





The false feeling of safety
Many of us have been there before. You wrap up all the prep work, go through your checklist and confirm that everything is set up right, and hit the approve button on the pull request that triggers your production deployment pipeline to run. You’ve had it in the test environment for a few days, there weren't any issues. Everything seems good, after all, that’s what “test” is for right? Making sure that everything's fine before it goes into production. Every great story starts with a false sense of safety or security.
In all likelihood, the deployment finishes, and then you fall into the all too common activity of hopping into your favorite monitoring tool and take a look at the environment. Everything looks good for the moment, so you go grab a water, and come back… and there’s red everywhere. Immediate regret. And then the text messages. And then the all-hands bridge. And then the RCA. And then the process. So many processes. So much governance. And now it’s time for the rollback.
What I’ve described is a nightmare. But it doesn’t have to be. In the following sections, we’ll dive in on a few strategies for recovering from failed deployments.
The scariest part of releasing software is "right after"
Build failures happen—but they tend to be pretty benign. Software build fails, and you go back and look at what caused it. Failed deployments are where the pain really hits. It’s why the scariest moment of a new software deployment is right AFTER it’s deployed—that's where the user impact shows up. That user impact is a big part of why we test so much. Too often we end up sacrificing our ability to deliver innovation because going slow means we go safe. Being cautious means we don’t have to deal with the anxiety-filling nightmare I described above. So I'll ask you this question—how fast could you ship new capabilities in your product if you had ways to instantly recover from failure? What if the risk of user impact was totally under your control?
I’m happy to report that it is under your control.
Foundational configurations - Release Assistant and release pipelines
Strong buildings are built on strong foundations. At Galaxy this year, we announced Release Assistant—a capability within LaunchDarkly that provides teams with the ability to build a release pipeline around their features, controlling the sequence they release across multiple environments.
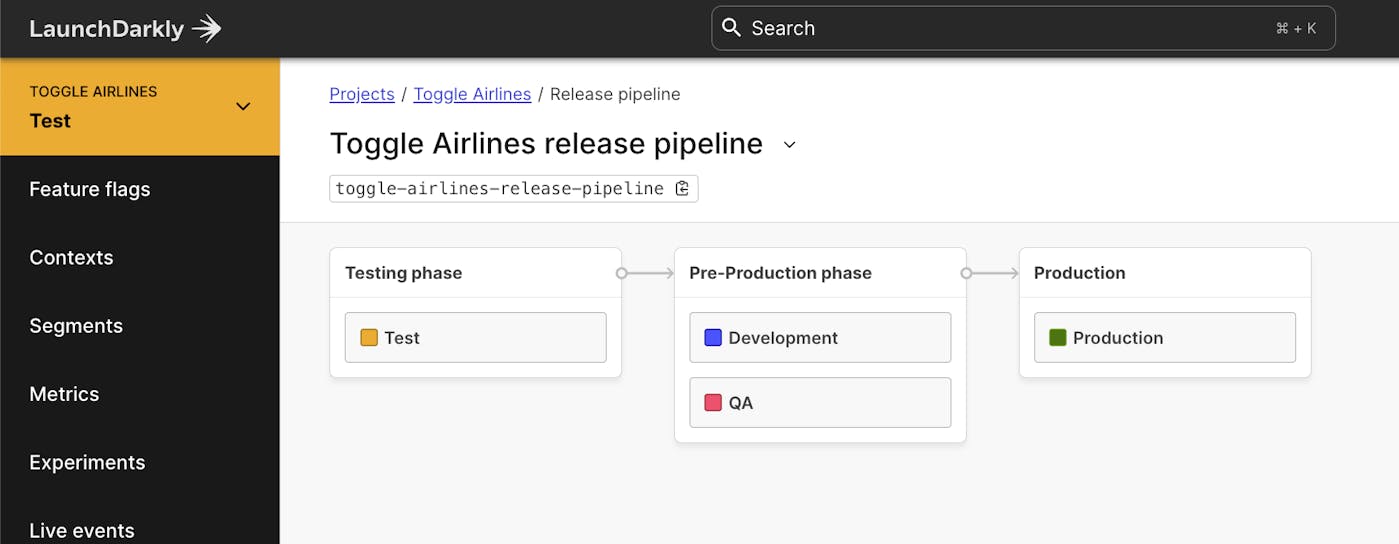
Leveraging Release Assistant as the foundation of how you’re rolling out changes in your environments gives you two things: 1) the guardrails to ensure your application releases follow the standard release sequences your organization defines out (e.g., Test > QA > Pre-Prod > Production), 2) visibility into all feature releases across your entire application landscape.
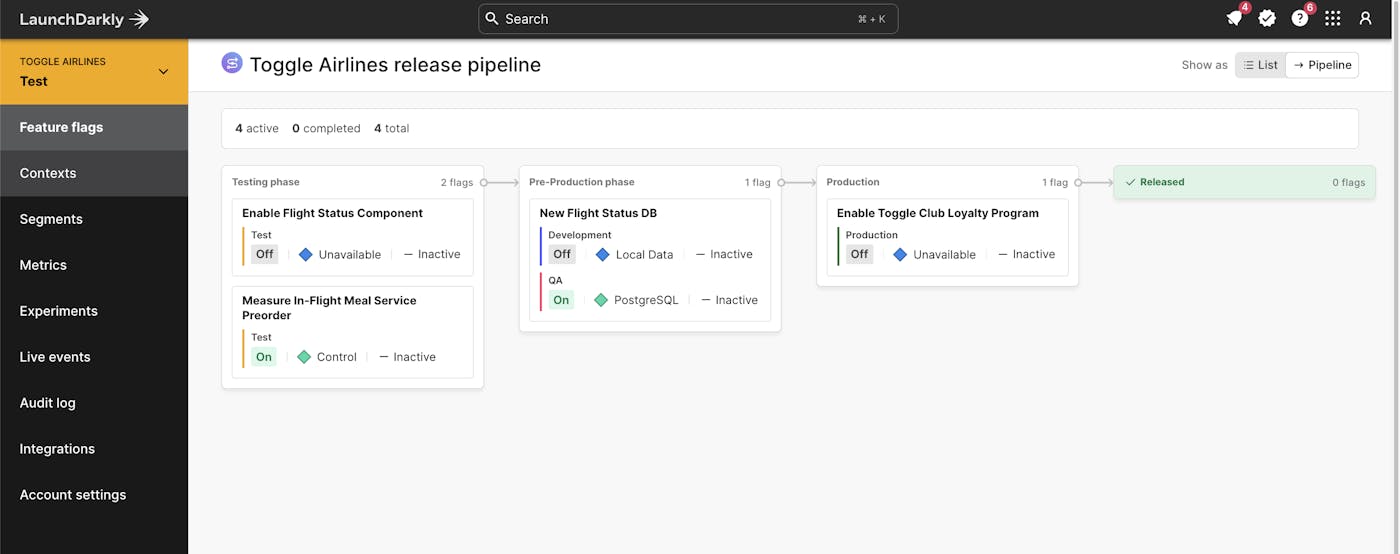
You wouldn’t build your living room completely detached from the rest of your house, right? You build the strong foundation—and build your house, including your living room, on top of it. Treating your release pipeline this way is going to give you the most predictable path to releases across these environments, and the visibility to quickly determine what has been released, where.
If you can easily track the progression of a release across environments, you can more easily find and address a deployment failure when it occurs. Moreover, when you use feature flags as kill switches, you can disable the error-causing feature in that deployment in milliseconds.
Strategy 1 - The kill switch
Tried and true, the software kill switch is a concept that’s been around for a very long time. A tool that allows you to fire some sort of a trigger that disables what you had in place previously. It used to be that we would trip a kill switch, run a new automation workflow, and it would redeploy the software with the item disabled.
In LaunchDarkly, we’re able to accomplish this live at runtime, meaning, while your application is active. No painful rollback. No watching that pipeline run. Practical example? Yeah, we have those! Check out the screenshot before, which references the code inside this repository for our popular Toggle Outfitters application.
