DeepSeek vs Qwen: local model showdown featuring AgentControl
DeepSeek vs Qwen: local model showdown featuring AgentControl
Published March 4th, 2024

AgentControl(https://launchdarkly.com/blog/launch-week-2024-introducing-ai-configs/) now support bringing your own model. This capability unlocks more flexibility than ever before for supporting fine-tuned models, or even running your own models on local hardware.
In this post, we’ll compare two open source models (DeepSeek-R1 and Alibaba’s Qwen) using Ollama and AgentControl.
Prerequisites
- A dev environment with Node.js, npm, and a terminal installed
- A computer with at least 16gb RAM
- Ideally, a fast internet connection; otherwise downloading models might take a while.
Locally running LLMs: why and how
Running LLMs on your own hardware has a few advantages over using cloud-provided models:
- Enhanced data privacy. You are in control and can be confident you’re not leaking data to a model provider.
- Accessibility. Locally running models work without an internet connection.
- Sustainability and reduced costs. Local models take less power to run.
I was intimidated by the idea of running a model locally. Fortunately, tooling and models have come a long way! You don’t need super specialized knowledge, or particularly powerful hardware.
Ollama is an awesome open source tool we’ll be using to run large language models on local hardware.
Choosing our models
Ultimately, which model to choose is an extremely complex question that depends on your use case, hardware, latency, and accuracy requirements.
Reasoning models are designed to provide more accurate answers to complex tasks such as coding or solving math problems. DeepSeek made a splash releasing their open source R1 reasoning model in January.
The open source DeepSeek models are distillations of the Qwen or Llama models. Distillation is training a smaller, more efficient model to mimic the behavior and knowledge of a larger, more complex model. Let’s pit the distilled version against the original here and see how they stack up.
In this post, we’ll use small versions of these models (deepseek-r1:1.5b and qwen:1.8b) to make this tutorial accessible and fast for those without access to advanced hardware. Feel free to try whatever models best suit your needs as you follow along.
Installing and configuring Ollama
Head to the Ollama download page. Follow the instructions for your operating system of choice.
To install our first model and start it running, type the following command in your terminal:
Let’s run a test query to ensure that Ollama can generate results. At the prompt, type a question:
To exit the Ollama prompt, use the /bye command.
Follow the same process to install qwen:1.8b:
Although you have exited the terminal process, Ollama is still running in the background via a Docker image. That lets us run code that queries the models we’ve downloaded. Next we’ll create a Node.js project that connects with Ollama.
Connecting Ollama with a Node.js project
Run the following commands to set up a new Node.js project:
Open package.json in your editor. Copy the following into package.json and then save the file.
Install dependencies:
Create a new file named testQuery.js. Enter the following code:
Run this script to verify that local inference is working.
You should see terminal output that answers the question:
Adding a custom model to AgentControl
Head over to the model configuration page on LaunchDarkly UI. Click the Add AI model config button. Fill out the form using the following configuration:
- Name: deepseek-r1:1.5b
- Provider: DeepSeek
- Model ID: deepseek-r1:1.5b
Model ID represents how you intend to refer to the model in your code. Name is how the model will show up in the LaunchDarkly UI. If you are using a model with one of those terribly long gobbledygook names like llama-mama-10-gajillion-u234oiru32-preview-instrukt-latest, giving it a shorter, human readable Name might make your dashboard more legible. In this case, we’re sticking with deepseek-r1:1.5b since it’s relatively short and clear. Click Save.
Click the Add AI model config button again to add the second model.
- Name: qwen:1.8b
- Provider: Custom (Qwen)
- Model ID: qwen:1.8b
Click Save.
Next, we’ll create the config variation representing the prompt and model combinations that we can swap out at runtime. Variations are editable and versioned, so it’s okay to make mistakes. Click the Create button, and select AgentControl config from the menu.
Enter “model-showdown” in the config name field. Click Create. Configure the next page like so:
- Name: deepseek-r1:1.5b
- Model: deepseek-r1:1.5b
- Role: User. (DeepSeek reasoning models aren’t optimized for System prompts.)
