





Traditional observability has always focused on performance metrics: latency, errors, throughput, and cost. But as AI and large language models move into production, those signals alone don’t tell the full story. Fast responses can still be wrong, and stable infrastructure can still deliver unpredictable results.
LaunchDarkly now brings LLM observability directly into AI Configs, helping teams connect model behavior to real production outcomes. It replaces guesswork with traceable causes, so regressions can be rolled back quickly.
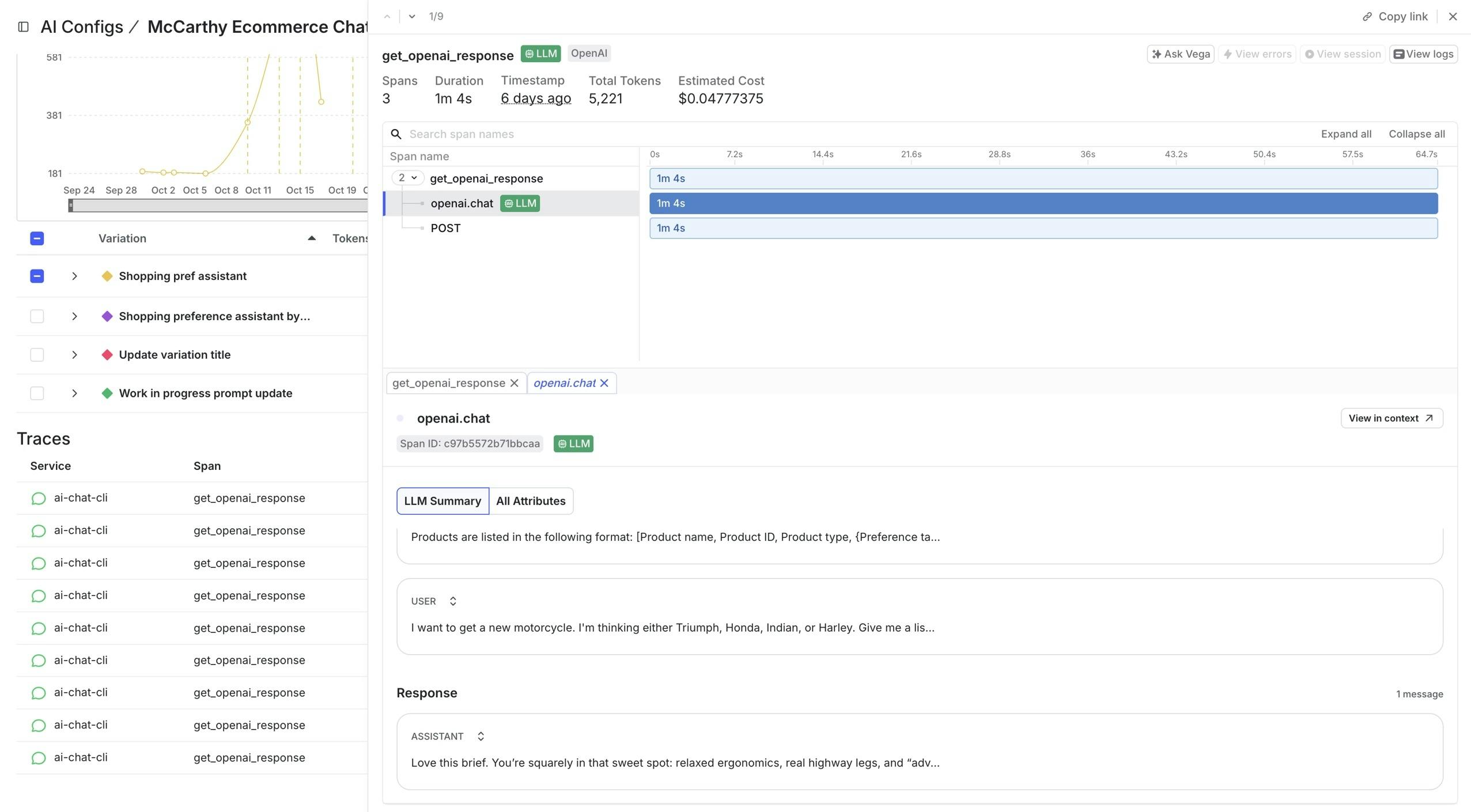
For example, an e-commerce team might reroute requests from one model provider to another to reduce cost, only to see a spike in spending despite healthy infrastructure metrics. Observability within AI Configs helps pinpoint the cause, revealing, for instance, a prompt change that increased token usage.
With LLM spans highlighted on the traces page and an LLM summary provided in the trace details, teams can connect performance shifts to the prompts, models, and parameters behind them. This gives teams a direct way to diagnose and understand LLM-specific behavior more easily.
Monitoring meets understanding
LLM observability inside AI Configs bridges insight and action by connecting performance data with the model context behind it. Teams can view the prompts, parameters, and responses responsible for a change directly alongside the metrics that quantify its impact.
For instance, when a support agent adds a new tool call to a billing API, the trace and span view ties timeouts and misrouted escalations directly to that update, making rollback decisions straightforward.
This tighter feedback loop brings iteration and observability together in one workflow. Teams can trace a performance regression back to a specific configuration, adjust a parameter or prompt, and then watch the results unfold, all within AI Configs. It’s a step toward an end-to-end platform where building, releasing, and understanding AI systems happen in one place.
What LLM observability captures
LLM observability provides insight into:
- Prompts, parameters, and tool calls used during completions
- Model responses, latency, token usage, and cost per call
- The model and provider version responsible for each completion
- Execution flow within traces where AI spans are present
Together, these details provide a clearer picture of how AI systems operate in production, from the first request to the final response, and make it easier to pinpoint where results begin to diverge from expectations.
Why this matters as AI scales
As AI systems grow more complex, visibility becomes essential. Small variations in context, sequence, or temperature can create large differences in outcome. LLM observability highlights these relationships, giving teams guidance to diagnose issues, manage costs, and maintain reliability as complexity increases.
This capability strengthens the observability foundation in AI Configs, combining quantitative system health with qualitative AI behavior. It deepens understanding of how models and agents perform under real-world conditions; insight that’s critical as organizations scale AI across products and customers.
As AI becomes a core part of business strategy, legacy monitoring tools can’t keep pace with its complexity or speed. With AI Configs, teams gain the visibility and control needed to ship AI experiences confidently and turn that reliability into a competitive advantage.
Learn more about LLM observability in our documentation, or explore observability features through a free trial.
Like what you read?
Get a demo