Day 2 | 🎅 He knows if you have been bad or good… But what if he gets it wrong?
Day 2 | 🎅 He knows if you have been bad or good… But what if he gets it wrong?
Published December 09, 2025

“He knows if you’ve been bad or good…”
As kids, we accepted the magic. As engineers in 2025, we need to understand the mechanism. So let’s imagine Santa’s “naughty or nice” system as a modern AI architecture running at scale. What would it take to make it observable when things go wrong?
The architecture: Santa’s distributed AI system
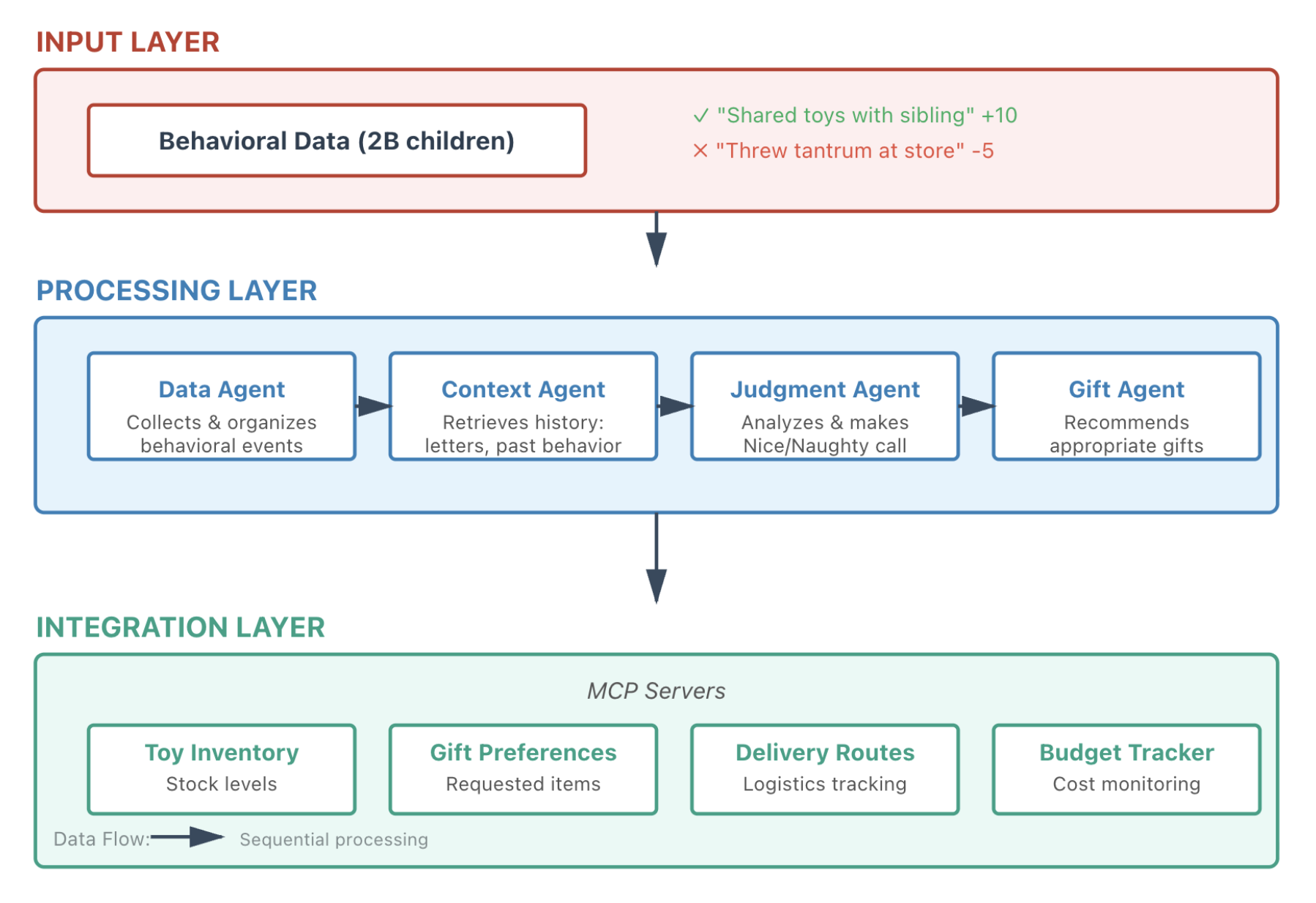
Santa’s operation would need three layers. The input layer handles behavioral data from 2 billion children on a point system. “Shared toys with siblings” gets +10 points, “Threw tantrum at store” loses 5.
