




When your GenAI app confidently says something wrong, it doesn’t just frustrate the user; it undermines the entire product experience. It creates friction, doubt, and in some industries, real risk. Beyond just losing the users’ trust, you risk losing their business.
Hallucinations aren't just an LLM problem anymore. They’re a runtime problem, a delivery problem, and a product trust problem.
We hear this from builders all the time: “I know my model might hallucinate, but I need to know when it happens, how bad it is, and what I can do about it, especially when the app is live.”
The challenge is in knowing how to catch hallucinations in production, understand their root cause, and respond with urgency and precision. For that, you need proper visibility and runtime control.
In this post, we’ll walk through three ways teams are solving hallucinations in production environments, and how LaunchDarkly AI Configs helps operationalize those strategies safely and repeatably.
1. Ground responses with RAG
Retrieval-Augmented Generation (RAG) is one of the easiest ways to customize an AI application. It works by injecting curated context from your company’s knowledge base into each prompt, allowing the model to provide relevant answers to real-world questions, grounded in documentation, database content, or other knowledge sources, decreasing the probability of the model producing false or misleading information.
But context injection alone isn’t enough. RAG configurations can silently degrade. Vector searches can start retrieving the wrong data source. Relevance rankings shift. One day, your model is answering with precise context, and the next, it’s citing a 2-year-old document because your vector DB hasn’t been refreshed.
With AI Configs, teams can:
- Track which knowledge base or RAG DBs are live per model or user segment
- Run experiments with different vector sources or chunk/window sizes
- Compare satisfaction and factuality side-by-side to find the right balance
This makes RAG more observable and more resilient.
2. Catch risky outputs with guardrails
Even with good grounding, GenAI models still hallucinate, especially on edge cases or open-ended prompts. That’s where output-level guardrails come in.
Guardrail tools (like AWS Guardrails, Azure Content Safety, or custom moderation layers) act as a last-mile filter. They scan responses for:
- Personally identifiable information (PII)
- Toxicity, bias, or ethical violations
- Non-compliant or unsupported claims
But to work well in prod, they can’t just be glued on. They have to be part of your AI delivery stack.
With AI Configs, teams can:
- Build guardrail logic directly into the runtime config: model + prompt + filter
- Target different safety rules for different user types, apps, or regions
- Auto-disable responses or flip to fallback behavior if something risky gets flagged
It’s important to block harmful outputs. The goal is to do so without slowing teams down.
3. Use AI to fact-check AI in real time
Many teams now use a second model to evaluate the output of the first. Sometimes referred to as “LLM-as-judge,” this pattern employs a scoring model to evaluate the factuality, alignment, or usefulness of a response before it is logged or sent.