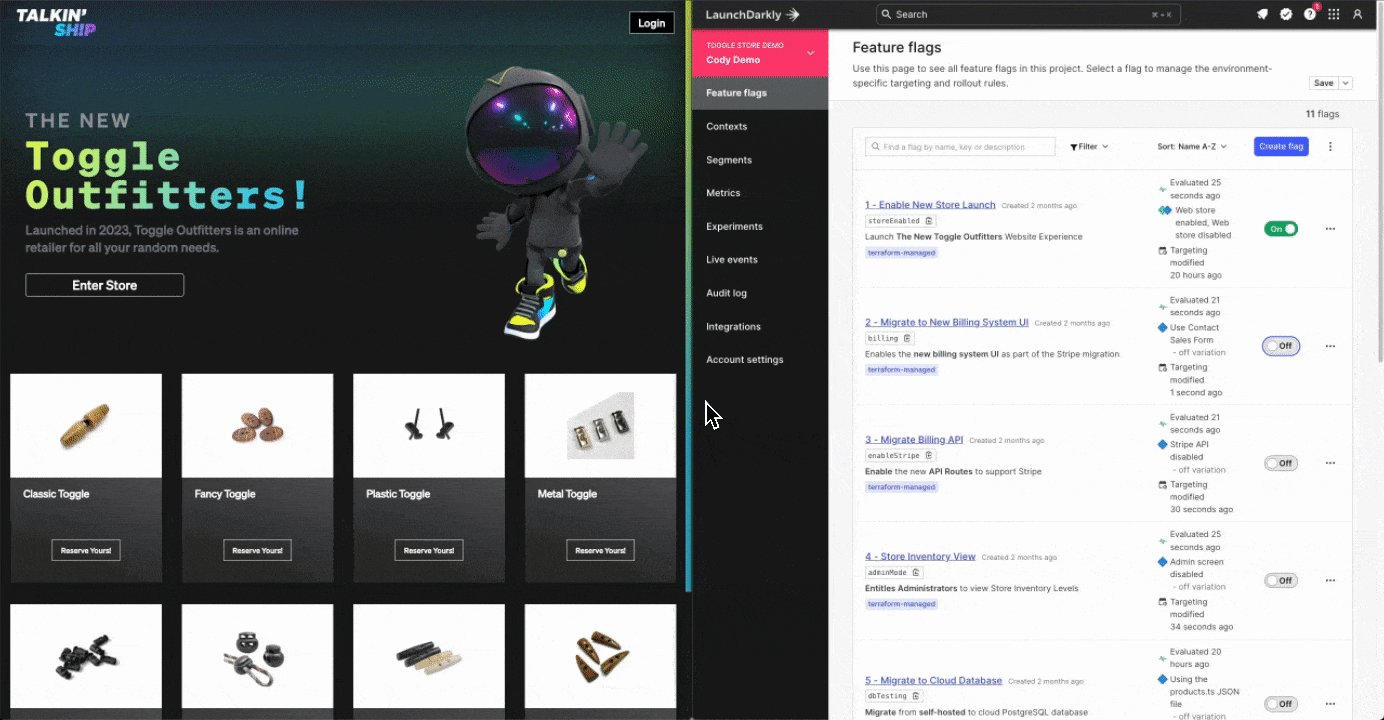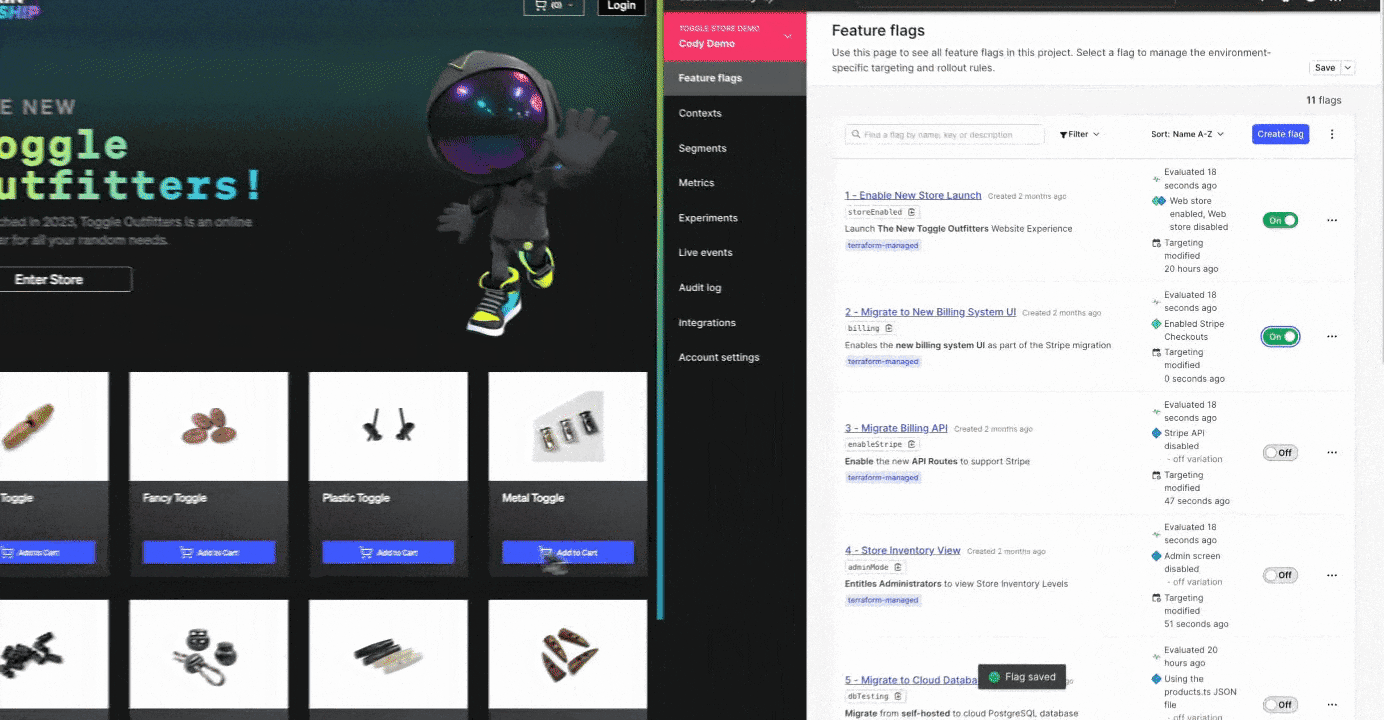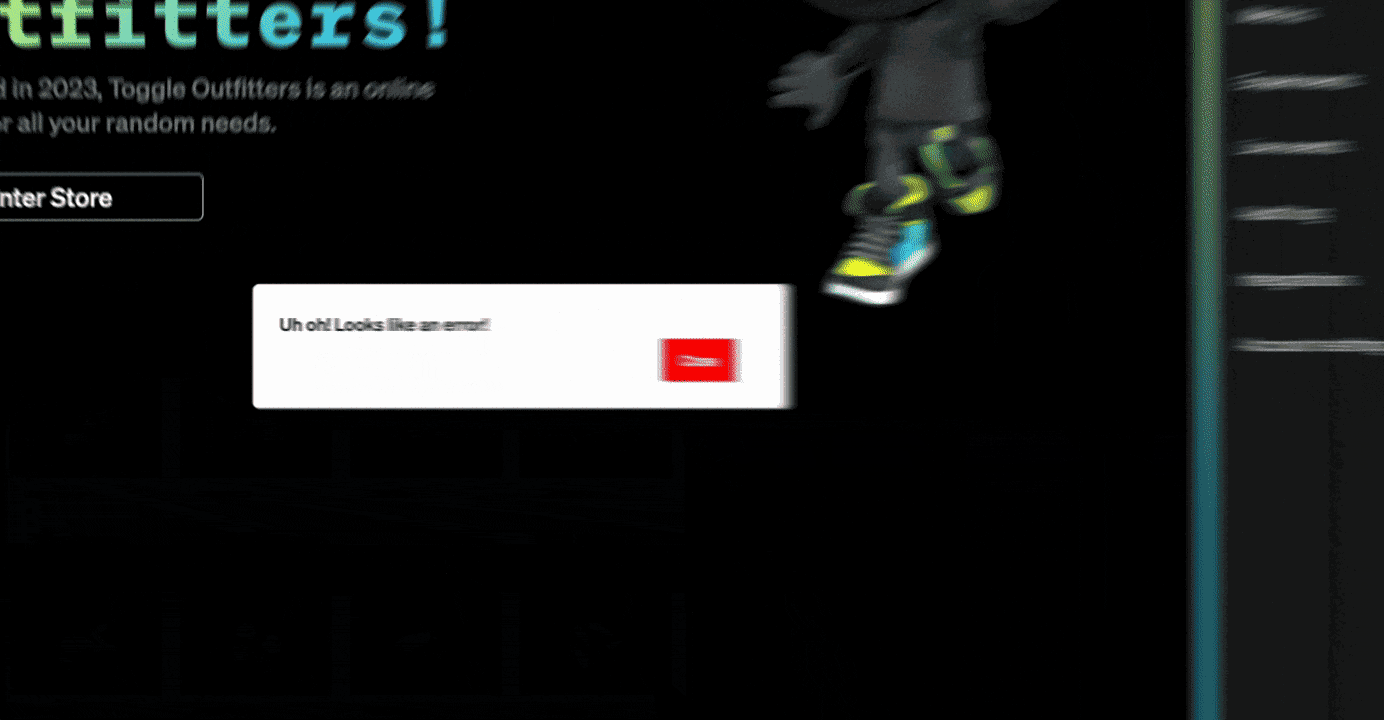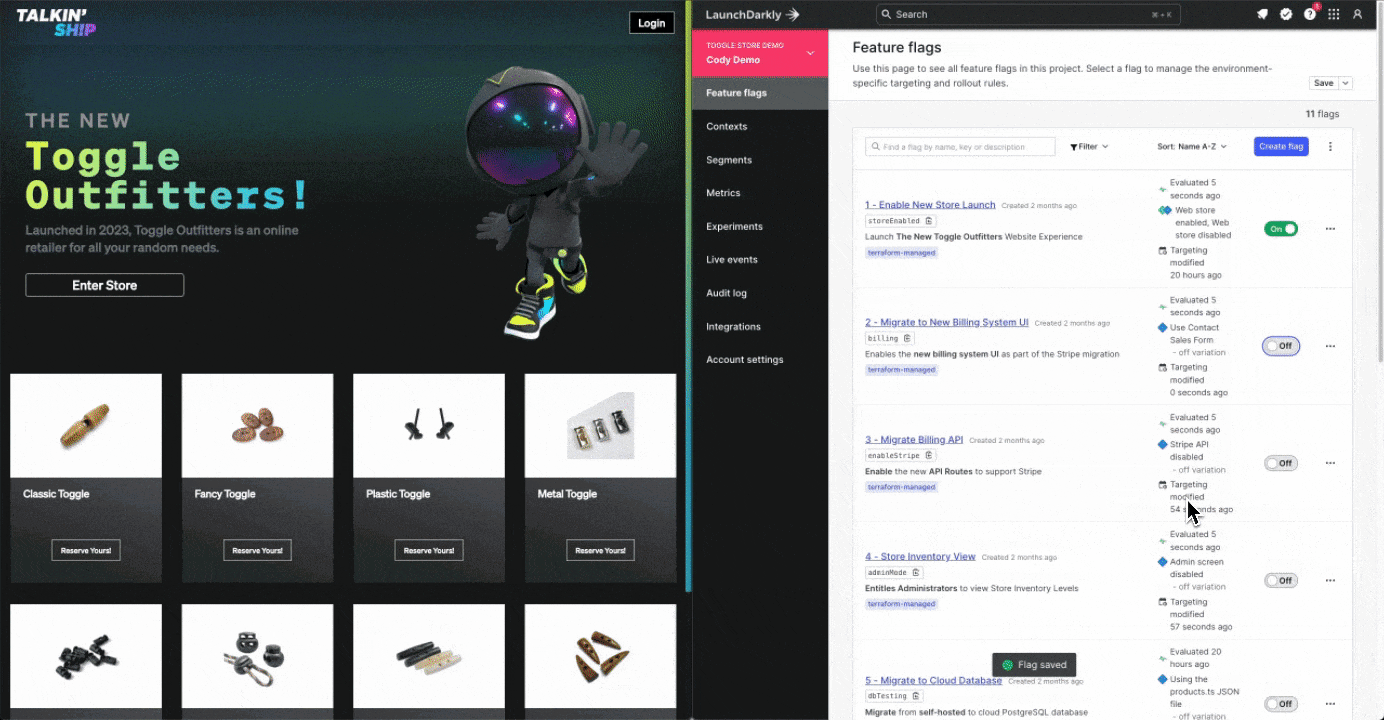
In this example, we’ve released a new store component that controls a purchasing button within our application. When the button is clicked however, the application has a problem and presents a fairly brutal error message. The legacy mode to recover this would be a rollback pipeline to recover. This might be as bad as a 1-3 hour stressful wait for a pipeline to successfully revert the deployment. Ain’t nobody got that kind of time.
With LaunchDarkly, we wrap this change in a feature flag, giving us a control point to release the change AND roll it back instantly. What does this look like in code? Here’s a simple pseudo code example in React.
const { newFeature } = useFlags()
return (
<div>
{ new Feature ? (
<UpdatedStoreComponent />
):(
<ExistingStoreComponent />
)
}
</div>
)Here we define a feature flag called newFeature, and we make a decision in our code based on the state of this flag using a ternary operator. If the feature is “true”, return the UpdatedStoreComponent, if it’s disabled, return the ExistingStoreComponent. It’s a simple model—but it’s incredibly scalable—and it forms the foundation of how you can build resilient recovery processes. This concept takes you from a complex multistage recovery pipeline, to a toggle that disables the feature instantly. Instant recovery.