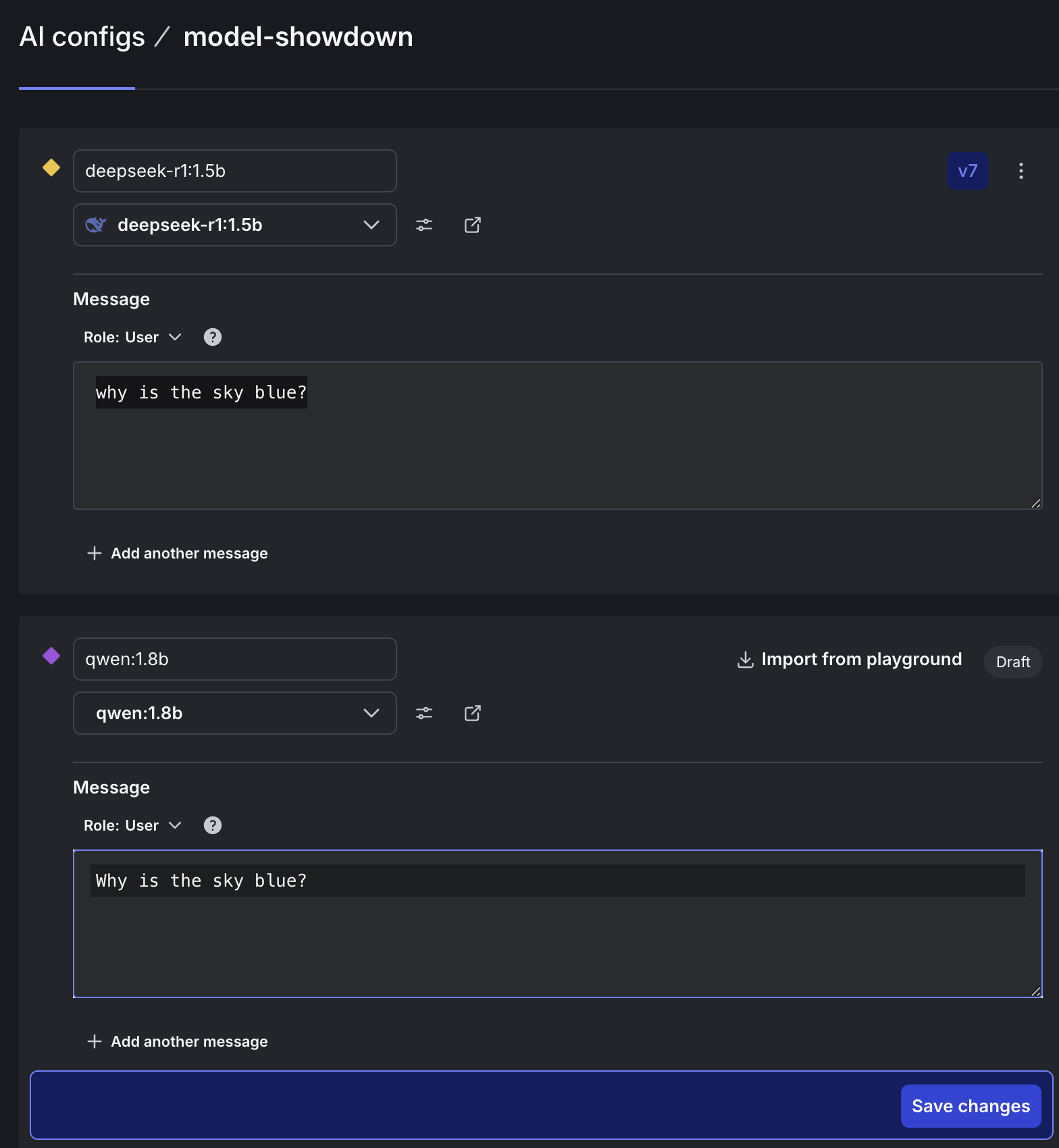
- Message: Why is the sky blue?
Save changes. To use qwen:1.8b, click Add another variation. Variations record metrics separately. In order to measure how each model performs, we need one variation per model. To compare fairly between models, keep the prompt the same in both variations. When you’re done, Save changes.
- Name: qwen:1.8b
- Model: qwen:1.8b
- Role: User
- Message: Why is the sky blue?
On the Targeting tab, edit the default rule to serve the deepseek-r1:1.5b variation. Click the toggle to enable the config. Click Review and save.
