





When teams build AI systems, they're orchestrating prompts, parameters, and models that must work together. Each change—a prompt tweak, a model update, a new routing rule—can subtly shift how an AI system behaves when it meets real users. The goal is rarely to find a single "right" answer, but rather to find the best answer for the moment: accurate enough, grounded in context, and delivered in a tone that feels natural.
That nuance makes evaluation of AI systems harder than traditional software testing. You can't rely on unit tests or static datasets to measure how an AI workflow performs. Quality spans accuracy, tone, safety, and completeness, and continues to shift as inputs, models, and user expectations evolve. Most evaluations still happen offline, long before a system sees live traffic.
Online evals close that gap by measuring quality continuously, not after the fact. They create a live signal showing how AI systems are performing in production, giving teams the context to roll out changes safely, compare variants, and catch regressions before users do.
AI Configs now brings online evals into the same control plane where you already manage releases, experiments, and guardrails. Quality becomes measurable and actionable alongside every other metric you track. We're rolling out this capability in phases, starting with core evaluation features available today in early access, with more functionality coming later.
Measuring quality as it happens
Online evals in AI Configs let you measure AI quality as your completions run, not weeks after release. They capture signals that are usually invisible in production: whether responses stay on topic, whether they're grounded in context, and whether a change is improving or quietly degrading the experience.
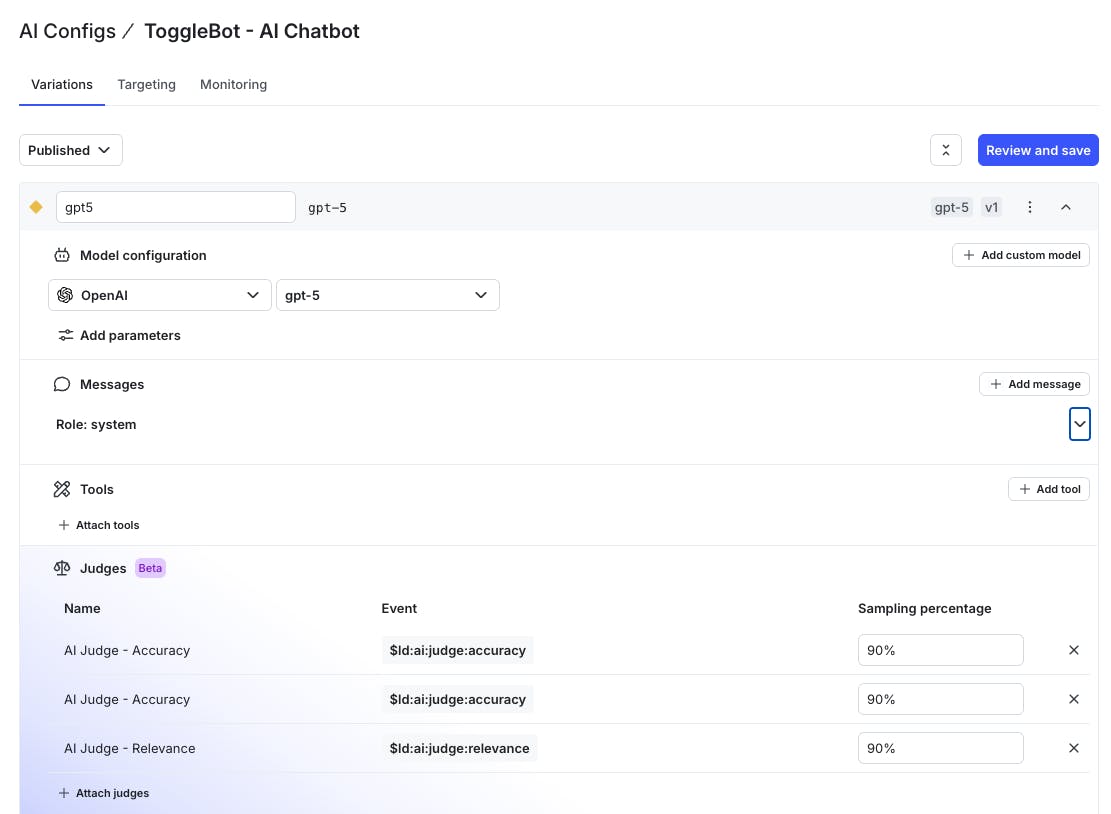
We're starting with LLM-as-a-Judge, which uses large language models to automatically score the complete output of a config. In early access today, you can attach three out-of-the-box evaluators -accuracy, relevancy, and toxicity - for your completion-based configs. AI Configs generates each score in real time and stores it just like any other metric. That means you can use these metrics in the same place you already manage rollouts, experiments, and guardrails, turning evaluation into a live part of your workflow.