Drawback? If you’ve released that buggy code to all your users, then the blast radius is potentially huge. While the bad deployment is running (i.e., before you hit the kill switch), you might be impacting hundreds of thousands or even millions of users. Fortunately, we have something for that too…
Strategy 2 - The release target and managing the blast radius
LaunchDarkly de-risks releases through two core behaviors in the platform: the kill switch and targeting.
We talk often about this concept of the “blast radius”. When you release a feature without targeting, your blast radius is 100% of your audience. Anyone using your application has the potential of being impacted by your changes—for better or worse! Release targeting changes that. Releasing targeting gives you fine-grained control over who or what is able to receive specific feature flag configurations in your environment. This targeting is enabled by leveraging the LaunchDarkly context configured within your application.
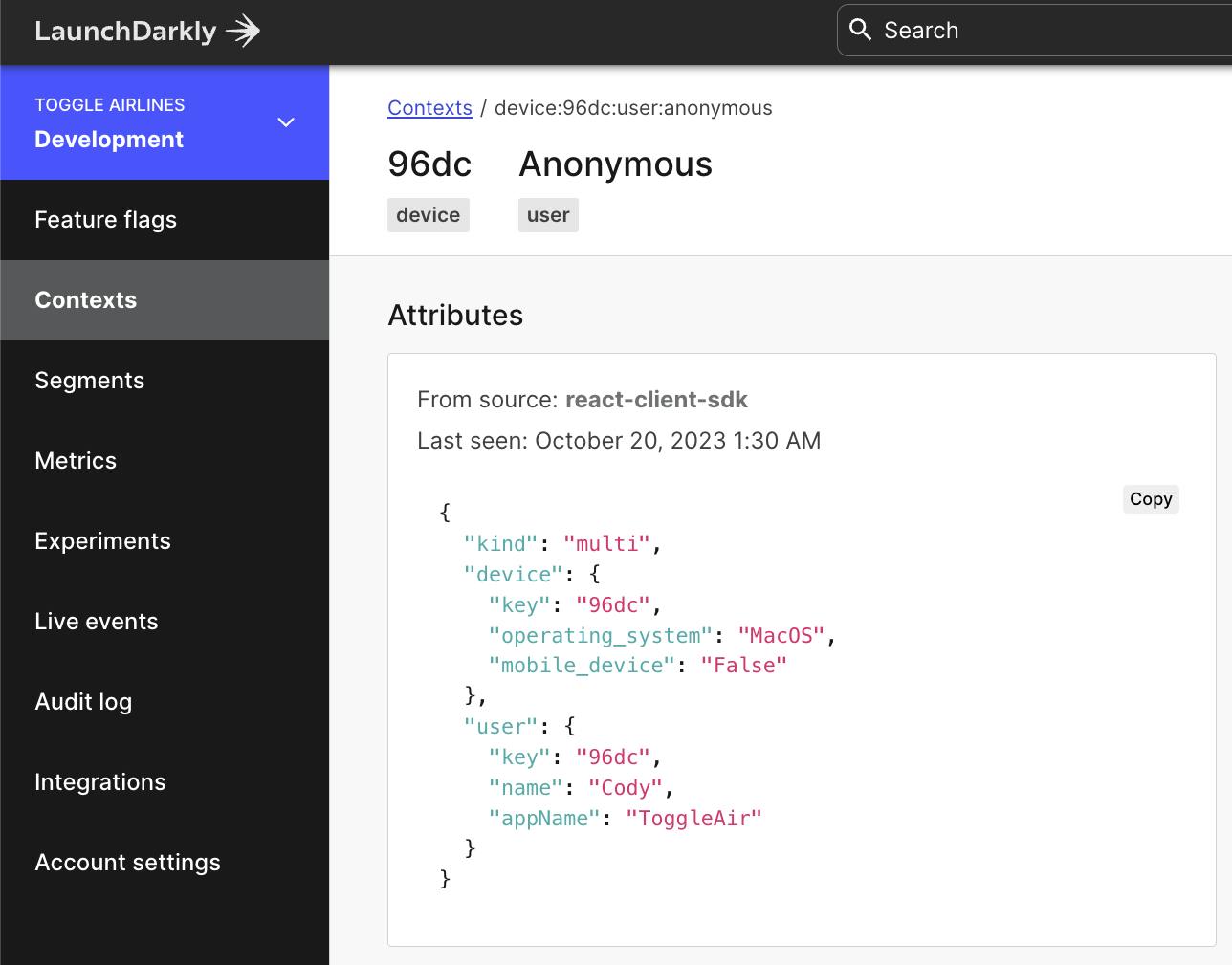
In the previous example, we used an “on vs. off” concept. This is a “boolean” flag scenario, where the flag is either `true` or `false`. These are extremely useful as an on/off switch, but it’s extremely common to need to handle multiple different states. You’ll likely have more variations (feature flag states) that you might be testing. Release targeting can let you influence how your users are evaluating against any of these!
