





As I prepared for my most recent Tech Talk (Ask the Experimentation Expert), I had an interesting conversation with our incredible product lead about our recently-launched Multi-Armed Bandit capability, and about how MABs can help teams find and ship optimal experiences more quickly.
He pointed out how Multi-Armed Bandits, paired with our ability to run multiple experiments on the same feature flag simultaneously, make it possible to improve product experiences for different segments of an audience simultaneously, and how that can be achieved mostly automatically.
I had to run out and check this out for myself, because I know several teams that could benefit from this 1-2 combo.
Introducing Gravity Farms Petfood, my fake delivery pet food service
I’ve mentioned before that I often build working applications when I demonstrate LaunchDarkly. Gravity Farms Petfood is my current playground.

For our use case today, let’s focus on the banner section at the top of the screen. Let’s pretend we’re trying to increase user engagement with this banner.

What does my banner do? If you click it, the “About Us” page opens, allowing prospective customers to learn more about my fake company.
But what should I say here that will draw users' eyes—and hopefully, their clicks—to my banner? Customers use LaunchDarkly to A/B/n test things like banners all the time, so this is a use case that we run into often.
The first little trick I want to discuss is that I don’t want to push out new code every time I try out a new string of text on my page. I want to effectively parameterize the text for the banner, allowing it to serve the text directly from the value it receives from our feature flag.
export const useSeasonalBannerText = () => {
const flags = useFlags();
const bannerText = flags['seasonalSaleBannerText'];
// Ensure we return a string value
const value = typeof bannerText === 'string' ? bannerText : '🎉 Limited Time: 20% off your first order!';
return { value, isLoading: false };I’ve set a default value in my code as an additional protection layer, so text will always be returned. Other than that, it’s pretty straightforward. I get the value returned by the flag, which is:
const { value: bannerText, isLoading } = useSeasonalBannerText(); <span className="inline-block max-w-[1200px] mx-auto">
{bannerText}
</span>Now that I’ve got this set up, I can add and use multiple variations without further deployment.
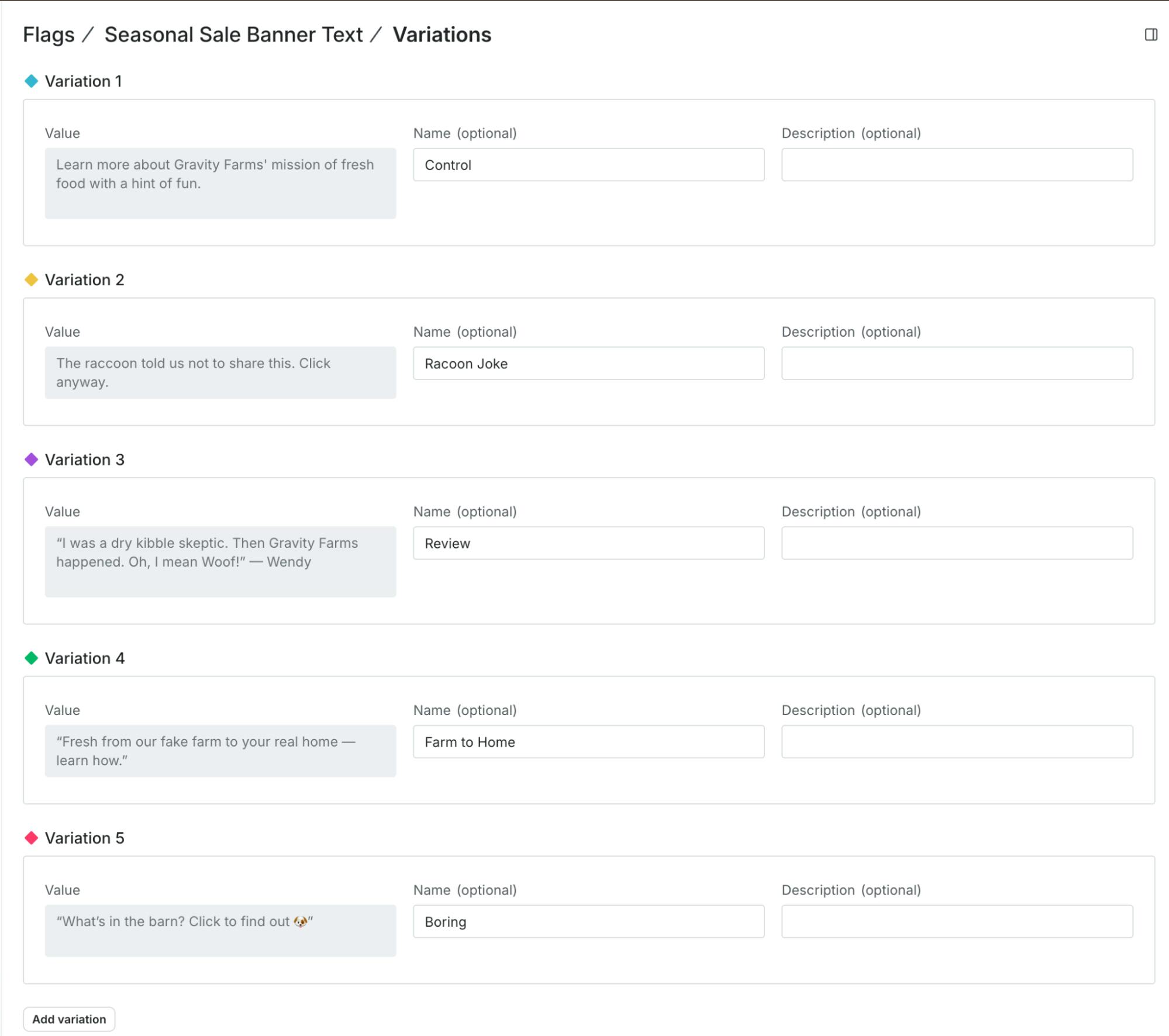
So, to review: I set up a string feature flag in LaunchDarkly with five different variations. My code returns the string value when the flag is evaluated and puts it on the screen in my branded banner section.