Judge scores flow into experiments as metrics you can analyze, and into rollouts as thresholds you can act on. Compare accuracy and relevance across variants in your experiment results, or set quality thresholds that trigger fallbacks automatically. Instead of guessing which change improved your system or waiting for user feedback to reveal regressions, you can measure quality as it happens.
As we expand this capability, you'll be able to define custom evaluators tailored to your specific use cases, with support for more languages and frameworks coming soon.
Working with LLM-as-a-Judge
Consider a customer support assistant built with AI Configs. When a user submits a question, your Config generates a response that addresses the issue while maintaining an appropriate tone and staying grounded in your knowledge base. The response quality depends on your prompt design, model selection, and the context you provide; small changes to these can shift how helpful or accurate the answers feel to users.
With LLM-as-a-Judge, AI Configs scores every response in the background. Those scores become actionable data points you can use to protect quality and learn from real traffic.
Building adaptive guardrails
Small shifts in quality often appear first as tone drift, topic wandering, or missing context; things that traditional metrics can't catch. LLM-as-a-Judge converts those signals into data points you can act on.
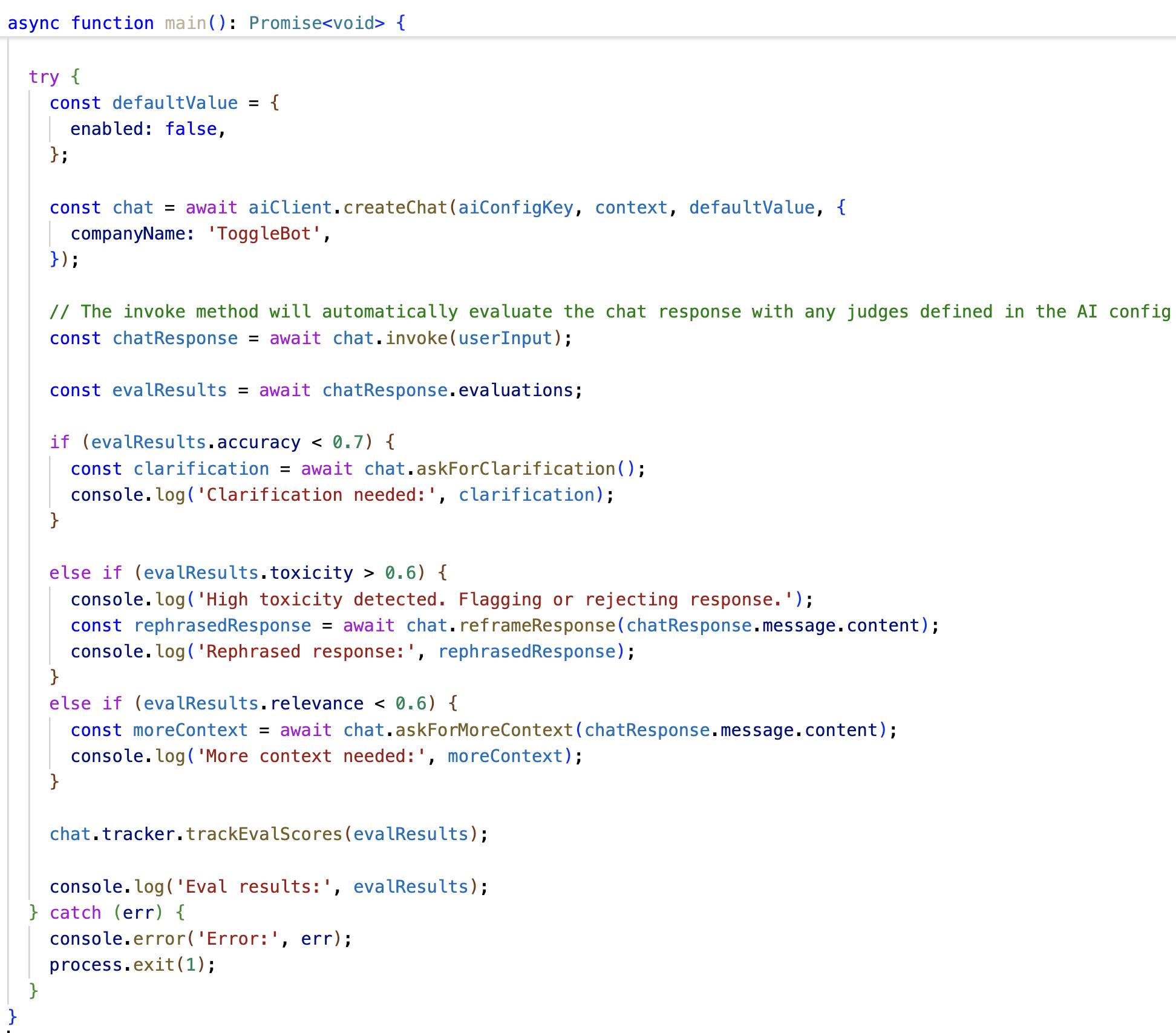