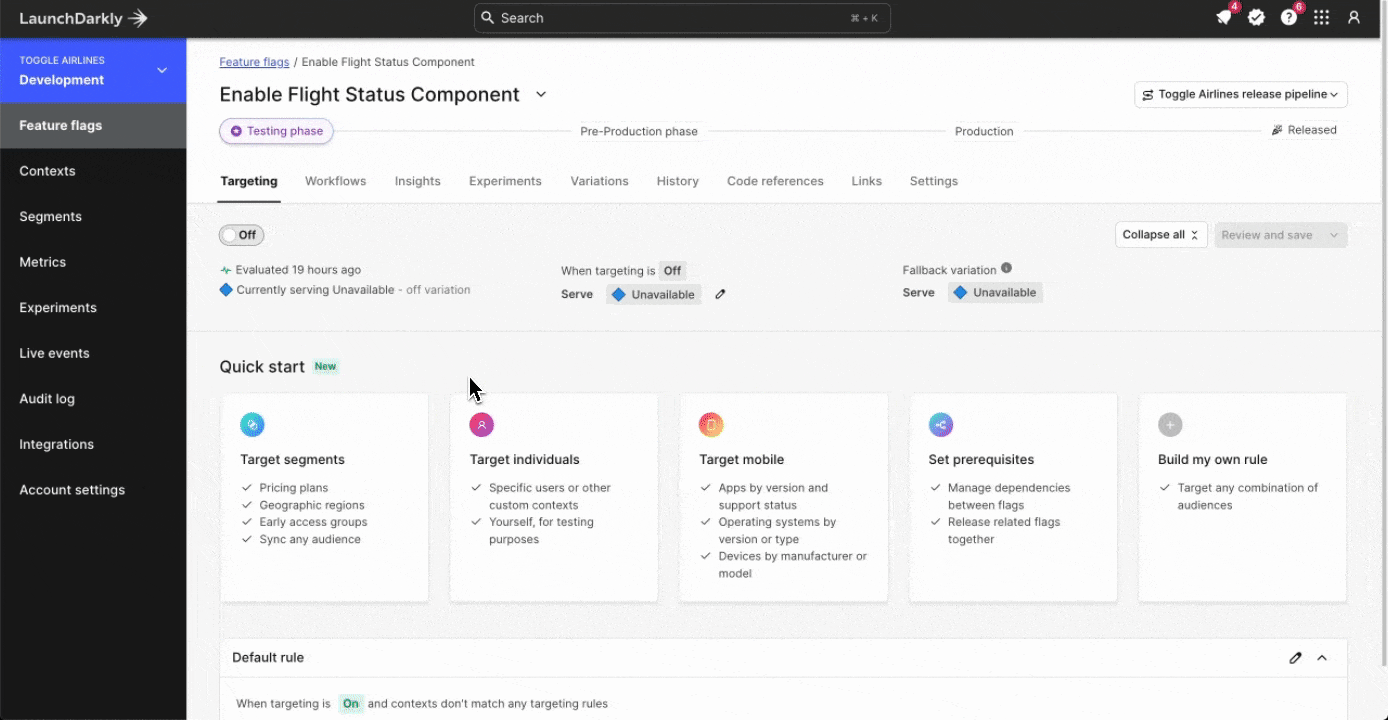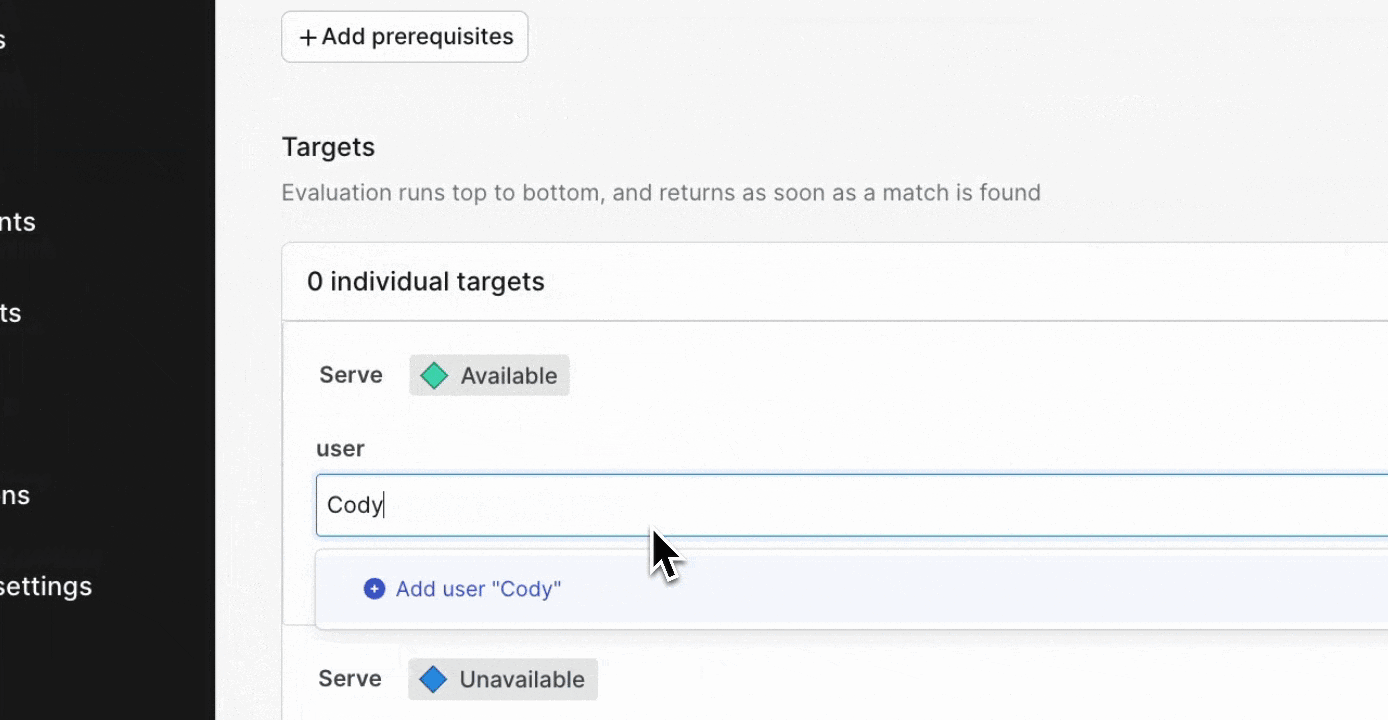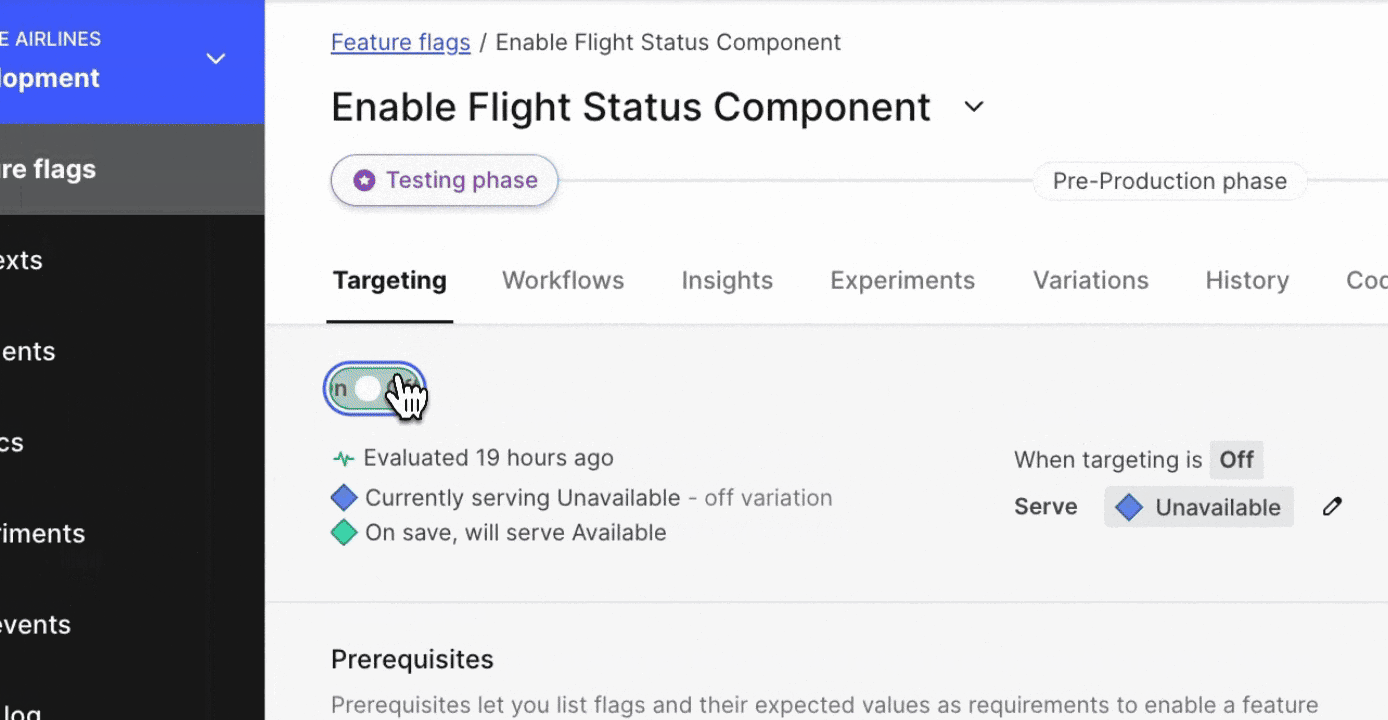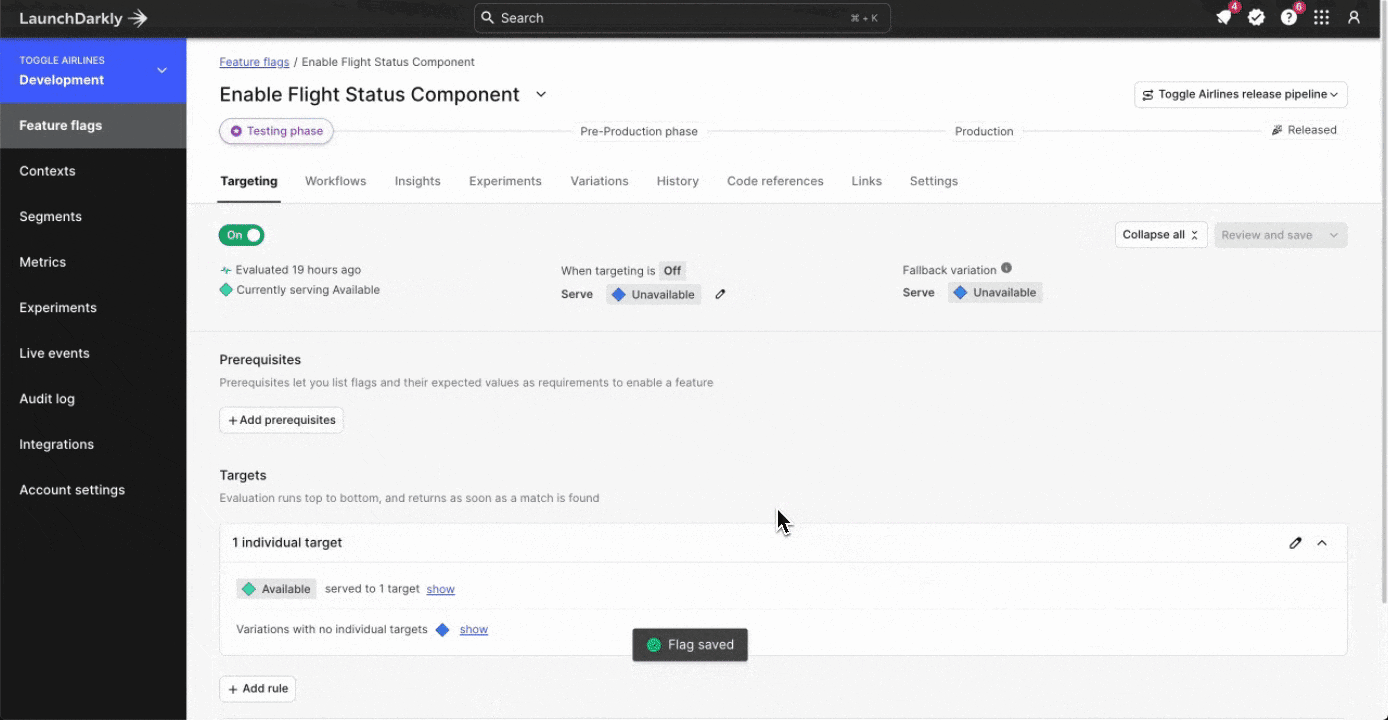
So how does this translate to failure recovery? Let’s approach this from two different directions, preventative and reactive.
Reactive recovery
When responding to a software outage, your knee jerk is to remove the problem instantly. Get the code back into a lower environment and try to reproduce (repro for short) the problem so you can solve it for the next push. The problem with this approach is that “test” is almost always different in some way from “production”. The variables change - and so the tests aren’t always consistent. Instantly disabling the feature takes away your ability to study what's happening in the production environment and understand where the potential deltas exist.