The processing layer runs multiple AI agents working together. A Data Agent collects and organizes behavioral events. A Context Agent retrieves relevant history: letters to Santa, past behavior, family situation. A Judgment Agent analyzes everything and makes the Nice/Naughty determination. And a Gift Agent recommends appropriate presents based on the decision.
The integration layer connects to MCP servers for Toy Inventory, Gift Preferences, Delivery Routes, and Budget Tracking.
It’s elegant. It scales. And when it breaks, it’s a nightmare to debug.
The Problem: A good child on the Naughty List
It’s Christmas Eve at 11:47 PM.
A parent calls, furious. Emma, age 7, has been a model child all year. She should be getting the bicycle she asked for. Instead, the system says: Naughty List - No Gift.
You pull up the logs:
Emma wasn’t naughty. The Toy Inventory MCP was overloaded from Christmas Eve traffic. But the agent’s reasoning chain interpreted three timeouts as “this child’s request cannot be fulfilled” and failed to the worst possible default.
With traditional APIs, you’d find the bug on line 47, fix it, and deploy. With AI agents, it’s not that simple. The agent decided to interpret timeouts that way. You didn’t code that logic. The LLM’s 70 billion parameters did.
This is the core challenge of AI observability: You’re debugging decisions, not code.
Why AI Systems are hard to debug
Black box reasoning and reproducibility go hand in hand. With traditional debugging, you step through the code and find the exact line that caused the problem. With AI agents, you only see inputs and outputs. The agent received three timeouts and decided to default to NAUGHTY_LIST. Why? Neural network reasoning you can’t inspect.
And even if you could inspect it, you couldn’t reliably reproduce it. Run Emma’s case in test four times and you might get:
Temperature settings and sampling introduce randomness. Same input, different results every time. Traditional logs show you what happened. AI observability needs to show you why, and in a way you can actually verify.
Then there’s the question of quality. Consider this child:
- Refused to eat vegetables (10 times) but helped put away dishes
- Yelled at siblings (3 times) but defended a classmate from a bully
- Skipped homework (5 times) but cared for a sick puppy
Is this child naughty or nice? The answer depends on context, values, and interpretation. Your agent returns NICE (312 points), gift = books about empathy. A traditional API would return 200 OK and call it success. For an AI agent, you need to ask: Did it judge correctly?
Costs can spiral out of control. Mrs. Claus (Santa’s CFO) sees the API bill jump from 5,000 in Week 1 to 890,000 on December 24th. What happened? One kid didn’t write a letter. They wrote a 15,000-word philosophical essay. Instead of flagging it, the agent processed every last word, burning through 53,500 tokens for a single child. At scale, this bankrupts the workshop.
And failures cascade in unexpected ways. The Gift Agent doesn’t just fail when it hits a timeout. It reasons through failure. It interpreted three timeouts as “system is unreliable,” then saw the inventory count change and concluded “inventory is volatile, cannot guarantee fulfillment.” Each interpretation fed into the next, creating a chain of reasoning that led to: “Better to disappoint than make a promise I can’t keep. Default to NAUGHTY_LIST.”
With traditional code, you debug line by line. With AI agents, you need to debug the entire reasoning chain. Not just what APIs were called, but why the agent called them and how it interpreted each result.
What Santa Actually Needs
The answer isn’t to throw out traditional observability, but to build on top of it. Think of it as three layers.
This is exactly what we’ve built at LaunchDarkly. Our platform combines AI observability, online evaluations, and feature management to help you understand, measure, and control AI agent behavior in production. Let’s walk through how each layer works.
Start with the fundamentals. You still need distributed tracing across your agent network, latency breakdowns showing where time is spent, token usage per request, cost attribution by agent, and tool call success rates for your MCP servers. When the Toy Inventory MCP goes down, you need to see it immediately. When costs spike, you need alerts. This isn’t optional. It’s table stakes for running any production system.
For Santa’s workshop, this means tracing requests across Data Agent → Context Agent → Judgment Agent → Gift Agent, monitoring MCP server health, tracking token consumption per child evaluation, and alerting when costs spike unexpectedly. It’s important to note, LaunchDarkly’s AI observability captures all of this out of the box, providing full visibility into your agent’s infrastructure performance and resource consumption.