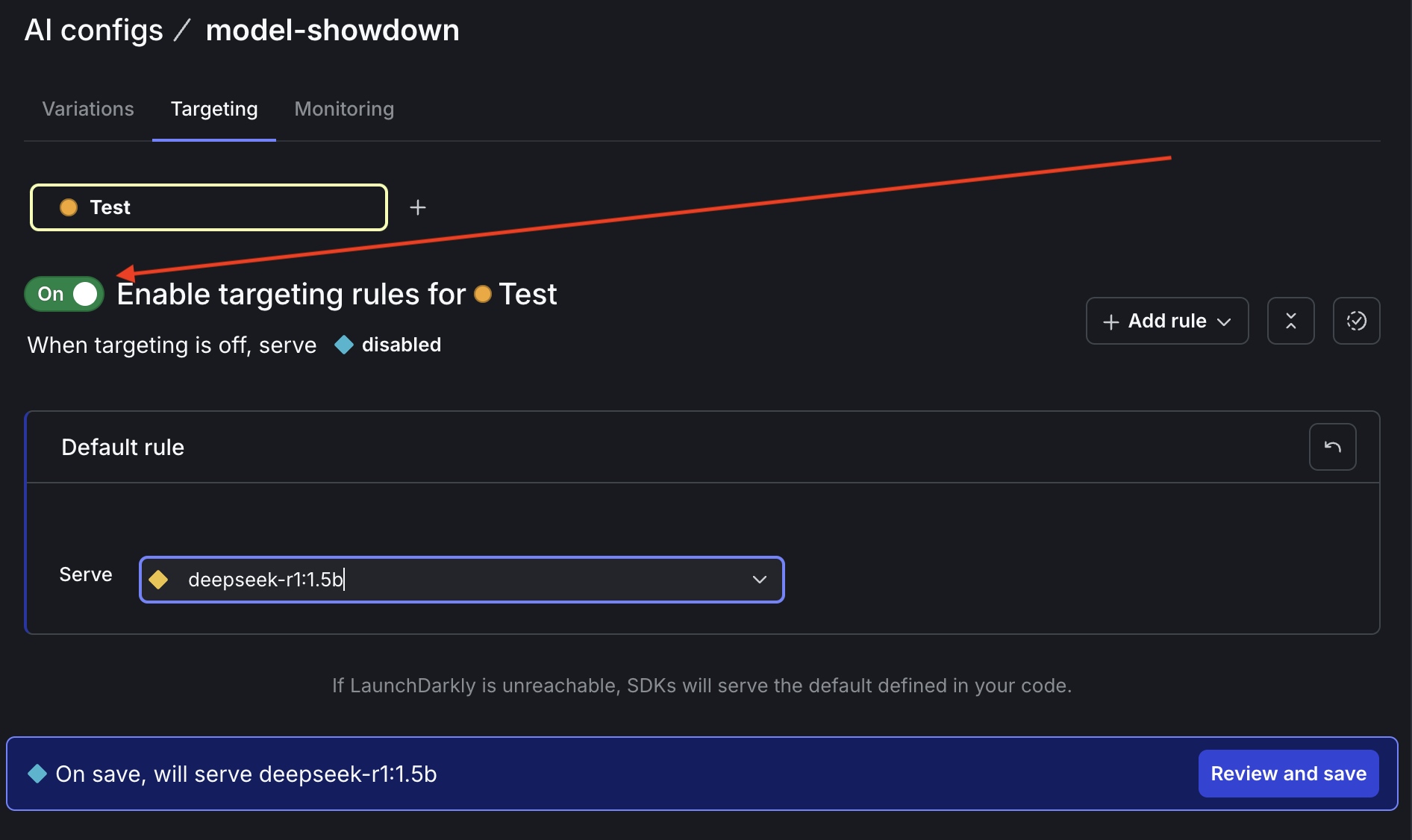
If your LaunchDarkly permissions require it, enter a comment to explain these changes.