Instead, consider modifying the targeting of your release to reduce the impact of your audience down to a segment that includes only your development team, or people available to test and troubleshoot the environment. Segments are reusable “building blocks” for groups of users or systems within LaunchDarkly.
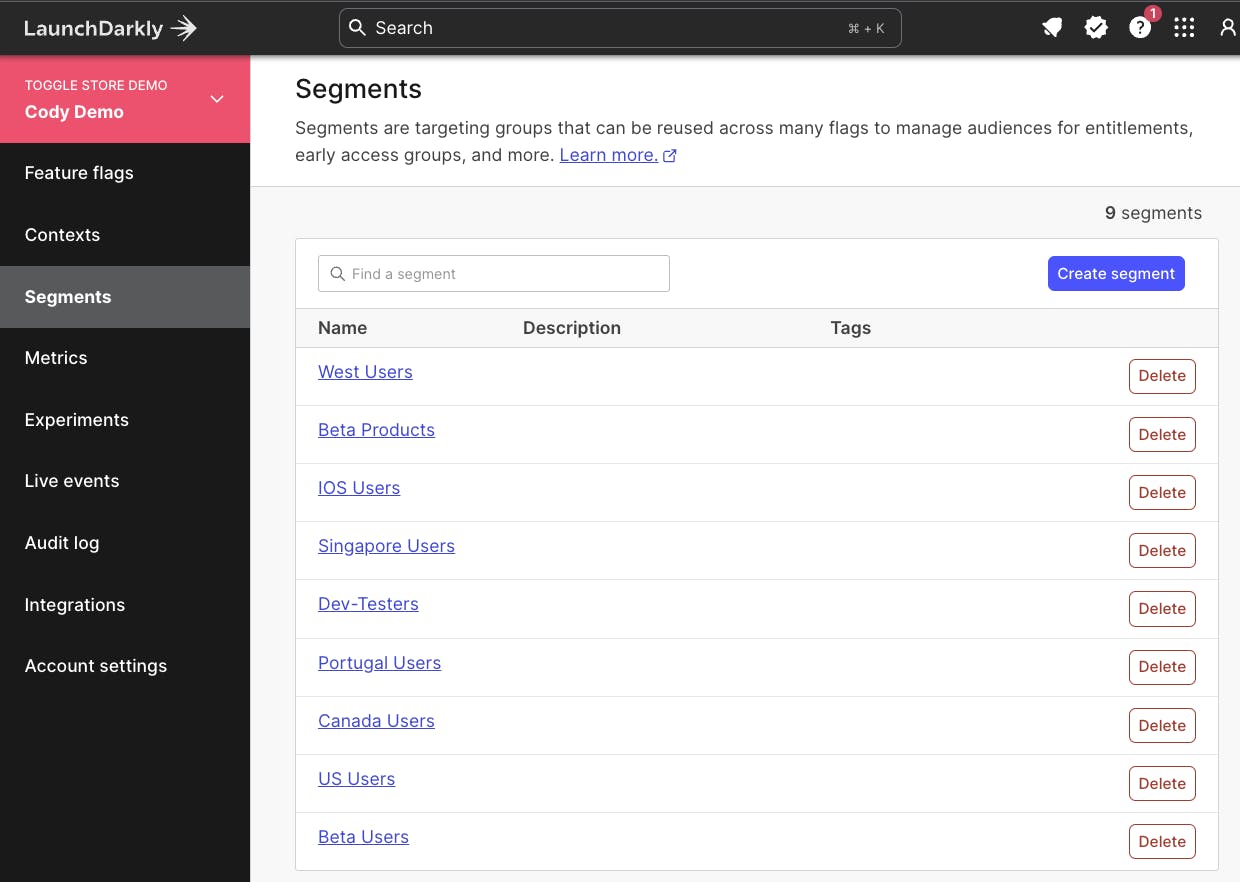
Changing targeting will apply to your application instantly (in most cases, without a refresh, but for some back-end feature flags you may need to refresh), and this removes the failure mode from your standard users while keeping the problem configuration in place for your teams to troubleshoot against.