Then add semantic observability. This is where AI diverges from traditional systems. You need to capture the reasoning, not just the results. For every decision, log the complete prompt, retrieved context, tool calls and their results, the agent’s reasoning chain, and confidence scores.
When Emma lands on the Naughty List, you can replay the entire decision. The Gift Agent received three timeouts from the Toy Inventory MCP, interpreted “inventory uncertain” as “cannot fulfill request,” and defaulted to NAUGHTY_LIST as the “safe” outcome. Now you understand why it happened. And more importantly, you realize this isn’t a bug in your code. It’s a reasoning pattern the model developed. Reasoning patterns require different fixes than code bugs.
LaunchDarkly’s trace viewer lets you inspect every step of the agent’s decision-making process, from the initial prompt to the final output, including all tool calls and the reasoning behind each step.
Finally, use online evals. Where observability shows what happened, online evals automatically assess quality and take action. Using the LLM-as-a-judge approach, you score every sampled decision. One AI judges another’s work:
This changes the conversation from vague to specific.
Without evals: “Let’s meet tomorrow to review Emma’s case and decide if we should rollback.”
With evals: “Accuracy dropped below 0.7 for the ‘timeout cascade defaults to NAUGHTY’ pattern. Automatic rollback triggered. Here are the 23 affected cases.”
LaunchDarkly’s online evaluations run continuously in production, automatically scoring your agent’s decisions and alerting you when quality degrades. You can define custom evaluation criteria tailored to your use case and set thresholds that trigger automatic actions.
This is where feature management and experimentation come in. Feature flags paired with guarded rollouts let you control deployments and roll back bad ones. Experimentation lets you A/B test different approaches. With AI agents, you’re doing the same thing, but instead of testing button colors or checkout flows, you’re testing prompt variations, model versions, and reasoning strategies. When your evals detect accuracy has dropped below threshold, you automatically roll back to the previous agent configuration.
Use feature flags to control which model version, prompt template, or reasoning strategy your agents use and seamlessly roll back when something goes wrong. Our experimentation platform lets you A/B test different agent configurations and measure which performs better on your custom metrics. Check out our guide on feature flagging AI applications.
You’re not just observing decisions. You’re evaluating quality in real-time and taking action.
Debugging Emma: all three layers in action
Traditional observability shows the Toy Inventory MCP experienced three timeouts that triggered retry logic. Token usage remained average. From an infrastructure perspective, nothing looked catastrophic.
Semantic observability reveals where the reasoning went wrong. The Gift Agent interpreted the timeouts as “inventory uncertain” and made the leap to “cannot fulfill requests.” Rather than recognizing this as a temporary system issue, it treated the timeouts as a data problem and defaulted to NAUGHTY_LIST.
Online evals reveal this isn’t just a one-off problem with Emma, but a pattern happening across multiple cases. The accuracy judge flagged this decision at 0.3, well below acceptable thresholds. Querying for similar low-accuracy decisions reveals 23 other cases where timeout cascades resulted in NAUGHTY_LIST defaults.
Each layer tells part of the story. Together, they give you everything you need to fix it before more parents call.
With LaunchDarkly, all three layers work together in a single platform. You can trace the infrastructure issue, inspect the reasoning chain, evaluate the decision quality, and automatically roll back to a safer configuration, all within minutes of Emma’s case being flagged.
Conclusion
Every AI agent system faces these exact challenges. Customer service agents making support decisions. Code assistants suggesting fixes. Content moderators judging appropriateness. Recommendation engines personalizing experiences. They all struggle with the same problems.
Traditional observability tools weren’t built for this. AI systems make decisions, and decisions need different observability than code.
Santa’s system says “He knows if you’ve been bad or good.” But how he knows matters. Because when Emma gets coal instead of a bicycle due to a timeout cascade at 11:47 PM on Christmas Eve, you need to understand what happened, find similar cases, measure if it’s systematic, fix it without breaking other cases, and ensure it doesn’t happen again.
You can’t do that with traditional observability alone. AI agents aren’t APIs. They’re decision-makers. Which means you need to observe them differently.
LaunchDarkly provides the complete platform for building reliable AI agent systems: observability to understand what’s happening, online evaluations to measure quality, and feature management to control and iterate safely. Whether you’re building Santa’s naughty-or-nice system or a production AI application, you need all three layers working together.
Ready to make your AI agents more reliable? Start with our AI quickstart guide to see how LaunchDarkly can help you ship AI agents with confidence.