This might sound like a luxury, but it’s becoming more common, especially when:
- You’re comparing multiple models in production
- You’re deploying to end users in sensitive workflows
- You’re trying to build an internal scorecard for model reliability
Teams often:
- Route responses through a scoring model (like Sonnet 4) for factuality and relevance
- Compare outputs from multiple models using the same inputs
- Log and analyze results alongside latency, satisfaction, and cost
This builds a feedback loop that’s fast enough to act on.
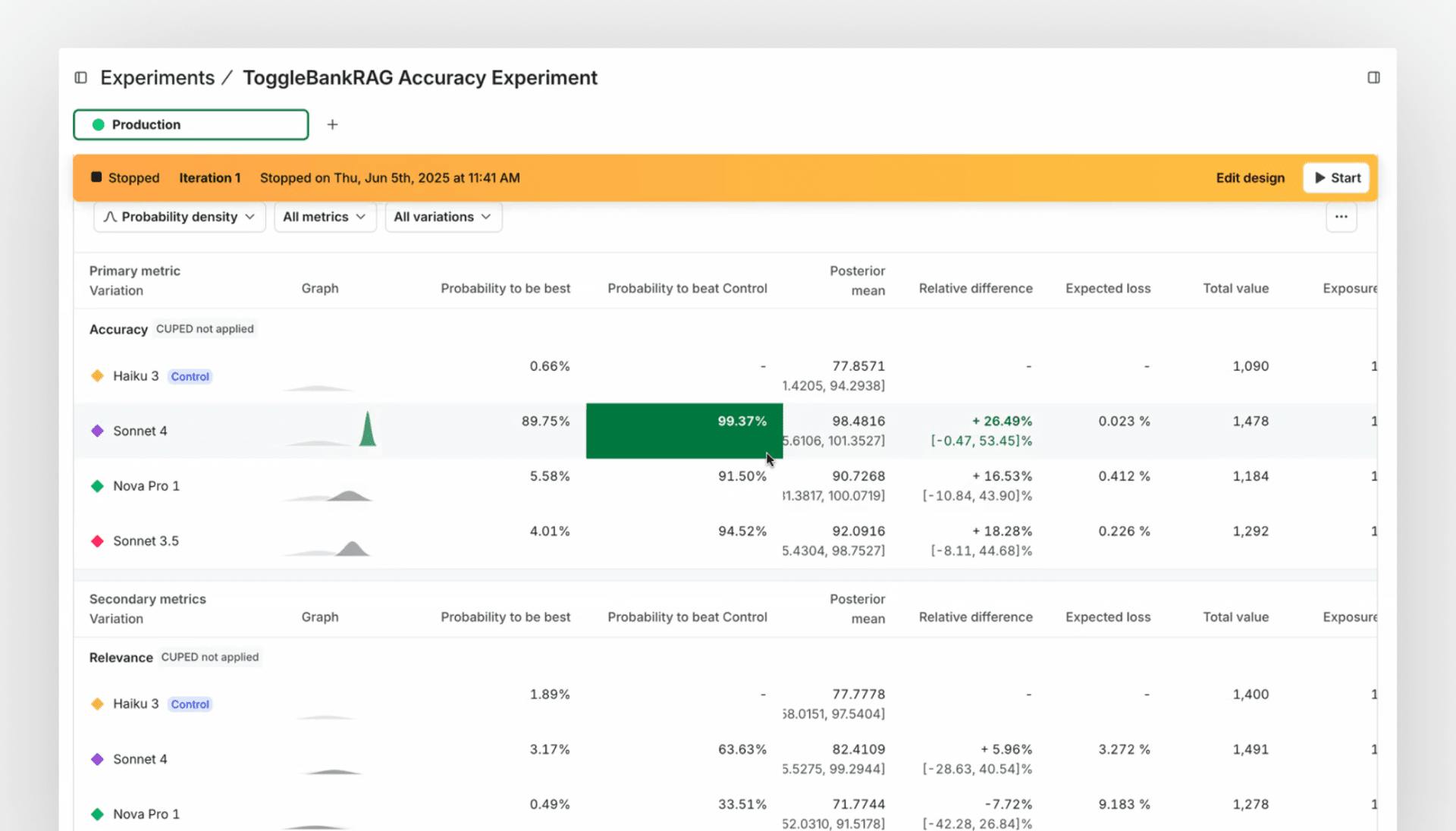
Real-world example: Claude 4 Sonnet vs. Opus
Imagine you're deploying a lightweight model like Anthropic’s Haiku to summarize support tickets and technical documentation for internal use. You’re using RAG to ground responses with content from your knowledge base, but you still want a way to verify that what the model says is accurate.
To test this setup, your team uses LaunchDarkly AI Configs to route a subset of Haiku responses (along with their retrieved context) through a second model—Claude Sonnet—acting as a real-time factuality judge.
Sonnet scores each response on how well it aligns with the source material. That score is sent back into LaunchDarkly, where it becomes both:
- A custom metric in an experiment (comparing different RAG implementations or model configs)
- A runtime threshold used to automatically adjust targeting or trigger a rollback if factuality drops below a certain level
At the same time, you’re routing a portion of traffic through a guardrails provider that flags outputs for sensitive content (like PII or toxicity). If a response is flagged, LaunchDarkly can roll back to a safer fallback config without redeploying.
With AI Configs, you can:
- Run parallel tests across prompt + model + context variations
- Score each response using LLM-as-judge and safety filters
- Automate targeting or rollback based on factuality or guardrail signal
All of this happens at runtime, with full visibility into performance, safety, and user impact, without slowing down delivery.
What to measure
When you’re live in production, it’s as much about accuracy as it is balance. The best teams track both quality and experience:
Qualitative Metrics:
- Factuality (from LLM-as-judge)
- Relevance or coherence (from scoring or human feedback)
- Grounding fidelity (especially if using RAG)
Operational Metrics:
- Latency per model and config
- Cost per response or call
- Negative feedback rate (thumbs down, user drop-off, etc.)
AI Configs enables teams to track these in production and set thresholds that automatically drive behavior, such as triggering a rollback or pausing a config.
Build AI you can trust, even when it’s imperfect
No model is hallucination-free. That’s not the goal. What matters is whether your team can detect, respond, and improve, especially when you’re in production. LaunchDarkly AI Configs gives you the control to test, monitor, and optimize AI behavior in real time without slowing your team down. Let’s build better AI together!
Interested in trying out AI Configs? Start your free trial.
If you have questions, reach out to us at aiproduct@launchdarkly.com.
Like what you read?
Get a demo