Proactive management
Consider how you’re using segments and release targeting to progressively release your application within your environment. While this isn’t a true “failure recovery” strategy, it acts as a practice that will give you the greatest amount of release intelligence as a change moves out to your customer environments.
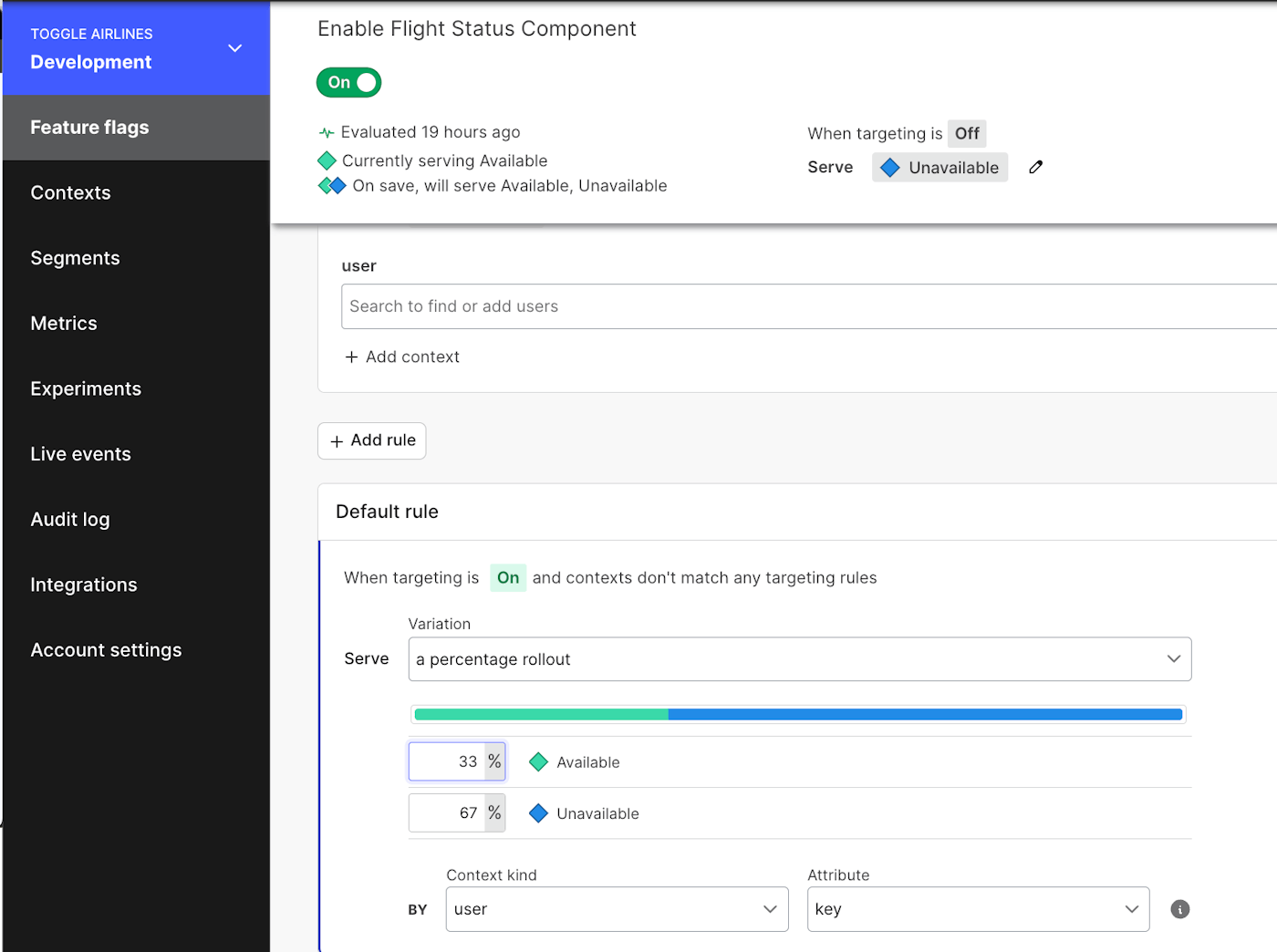
More importantly—you have the ability to either accelerate your deployments or roll the “throttle” back as needed. When approaching concepts like database or cloud migrations, it’s not uncommon to have failure scenarios appear as the environment reaches a certain load. It might only present itself when you’ve hit a certain user threshold, or stress on the system.
Consider ahead of time the progression strategy for releasing your features - and build segments to match that scenario. A personal favorite of mine starts with a developer segment, moves into a West Coast segment, and progresses forward across multiple time zones. This lets me roll out changes as times where I can predict user load on a system.
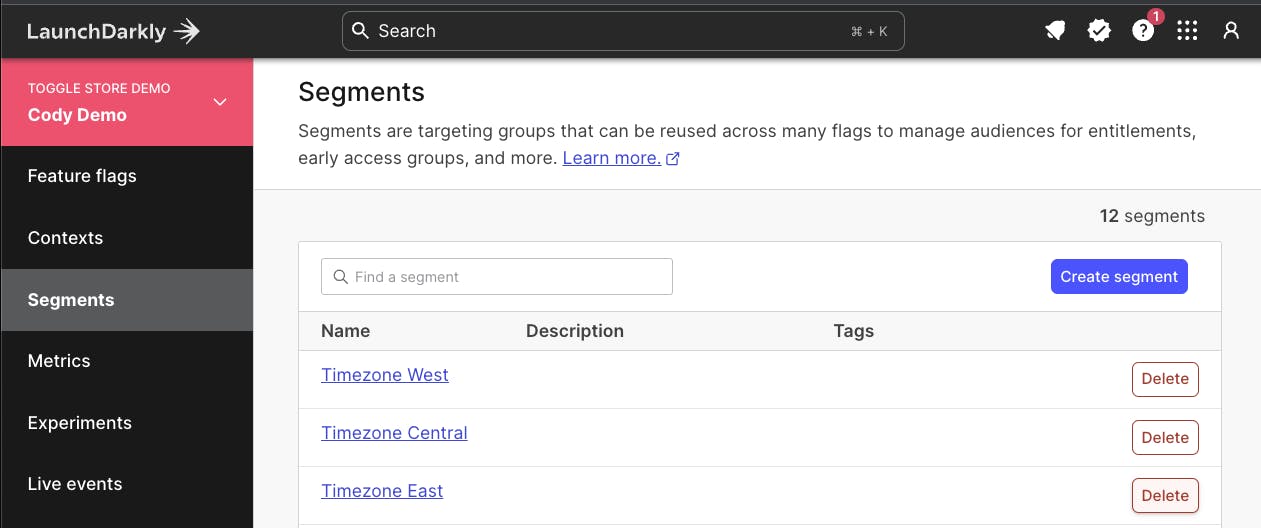
This approach lets me quickly remove a segment from a release target, changing the experience for everyone who's consuming the application that falls into that segment configuration. Remember, you can create segments based on any LaunchDarkly context property. We’ve got some great content that covers how you can maximize the way you use context based rollouts, including one from my teammate Peter here.