Running an A/B/n experiment
If I wanted to learn which text would drive the most clicks on the banner, I could simply set up an experiment in LaunchDarkly. I guess that would be an A/B/C/D/E test.
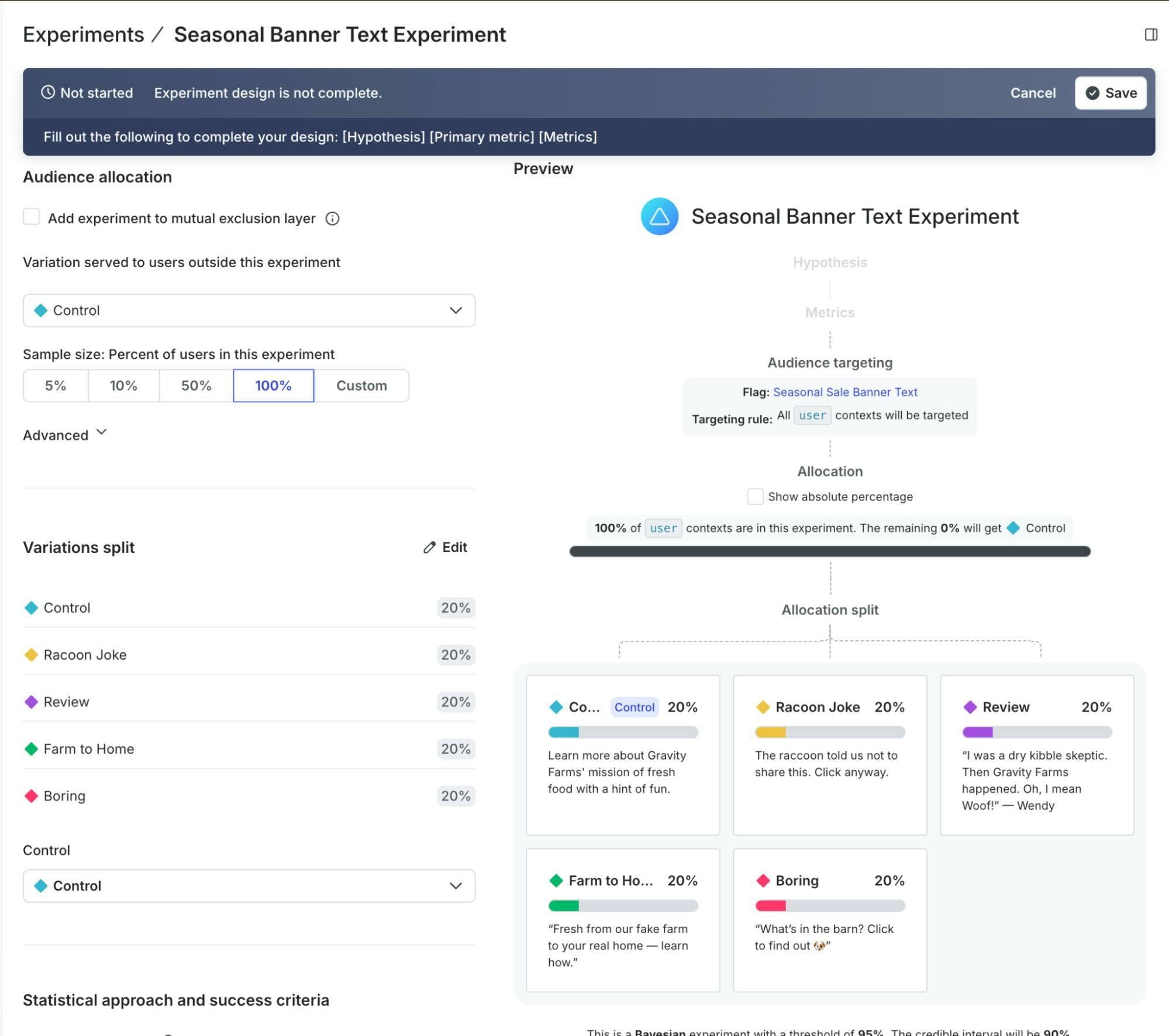
With an experiment like this, I’m splitting my traffic evenly between all variants, each one equally likely to be served to a user at random. I keep it like this until I determine a winner (assuming one variation wins, of course). I can determine which of these variants drives more button clicks, call a winner, and ship it. This is a real added value already!