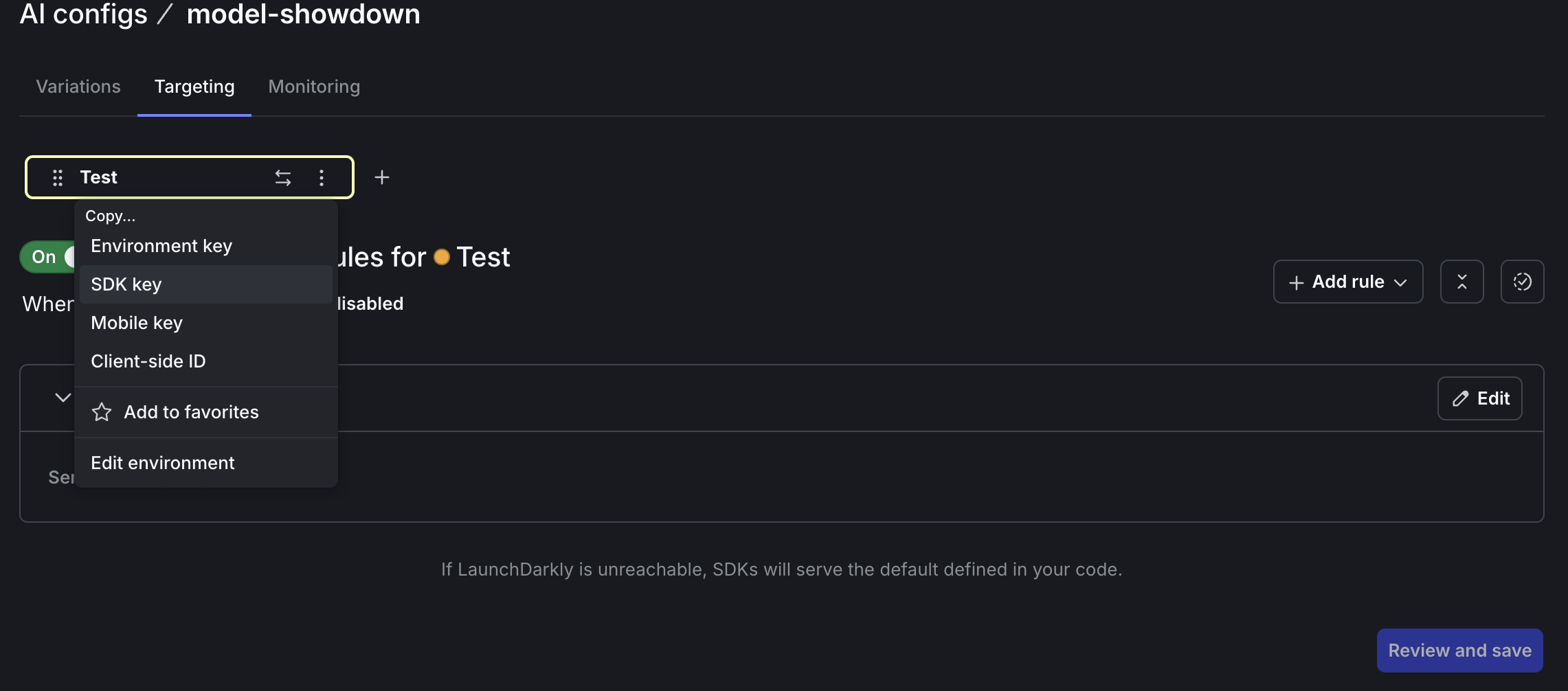
There’s one more configuration step. On the … dropdown next to the Test environment on the Targeting tab, select SDK key to copy your SDK key to the clipboard.
Create an .env file at the root of your project. Paste the following line in, replacing “YOUR KEY HERE” with your actual key.
Save the .env file.
Connecting AgentControl to Ollama
Back in your Node project, create a new file named generate.js. Add the following lines of code:
Run this code using node generate.js in your terminal. Output should show the response comes from deepseek-r1:1.5b.
Cool! Let’s try the other model. Back in the LaunchDarkly UI, edit your default rule for the model-showdown config to serve the qwen:1.8b model. Save changes.
