Cloud-native applications let developers build apps that can scale to meet any demand. And container-orchestration platforms like Kubernetes provide an efficient method of deploying and managing containerized cloud-native apps.
While cloud-native architecture solves many operational challenges, it also introduces new ones for application development and testing.
Cloud-native architecture often consists of several microservices, with each microservice handling a single business responsibility. The traditional practice of testing in isolation isn’t good enough, since these services interact to manage complete business workflows. When releasing new changes, teams need to ensure that they don’t impact other services.
Alternatively, teams can rely on an end-to-end testing strategy with replicated environments, including staging and pre-production. Using these environments improves service quality by uncovering various business scenarios. But, they’re expensive in terms of both cost and maintenance.
Moreover, despite companies investing in infrastructure as code, there are still potential differences in the target machines’ configuration, like hardware resources and cluster size. It’s also impossible to get the same load and data volume in the replicated environment as the production environment.
Cloud-native platforms like Kubernetes, however, allow you to run many versions of the containerized services. Their several deployment topologies enable you to build a testing-in-production strategy.
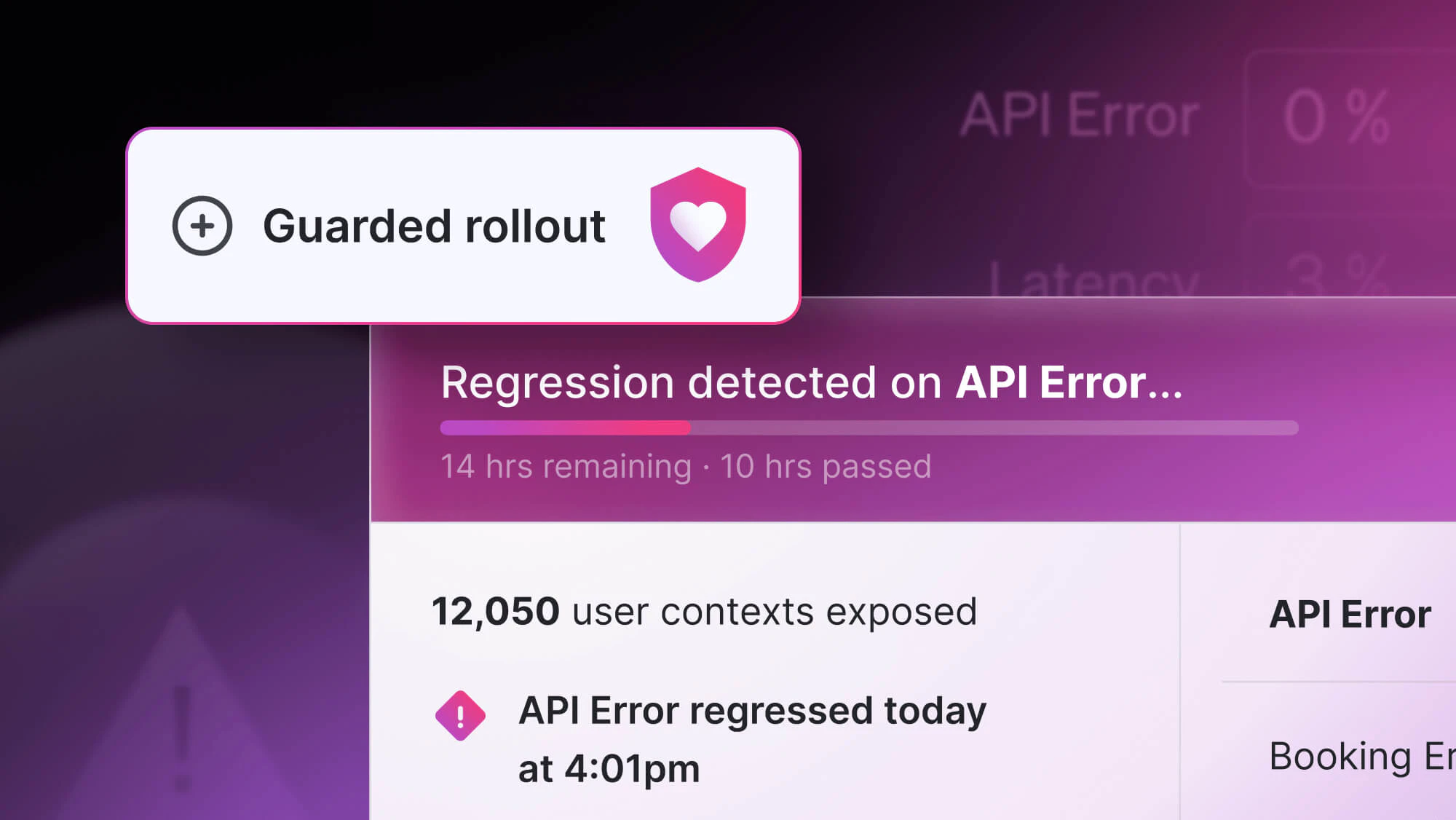
Production testing has historically been a struggle since several things can go wrong. You need the correct tools combined with the right strategy to test your changes unobtrusively without users noticing a glitch. Let’s explore how to safely and effectively test in production with Kubernetes.