Using some quick attribute slicing of our experiment results, I might identify some regional differences. Users respond differently in North America than they do in Europe. I’d not be stunned to find that European users and North American users respond to different content, different phrasing, or different experiences.
With my experiment results in hand, I could plan a set of experiments to test different versions in our regions.
Previously, using LaunchDarkly, I could only run one experiment at a time on this flag. I could create a flag rule for our regions, but I could only use one audience (rule) at a time when configuring the experiment.
I would need to prioritize and run experiments sequentially, which adds time to the process. When we finally finish the last experiment, we probably need to revisit the first because customer behavior may have changed over the long duration of the experiments!
Released earlier this year, Multiple Experiments on a Flag (internally, we love the MEoaF acronym) allows us to attach an experiment directly to the flag’s rule, allowing you to attach an experiment directly to a targeting rule on a flag. This means I can have an active running experiment on as many targeting rules as I want for the same flag.
I don't have to run them sequentially. I could create a rule for each of my regions and create experiments specific to those regions, which can be designed differently and run simultaneously.
Now what if we could use the MEoaF feature to quickly learn and take advantage of winning tactics?
Multi-Armed Bandits: Capitalize on your learning and adapt
What is a Multi-Armed Bandit, and when should you use one? For context, I highly recommend reading this excellent article from our data scientist, Jimmy Jin: Why MABs are not just fancy A/B tests.
To return to the example from above: let’s say my wildly successful fictional pet food company ran that same experiment for two weeks, with 100,000 users entering the test.
With five variations, that’s roughly 20,000 users per variation.
Now let’s say the experiment produces a valid result: one variation outperforms the others with a 2% lift in conversions.
- That means 20,000 users saw the winning experience (and benefited from that 2% lift).
- The other 80,000 users saw suboptimal versions—some only slightly worse, some potentially much worse.
Looking back with perfect hindsight, if we’d served the winning variation to all 100,000 users from the start, we’d have achieved 5× the impact; a 2% lift across the entire population, not just a fifth of it.
MABs give us the tools to learn and adapt as new evidence emerges, and to capitalize on those gains. Creating a Multi-Armed Bandit in LaunchDarkly is almost identical to designing an experiment, after you locate the new feature on the left nav bar.
There is one new field to configure: the Update Frequency. How often should we re-evaluate the results and shift allocations?
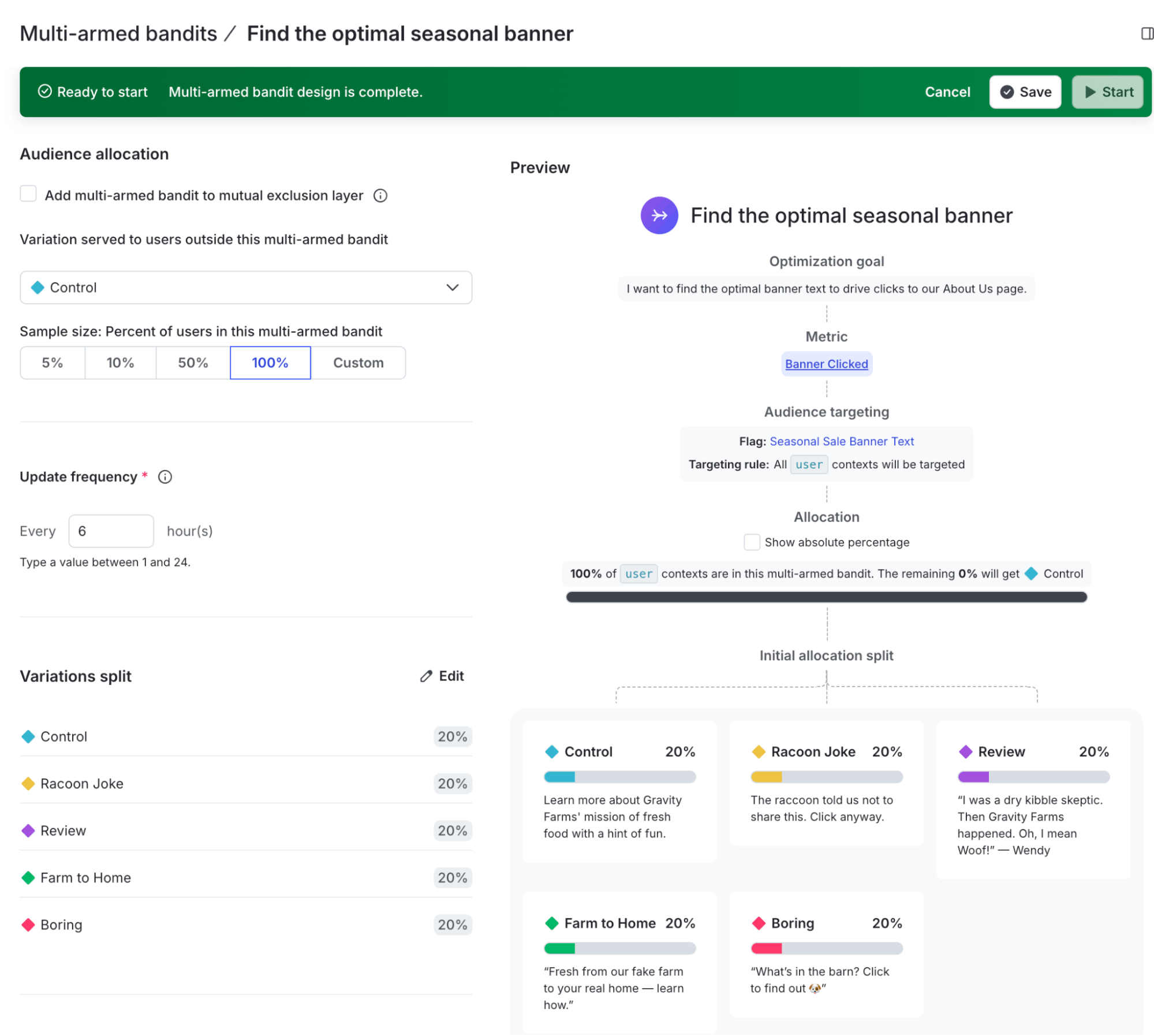