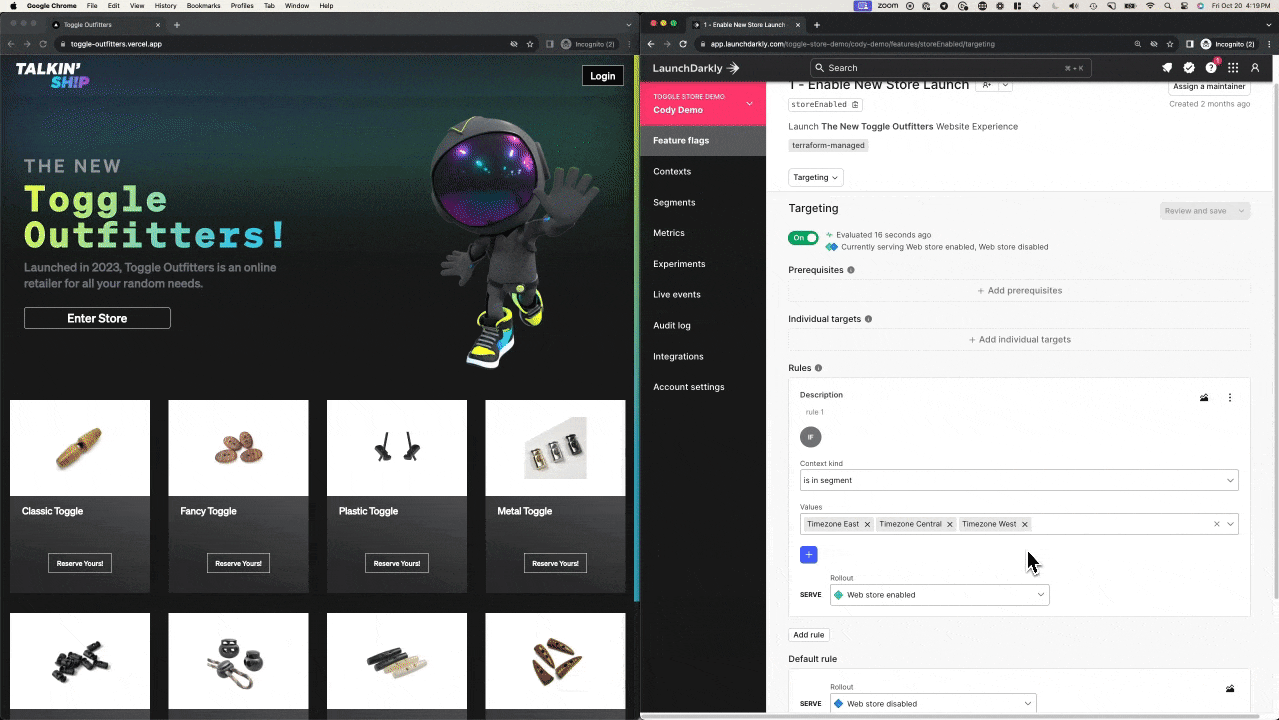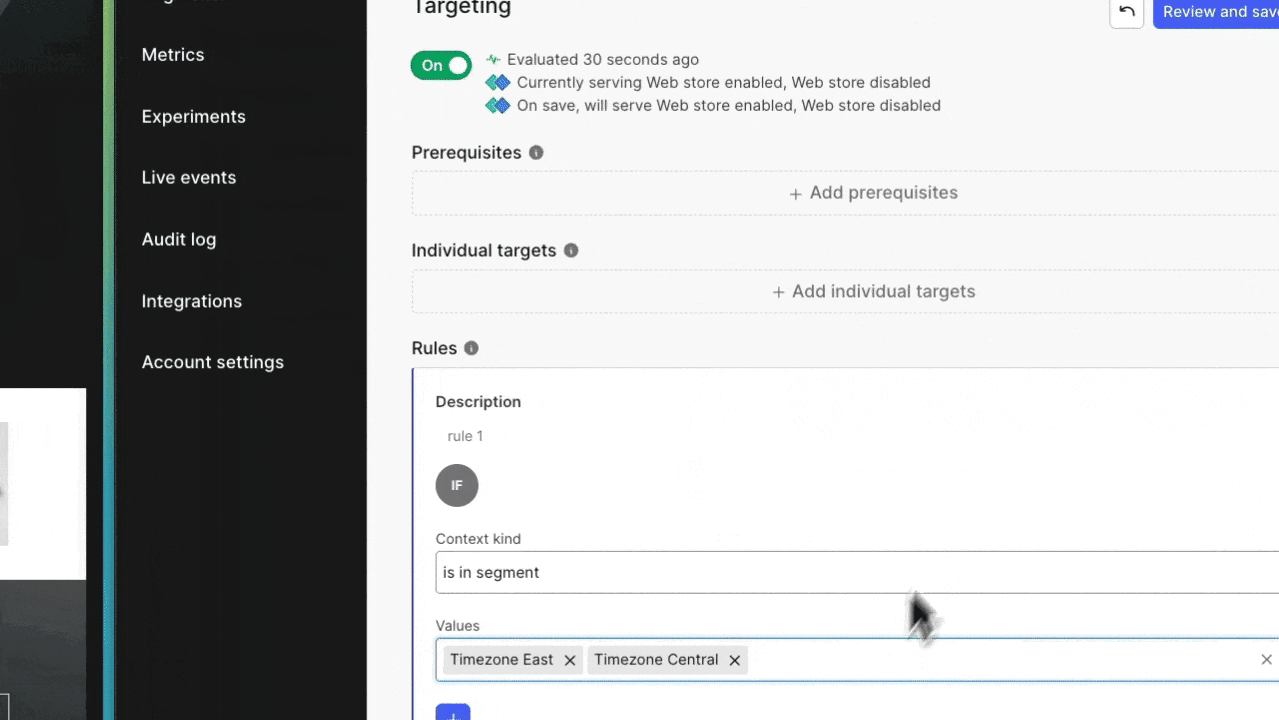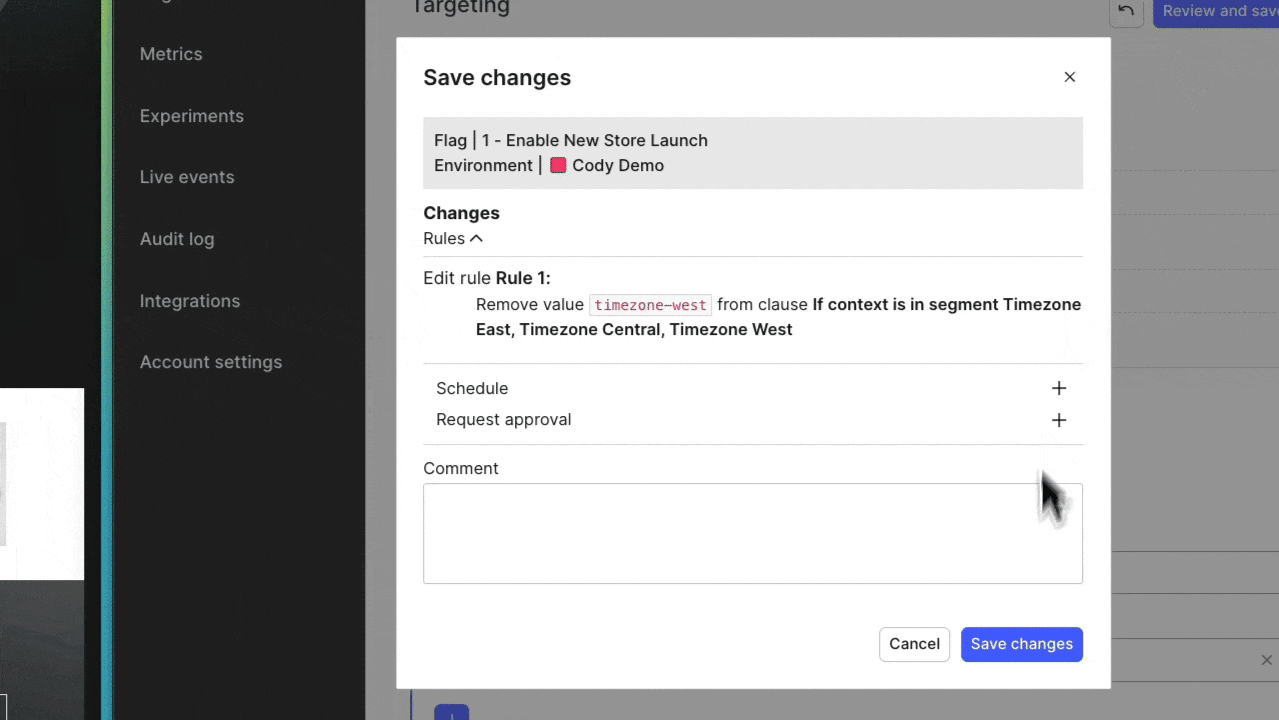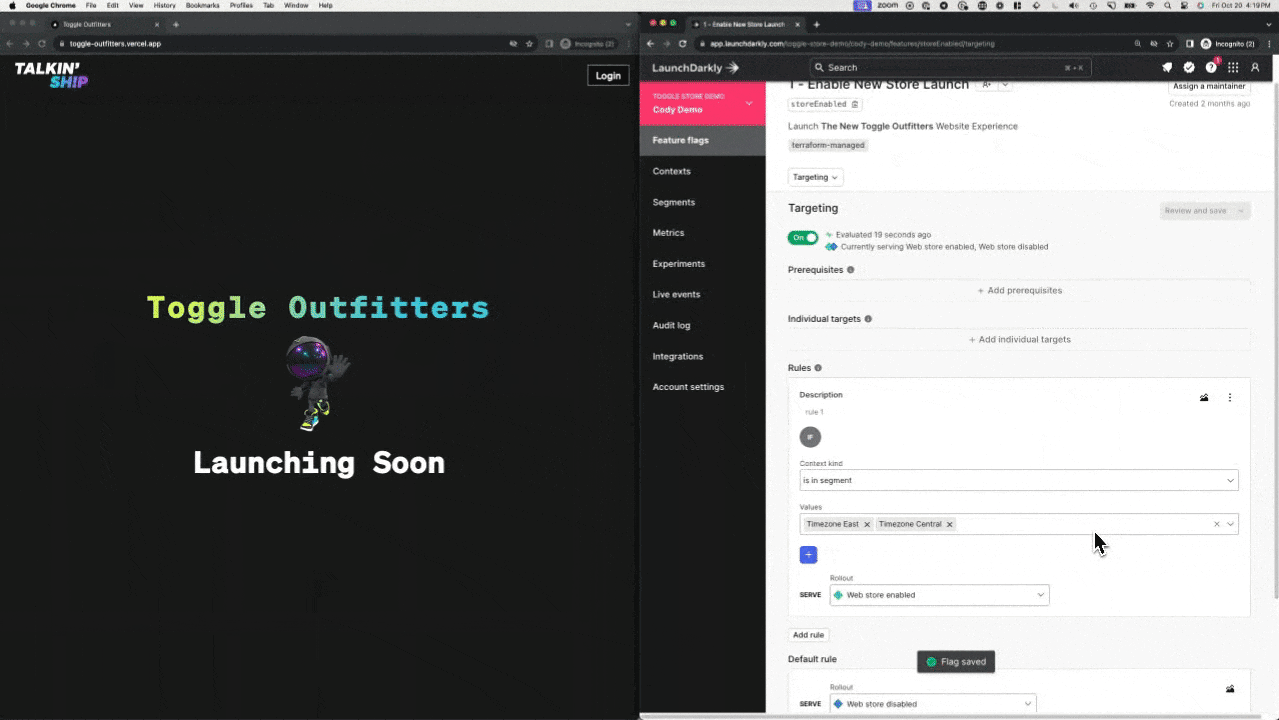
These changes are processed instantly, thanks to our global flag delivery network that delivers changes in under 200ms. No long rollback pipeline. No complex custom code changes. Just good ol’ fashioned release targeting. It’s my favorite.
But what about when you want to let the system manage itself? Cue Release Guardian…
Strategy 3 - Eyes on the horizon - Release Guardian
Also announced at Galaxy this year was our Release Guardian feature.
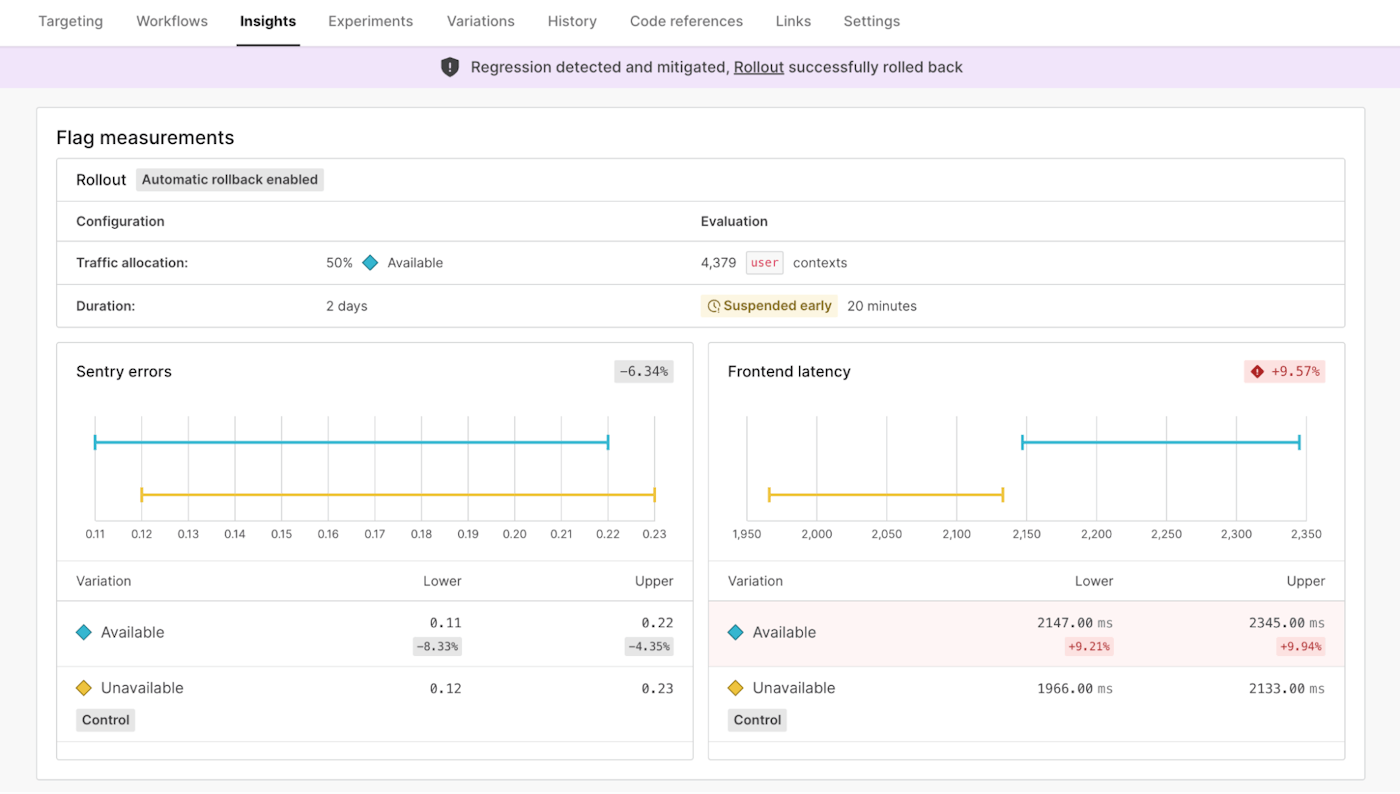
Release Guardian actively monitors the state of your feature release and will automatically disable the feature change, or reduce the scope of the rollout based on certain thresholds being breached as part of your release. Did your change introduce additional latency to your application deployment? You shouldn’t have to sit and watch monitoring tools or coordinate with separate teams to understand the impact of your change and manually take action.
Want to learn more about Release Guardian? Join the waitlist to get early access to Release Guardian
Honorable mentions
The goal of this blog post was to create awareness around some of the ways you can make the moments after a software deployment a lot less scary, by giving you the tools to recover quickly. There are a few honorable mentions that we didn’t cover in this blog post, since I wanted it to be focused on foundational concepts.
In rapid fire fashion, some of these are…