Best Practices for Testing in Production with Kubernetes
Let’s look at the most popular ways of releasing a new version in cloud-native platforms and how Kubernetes can simplify each strategy.
Blue-green deployment
The blue-green deployment model requires two identical production environments: blue and green. Only one of the environments serves live requests at any given time. DevOps teams roll out new releases to the environment that’s not currently live, and run a range of tests against it.
Imagine we push a new release to our green environment. If all of our tests pass, we’ll start to route all new requests to the green environment—though we'll let blue finish serving any requests already in progress. Then, we can keep the blue environment stand by as a backup. If we notice any errors in our green environment, we can immediately switch new requests back to the known-good deploy in the blue environment.
The main challenge of the blue-green deployment model is maintaining two identical environments. But, containerization and cloud-native development augment the blue-green deployment model. Kubernetes provides a cost-effective, flexible, and automated way to generate identical environments.
Blue-green deployment significantly reduces the costs associated with a broken release. DevOps teams can use a load balancer to route traffic to either environment as conveniently as flipping a switch. Or, if you’re using a service mesh like Istio or Linkerd, you can use its built-in traffic splitting capabilities to implement blue-green deploys.
Traffic shadowing
Traffic shadowing (also known as traffic mirroring) replicates real traffic received in the currently-deployed version to the new application version. Both services respond to incoming requests, but the user gets the response from the currently-deployed version.
The new version doesn’t persist any updates to user data. It only verifies them for anticipated changes, like method invocations with required data. This approach makes it possible to confirm that the new application version isn’t crashing or misbehaving when handling real user traffic and behavior. The larger the percentage of traffic shadowed, the higher the probability of confidence.
Traffic routing is one of the biggest challenges while shadowing. You need ways to fork requests without impacting the application’s critical paths. If you’re using Kubernetes with an Nginx ingress controller, you can set up mirroring to route incoming requests to your production cluster and a test cluster. Advanced ingress controllers like Traefik can mirror traffic to multiple services in the same Kubernetes cluster. And if you're using an Istio service mesh, you can use its built-in mirroring support.
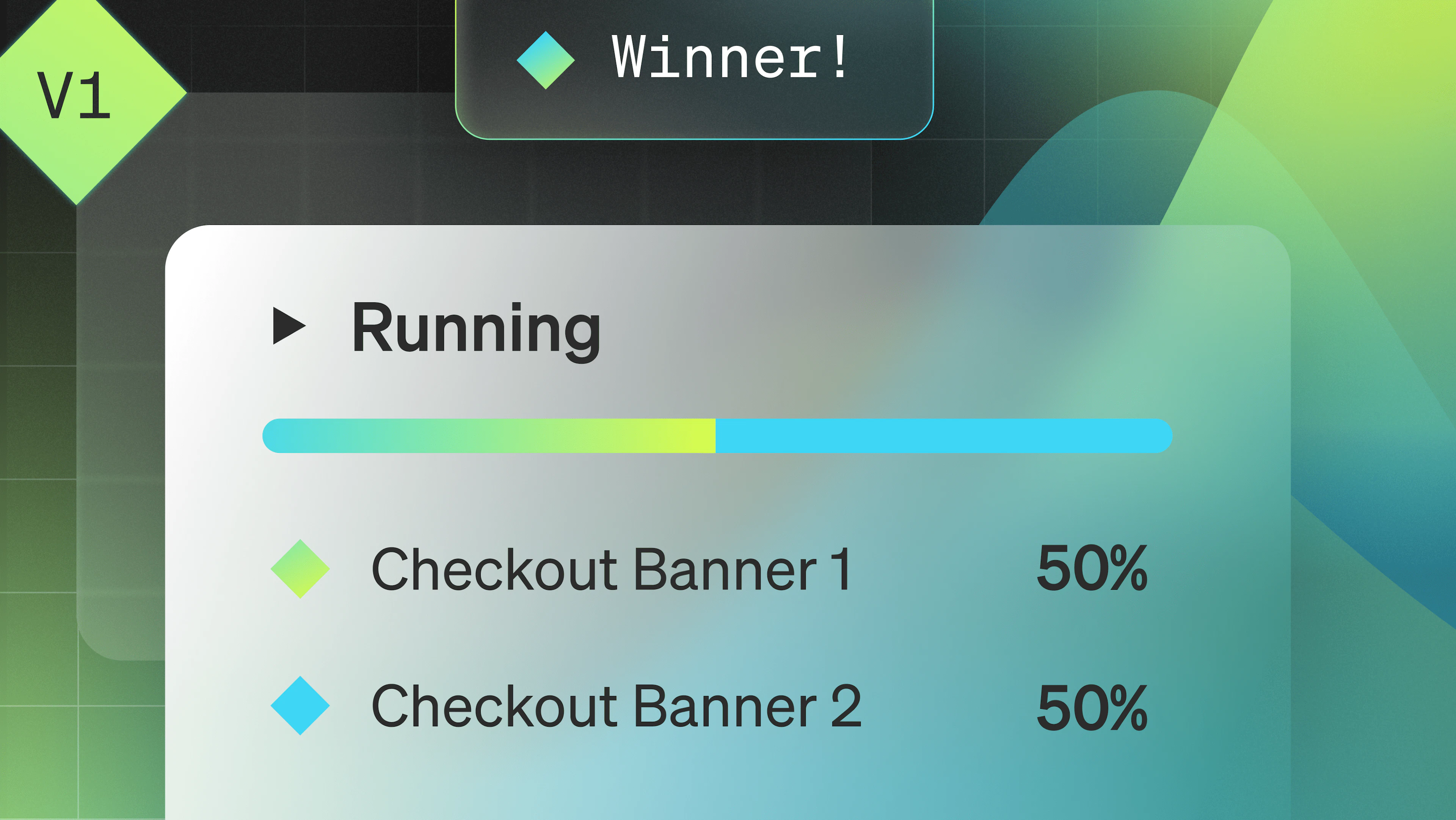
Canary deployment
The canary deployment model shifts a small amount of real user traffic from the current version to the new application version. Either one of the two versions handles user requests—not both, as is the case with traffic shadowing.