After this is set up, we’re off to the races! Our Multi-Armed Bandit will start with even splits, but every 6 hours (in the example above), the data we’ve received will help us shift our allocations towards the one that’s winning more often.
Now I can learn which of these banners works the best AND take advantage of those learnings immediately.
This is great if we want to learn across an entire population. But I know my customers, and I know that there are regional differences between them. I believe that customers in North America might respond differently from those in the EU or the UK. What if I wanted to be more targeted in my approach and adapt differently for each region?
Target your learning with multiple experiments or MABs
LaunchDarkly released a feature earlier in the year that turns our MAB into an absolute powerhouse for a situation like this.
LaunchDarkly traditionally had a 1:1 relationship between active experiments and flags. This means I could set up an experiment on a flag, but only one. This limitation often showed up when customers needed to treat audiences differently based on some user attribute.
A simple example might be a technology company with different tiers of users. Platinum customers might be too valuable as subjects of a full-volume 50/50% test, but you still want to understand their behaviors. So you set up a more risk-averse measurement wherein 90% of the users still see control, and 10% see treatment. But your standard-tier customers? They could be seeing just a 50/50% test.
These sophisticated experiments were previously—at best—hacked together in LaunchDarkly and/or stitched together with more complicated data science teams via exported data.
But today we have unlocked the ability to attach an experiment—or an MAB—to a flag targeting rule. That means that I can easily use the same feature flag to control the variations, but run multiple experiments simultaneously by leveraging LaunchDarkly targeting rules.
Bringing it to our Gravity Farms example, let’s go a little crazy.
Multiple MABs on a Flag
Back on Gravity Farms, we can now learn what works differently depending on the region our user is in.
In my Gravity Farms setup, I have a pretty simple user context that I leverage, and I’m generating some straightforward data as I simulate users interacting with my site. I create data for my experiment, passing in these context attributes:
User Attributes at Top Level
- petType: 'dog' | 'cat' | 'both'
- country: 'US' | 'CA' | 'FR' | 'UK' | 'DE'
- state: 'California' | 'Ontario' | 'Normandy' | etc.
- planType: 'basic' | 'premium' | 'trial' | 'both'
- paymentType: 'credit_card' | 'paypal' | 'apple_pay' | 'google_pay' | 'bank'
I’ve got a few segments set up representing North America, the UK, and the EU. It simply looks at the country attribute passed into my context. In this example, I've created three segments representing the three regions I want to target with my MAB. In this case, it's a simple attribute filter looking at the user’s country.
