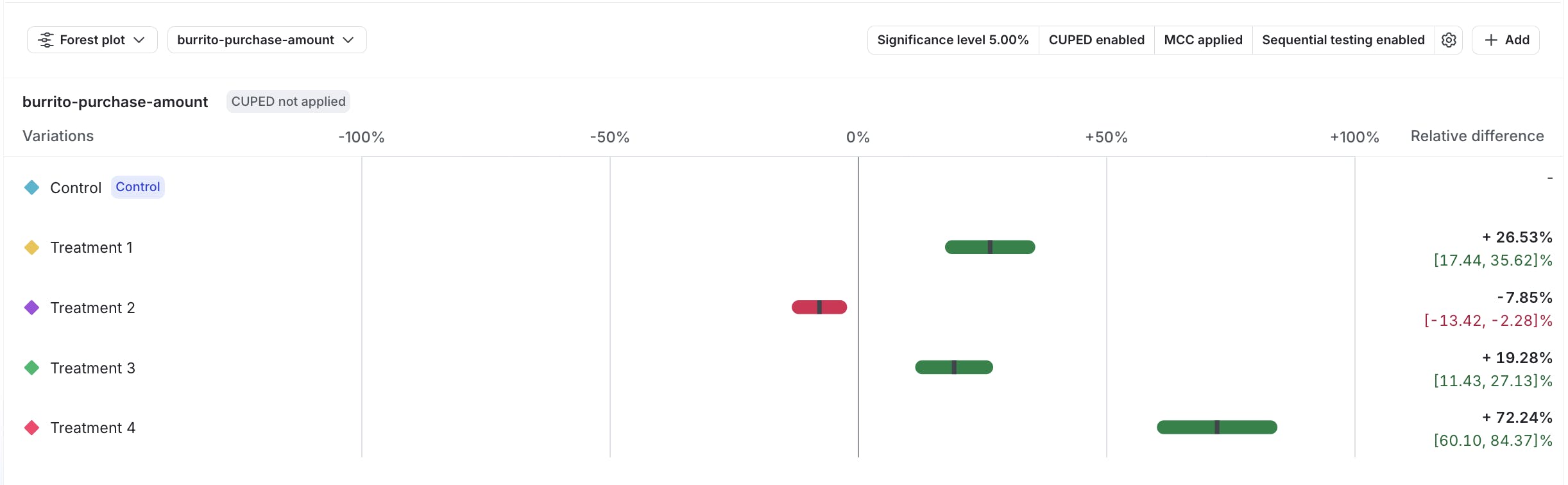
Keep in mind that:
- sequential testing is only available for Frequentist analyses in LaunchDarkly.
- we recommend sticking to the default settings unless your data science team prefers a custom setting.
- you still need to be cautious with very early reads. Peeking five minutes into a test won’t tell you much. But when your test stabilizes, you’ll get reliable signals.
Faster insights, fewer wasted tests
With sequential testing, you don’t have to wait weeks to learn what’s already obvious. You get the agility of early decisions without compromising your statistical integrity. Try it out today in LaunchDarkly Experimentation.
Like what you read?
Get a demo