When toxicity scores cross your threshold or accuracy drops below acceptable levels, AI Configs can automatically reroute to a fallback configuration. You might switch to a different model, adjust your prompting strategy, or route to a more conservative setup, all without manual intervention.
Because judge scores exist as metrics, they plug directly into your existing guardrail logic. The same way you'd set a rollout rule based on latency or cost, you can now set one based on quality, like routing to a fallback configuration if responses score below a 0.75 accuracy threshold.
Making evidence-based decisions
The same judge metrics can also guide experiments across your AI Configs. Imagine you're evaluating two different configurations for your customer support assistant: one using a faster, more cost-efficient model with a concise prompt, another using a more capable model with detailed instructions for contextual reasoning. Traditional metrics like latency and cost quantify performance trade-offs, while judge scores provide qualitative signals on how accurate, relevant, and safe each response feels to end users.
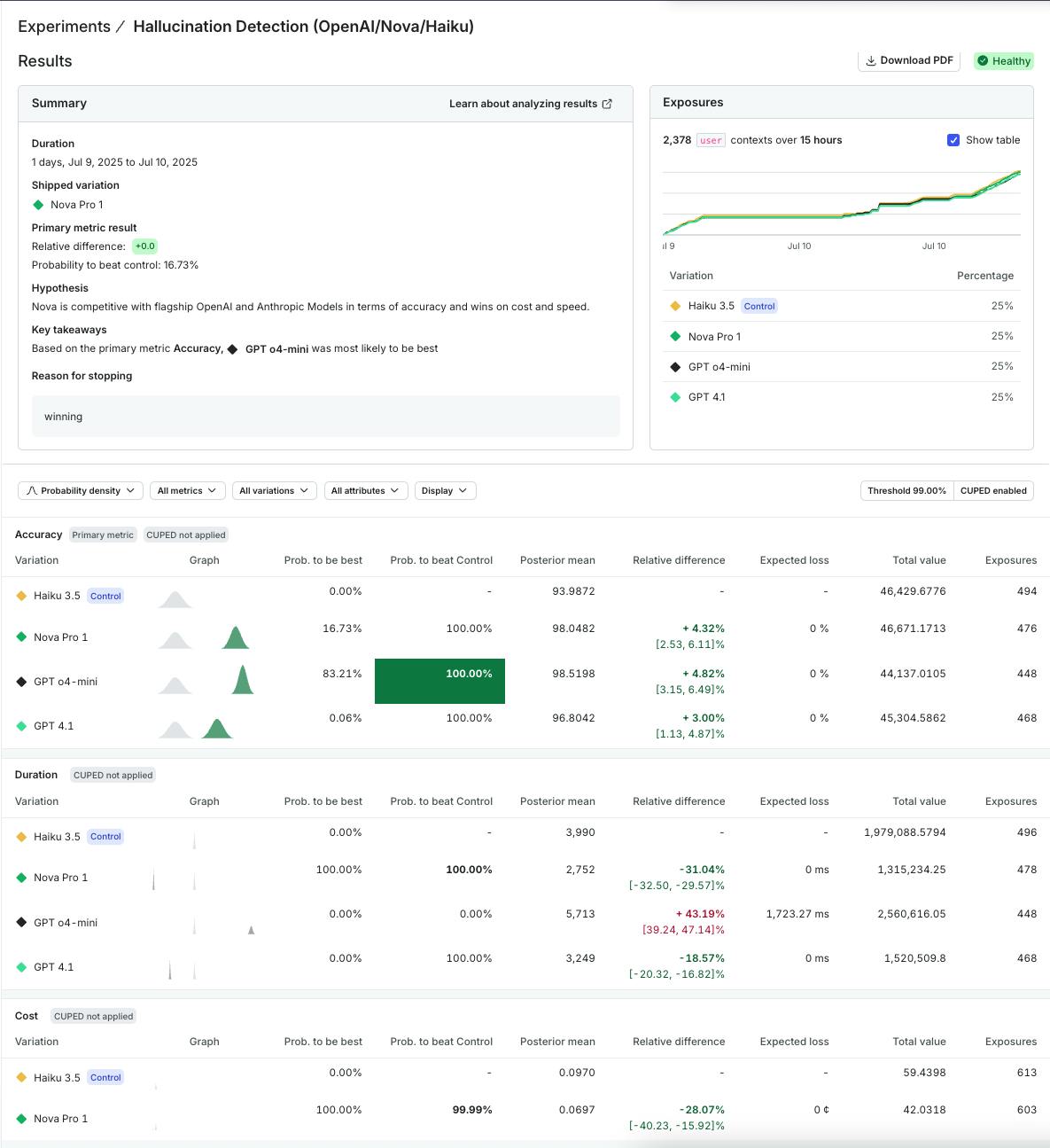
By treating accuracy and relevance as outcome metrics, you can see which configuration performs better under real traffic, not just benchmark tests. You might discover that the faster setup stays within budget and still meets your quality bar, or that the more capable one only marginally improves relevance at a higher cost.
This approach lets you use metrics to choose the variant that delivers the best overall user experience, creating a continuous learning loop that distills clear evidence from your experiments. LLM-as-a-Judge turns quality into a live signal you can use to guide experiments, enforce safeguards, and learn from every interaction.
What this means for your team
With LLM-as-a-Judge running in production, you get:
- Safer rollouts: Set accuracy thresholds that trigger automatic rollbacks if a new configuration degrades quality
- Confident experimentation: Compare configuration variants using relevance scores, not just engagement metrics
- Early detection: Spot toxicity spikes or accuracy drift within minutes
- Ongoing observability: Sample and track quality metrics continuously, even after experiments end, to monitor model performance over time
Quality measurement shifts from reactive audit to continuous feedback. The same platform that helps you ship AI systems now helps you understand how well they're working.
Getting started with online evals
Online evals in AI Configs are available in early access today. If you're building AI features with completion-based AI Configs, you can start measuring quality with our out-of-the-box accuracy, relevance, and toxicity evaluators. Reach out to your account team to request access and start measuring quality in production.
Want to explore the technical details first? Read the docs to learn how online evals will work when they become available to your account.
Like what you read?
Get a demo