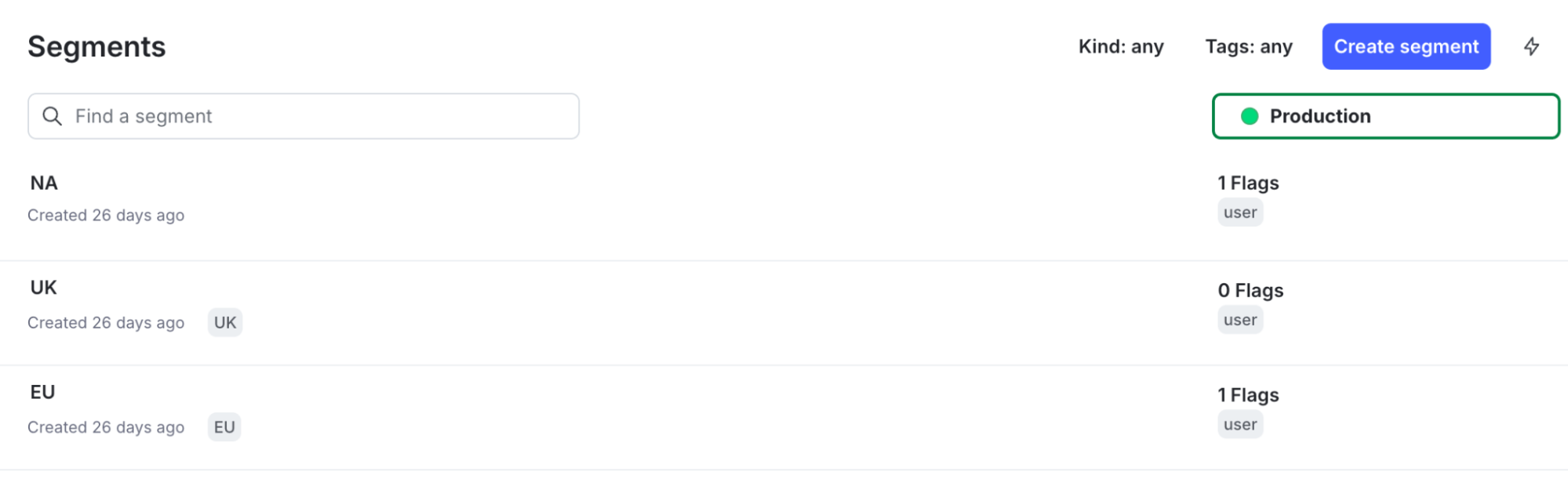
Now, I can create three different Multi-Armed Bandits. I need to make them one at a time, but the setup will be identical, except for the audience segment being targeted. The MAB will start with an equal split for each variant, but it will recalculate the splits each refresh period.
As I create each Multi-Armed Bandit, I can select which rule to target for this experiment. Assuming I’ve already set up targeting rules for my three different segments, I can pick them from the dropdown.