- Flag Triggers - Flag triggers are webhook configurations within LaunchDarkly that can enable or disable a flag when they are called from an API endpoint. These can be used flexibly in any automaton system - simply call the Flag Trigger address, and the flag state will change based on the endpoint you created. We talk about these here! (link to flag trigger)
- APM integrations - Platforms like Datadog, Dynatrace, Honeycomb, and more can integrate with LaunchDarkly and trigger flag state changes based on performance data within their platforms. These recoveries are automated - usually leveraging a threshold you configure within those platforms. This lets you tie operational patterns that your organization might already be using into functionality within LaunchDarkly
- Workflows - Workflows let you create building blocks of automation that represent how your feature should be released, along with all the governance and targeting changes along the way. Want to automate the sequence I outlined earlier around moving a feature between multiple time zones? Workflows will take care of you AND you can use it to create templates that can be used against other releases. This gives you another mechanism of creating guardrails to ensure your features are being released in the right way.
Want to learn more? Come attend one of our monthly Talkin' Ship workshops where you can interact with our Developer Experience team and learn how you can recover from failed changes hands-on. These workshops are practitioner focused, and lock in on getting you using the platform and building an application live alongside us. They are a lot of fun - and I guarantee you’ll walk away learning something new!
Like what you read?
Get a demo