The user sees the response from the service version that received their request. Either one of the versions persists updates to user data. Additionally, you can verify the anticipated changes.
Canary deploys require additional metrics to track how the canary performs against the current production release. These metrics enable you to decide if you need to propagate the canary to everyone or roll it back.
The canary release method significantly reduces risk since changes are visible to a fraction of actual users. If there are issues, the deployment team can quickly reverse changes by routing traffic back to the currently deployed version.
Request segmentation is one of the biggest challenges while canary. You need quick ways to identify the request and route it accordingly to the newer or older version. Kubernetes ingress controllers like Nginx, Traefik, and Gloo all support canary routing. If the DevOps team notices increased errors after traffic is routed to canary nodes, they can quickly revert the ingress configuration.
A/B testing
Unlike the other deployment strategies, A/B testing validates overall product updates. This model allows you to render variants of the same application feature or workflow to different users and capture its usage statistics. Teams can evaluate and analyze this data to understand how these changes impact the end users and which variant performs better.
It’s important to note that A/B testing is about end-user workflows. In a cloud-native architecture, this testing often requires changes across several microservices. Building these changes across the entire suite of microservices is challenging, as each service is developed and released independently. Kubernetes allows you to deploy these updated microservices using either canary deployment or blue-green deployments. Additionally, with canary development, it can look into headers to perform request segmentation and route it to the new version of a service.
It’s worth noting that not all A/B tests can be determined at the request level. There are many A/B tests we might want to perform that require data only available at the application level—making features flags a better solution.
Benefits of feature flags
Feature flags enable you to determine whether or not the service is ready to handle incoming requests for the new feature. These flags control the visibility of features behind a toggle switch. The switch allows teams to avoid redeploying an entire application to enable a feature for an environment.
Feature flags offer the following benefits:
- Decoupling service deployment from feature enablement
- Allowing frequent merging and releasing without any broken parts
- Allowing deciding whether the product feature is ready to show your users
- Acting as a kill switch to quickly turn off the feature and mitigate the impact of a bad release
These flags can be configuration values stored in the database, injected into the environment properties, or loaded from external servers in the most straightforward implementations. Flags enable you to control the application’s behavior. For example, you can set it to be dynamic for every request or static by performing a service restart.
In a Kubernetes cluster, you can use feature flags with canary deployment, where you deploy a service with enabled flags. You can then perform A/B testing by routing a subset of the application’s users to the suite of enabled services.
The concept of a feature flag is just a toggle switch, but you can extend it to include feature configurations that allow behavior tweaks for the newly created features. Creating these configurations with default values enables end users to evaluate the new feature’s nuances rather than just one variant. However, these flags become technical debt, as adding them is often part of the feature specification—but no one seeks their removal.
Teams should adopt the following best practices while working with feature flags:
- Allow dynamic switch toggle using a database, APIs, or language-specific extensions like JMX.
- Avoid expensive database (DB) and API lookups for every serviced request. Instead, cache feature flag configuration in-memory so the application can make decisions without external dependencies.
- Clean up the flags when they’re enabled for everyone.
Feature flags sound simple enough. You just need to add a few booleans, right? Use caution, however. Building out your own feature flagging system isn’t always the right decision.
Summary
Cloud-native platforms like Kubernetes support several deployment models for releasing a new version of a service. But these models aim at a single component. Instead, enterprises need to launch product features that integrate multiple services.
These services need an approach to develop and release the changes individually. Feature flags decouple the service changes and their activation. However, building these flags can be challenging, and the more flags your application requires, the more difficult it becomes to manage them.