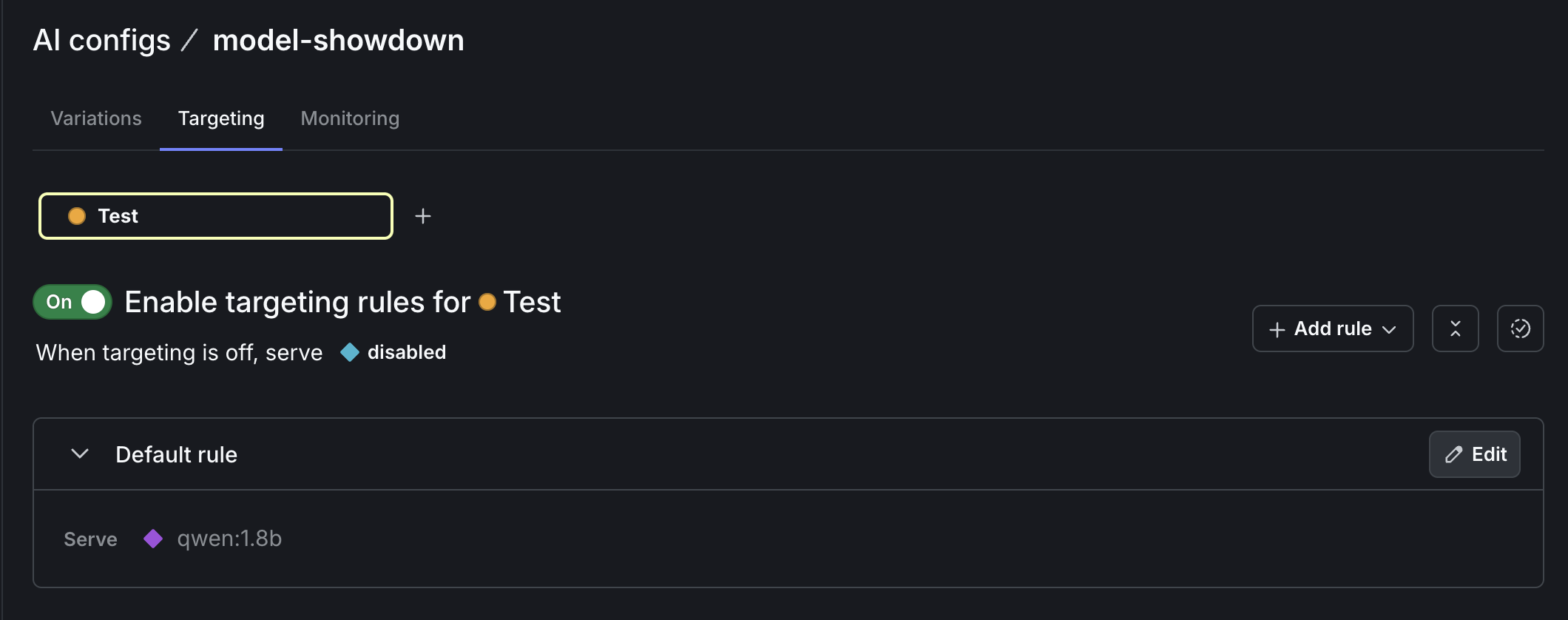
Rerun generate.js and you’ll see the response from qwen:1.8b:
Some other queries you can try to test reasoning models’ capabilities:
- What is 456 plus 789?
- What is the color most closely matching this HEX representation: #8002c6 ?
Google maintains an awesome list of questions to evaluate reasoning models on GitHub. You’ll get the most applicable results if you stick to questions that are close to your use case.
When we call trackMetrics in our app, the data we send is visualized in the Monitoring tab on the LaunchDarkly app. Our code tracks input and output tokens, request duration, and how many times each model was called (generation count).