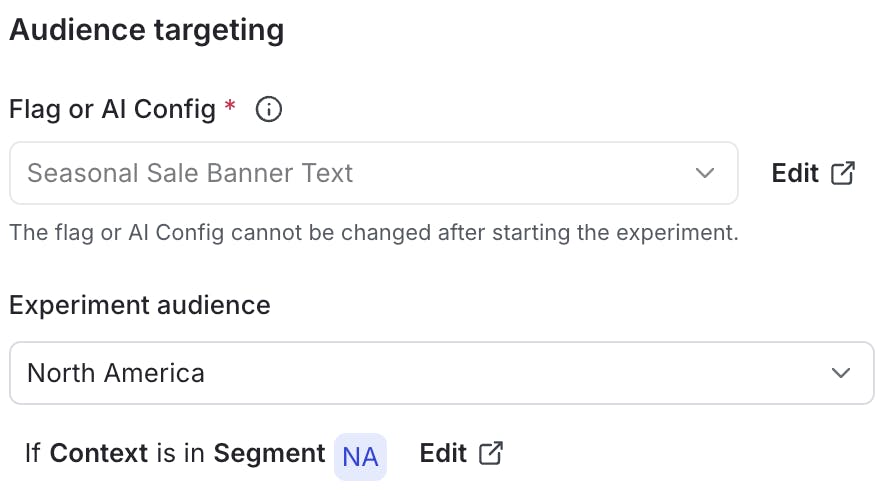
I’ve created my 3 MABs and attached them to the flag rules. If I navigate to my Flag screen in LaunchDarkly and select my banner text flag, I should see multi-armed bandits for each of my 3 targeting rules.
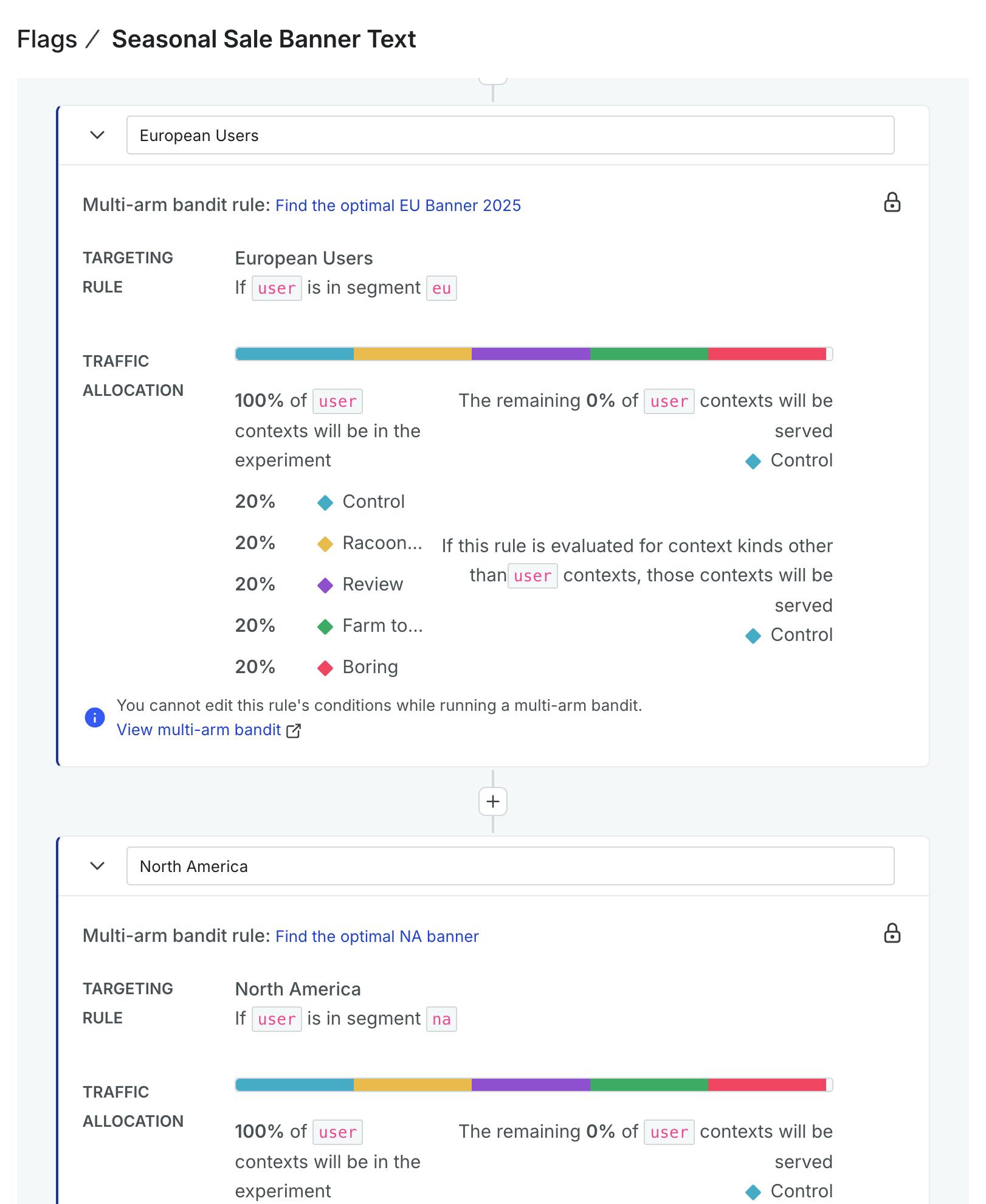
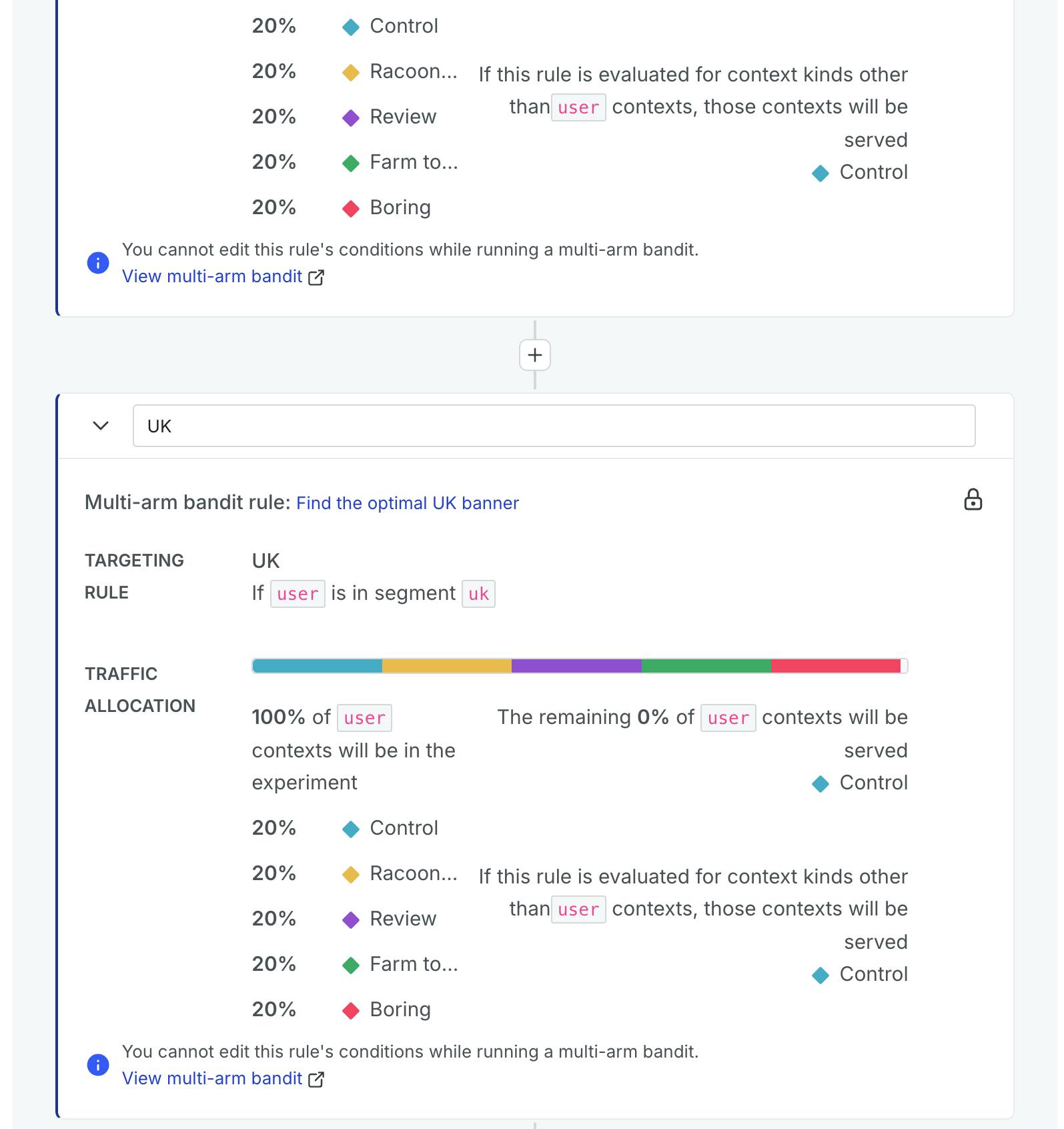
This should allow me to learn what works for the UK and how that differs from North America. The next examples are based on simulated data I've run.
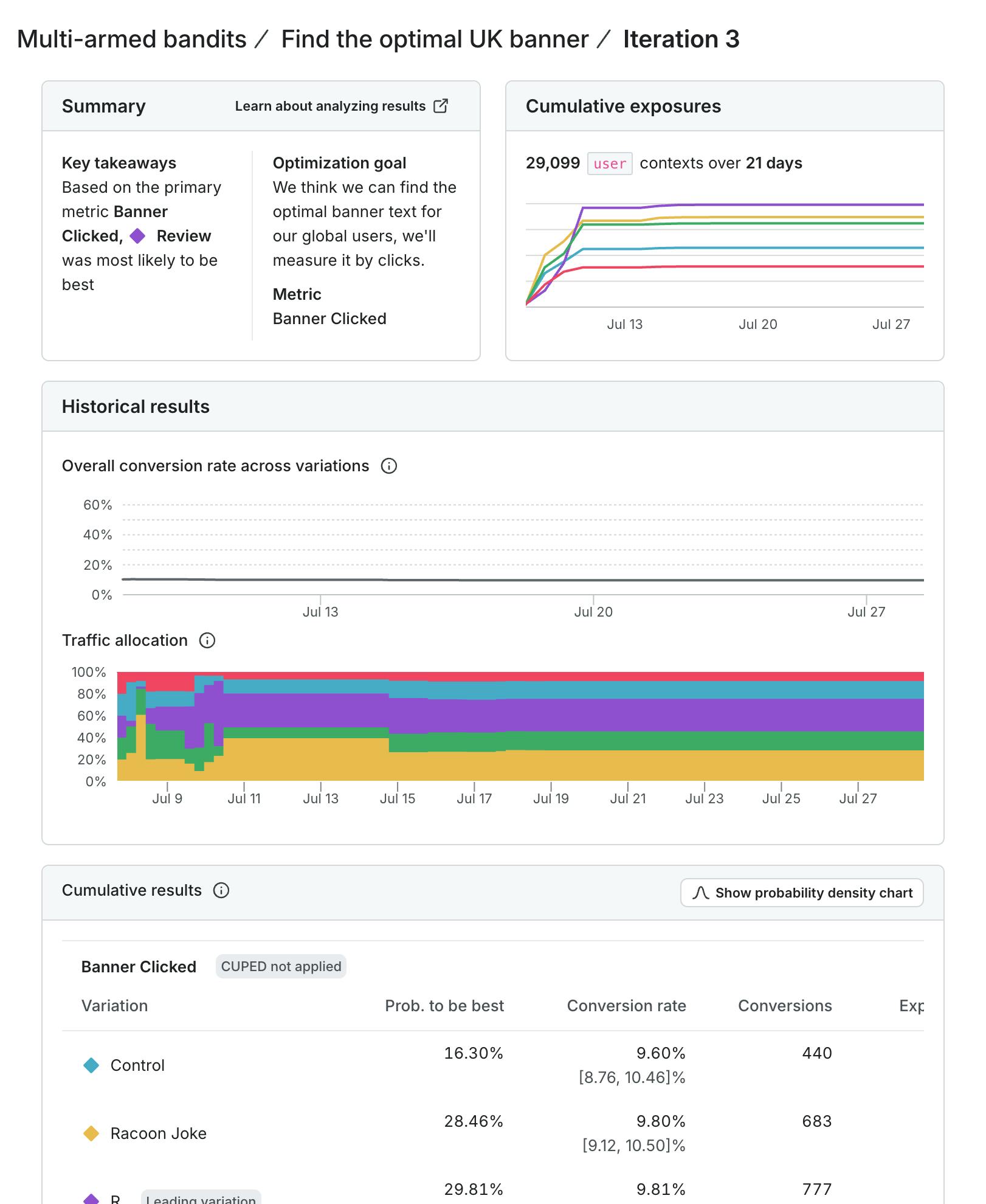
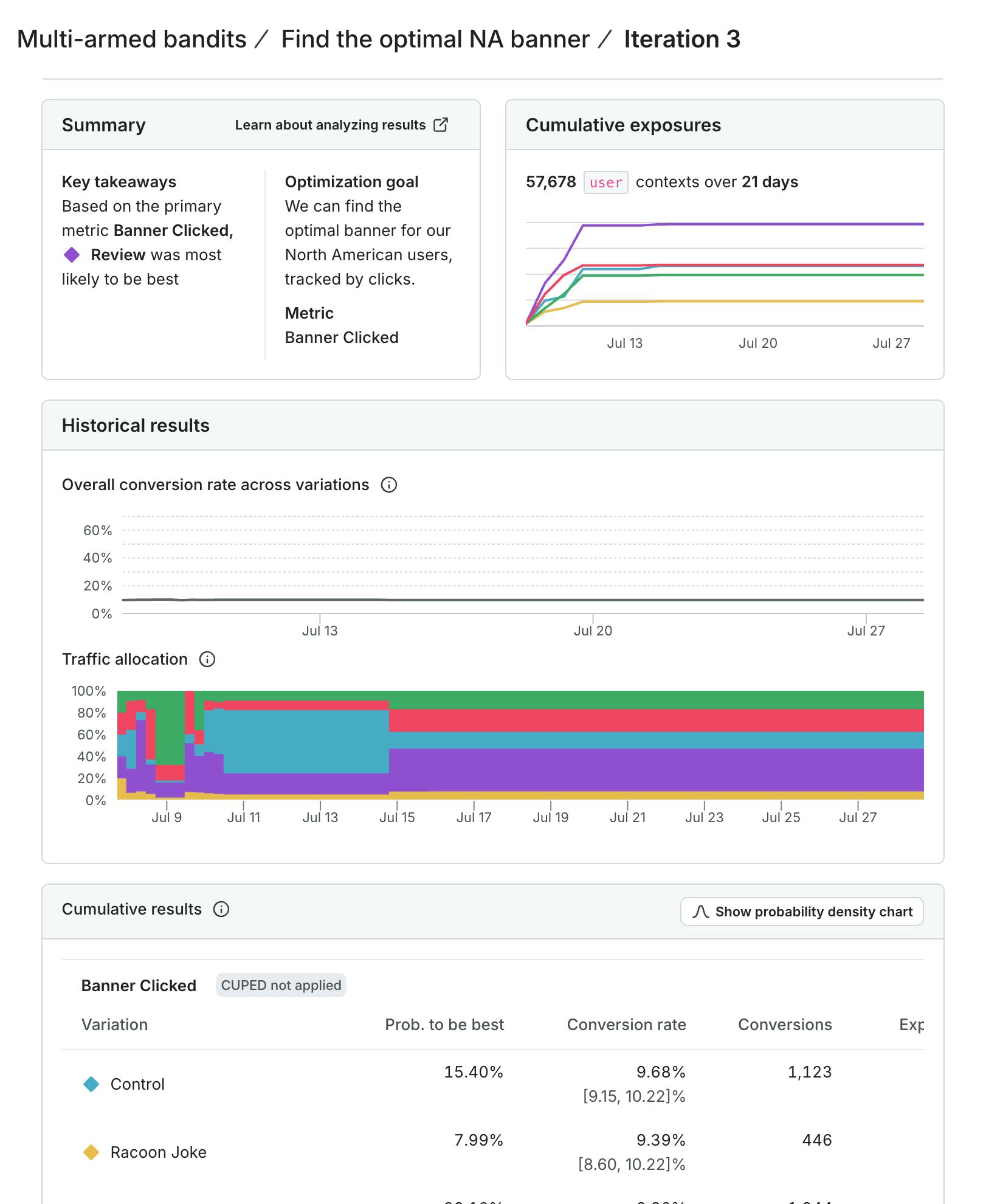
These screenshots show the difference in user behavior and how the traffic allocation shifted differently across the different tests. Even in my example using simulated data, the results change to serve the winning variation more often over time. Yet I can still explore the other options to ensure that, as user behavior shifts as time progresses, our experiment will shift too. In North America, for example, we got some early evidence that our control was performing well. However, user behaviors change as time passes, and our model picks up on that and shifts traffic accordingly. This ensures that we’re taking advantage of our early learnings, while still exploring the space to learn more.
In Summary

This evolution—from static A/B tests to adaptive, region-aware optimization—is more than a new feature. It reflects a broader shift in how we think about Experimentation. We're no longer satisfied with simply identifying the best experience after the fact; we want to deliver better experiences as we learn and tailor them to the diverse audiences we serve. Multi-armed bandits, combined with flexible targeting and simultaneous experiments, give teams the power to optimize faster and smarter. And in doing so, they help bridge the gap between data and decision-making in a practical and powerful way.
Check out my tech talk, Ask the Experimentation Expert: Balancing Feature Delivery and Experimentation, where I share strategies for integrating experimentation into software development and examine multi-armed bandits in action.
Like what you read?
Get a demo