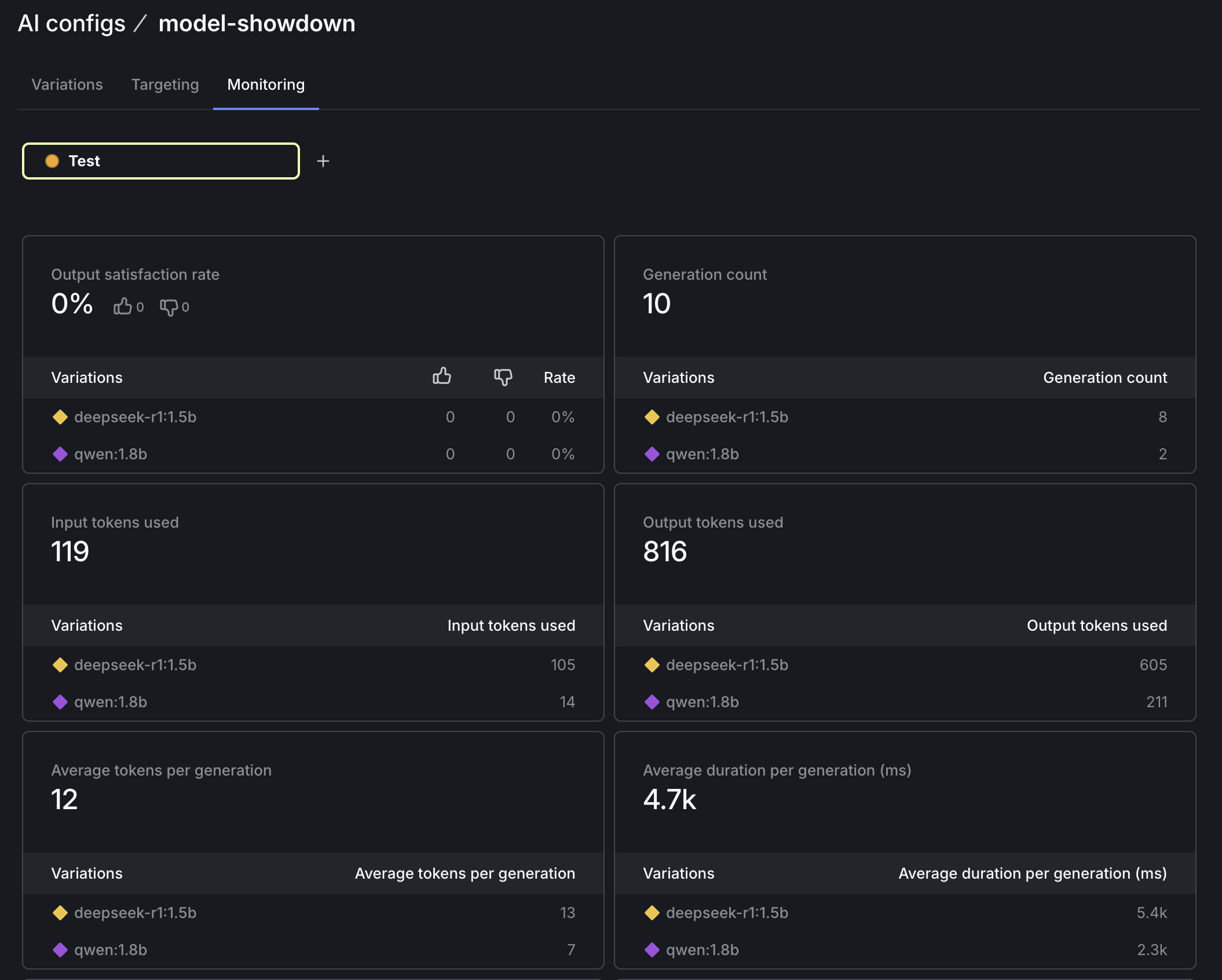
Wrapping it up: bring your own model, track your own metrics, take the next steps
In this tutorial you’ve learned how to run large language models locally with Ollama and query the results from a Node.js application. Furthermore, you’ve created a custom model config with LaunchDarkly that tracks metrics such as latency, token usage, and generation count.
There’s so much more we could do with AgentControl on top of this foundation.
One upgrade would be to add additional metrics. For example, you could track output satisfaction and let users rate the quality of the response. If you are using LLMs in production, AgentControl even supports running A/B tests and other kinds of experiments to determine which variation performs the best for your use case using the power of statistics.
AgentControl also has advanced targeting capabilities. For example, you could use a more expensive model for potentially high-value customers with enterprise-y email addresses. Or you could give users a more linguistically localized experience by serving them a model trained in the language specified in their accept-lang header.
If you want to learn more about runtime model management, here’s some further reading:
- Compare AI Models in Python Flask Applications — Using AgentControl
- Upgrade OpenAI models in ExpressJS applications — using AgentControl
Thanks so much for following along. Hit me up on Bluesky if you found this tutorial useful. You can also reach me via email (tthurium@launchdarkly.com), Discord, or LinkedIn.