

Kubernetes has drastically changed the way people ship and deliver modern application workloads. Its API-first approach, out-of-the-box resiliency, and the ability to establish a consistent deployment pattern across any type of Kubernetes cluster (whether it be cloud, or on-premises) gives the open-source container orchestration system a lot of opportunities to shine.
In the DevOps world, we tend to rally around tools like this, and look for ways that interconnect them to simplify and enhance our workflows. In that light, it's not surprising that we hear this question often: "What is the story of LaunchDarkly with Kubernetes?"
When you mix in Kubernetes' own deployment and release patterns, some wonder if LaunchDarkly competes with Kubernetes or simply lives adjacent.
In this post, we're going to take a look at how Kubernetes and LaunchDarkly solve very different problems from each other while living in the same realm that gets applications in front of users quicker and more reliably.
Infrastructure State vs Software State
Before we dive into where these tools fit in with each other, let's take a look at where each tool fits in the application delivery toolchain.
Kubernetes is a workload orchestrator. It takes an API-first approach to ensuring that workloads continue running based on a declarative configuration (we typically refer to this as a Kubernetes manifest.) Simply put, Kubernetes is designed to ensure container workloads keep running based on configuration values that you've declared.
One of the hallmarks of Kubernetes is its control loop approach, where it does everything it possibly can to keep the workload running in the way you've configured in the manifest. To this end, it's safe to summarize: Kubernetes is an API-first infrastructure platform for managing the running state of container workloads.
Kubernetes is often directly attached to the concept of "cloud native operations"—which is a whole different conversation for another day—and you can find Kubernetes platforms living across all the major cloud vendors, as well as within many different on-premises deployment methods as well.
Conversely, LaunchDarkly (as you might have already found since you're here with us) is a feature management platform that focuses on helping release features in their respective applications faster and safer. What does this mean in practical use?
LaunchDarkly integrates within your application to wrap parts of its code in feature flags, that you can then build rules around how to release to end users. Do you want to target only browsers that are marked as mobile browsers with a new feature for testing? We can do that. Want to test a new UI element for your users, live within your production environment? Easy stuff.
If Kubernetes manages the running infrastructure of your application, then LaunchDarkly is controlling the software state, and giving you tools to rollout and rollback features within your application to your users.

Where the Dragon's Live
With Kubernetes managing the running state of application workloads, the concept of rolling out a new version of those workloads (whether it's running as a standalone pod, or a deployment—both of which are Kubernetes constructs), is a fairly "built-in" capability. Outside of your Kubernetes cluster, you build your application as normal. You push your code to a destination (most commonly something like GitHub or another source control platform), and build your updated container image (usually this is done via some sort of CI/CD process). With this updated image available, you update your Kubernetes manifest with that new container image details, and apply the updated manifest. The Kubernetes API processes that manifest, and reconciles that declared state. The old versions of the pods are terminated and replaced with the new version. Assuming you're running multiple replicas of the application within your Kubernetes cluster, this rollout is done gradually, to keep your application available at all times.
Now, here's where the dragon's (AKA scary problems) show up.
When the new pods come up within the cluster, your application is available for use. The entirety of the changes you added in this new version of the application are consumable by your user base. This is fine if your release is bug free and flawless, but how often does that actually happen? Any problems that exist within your application are now exposed to all users consuming the application. These problems could be as simple as visual components not rendering appropriately on a mobile device, or as drastic as an API that is not injecting thousands of records a second into your database, impacting stability of your environment and becoming costly. Worst case, your entire application might be down and non-functional.
This ends up in a really bad day for a system operator who now needs to rollback this application (likely by deploying a previous image.) If you've been running nightly builds via your CI/CD process, you might have to check back across several versions to find one that doesn't have the issue. It's also possible you'll need to rebuild the image entirely... and all of that takes time. Time isn't your friend during an outage.
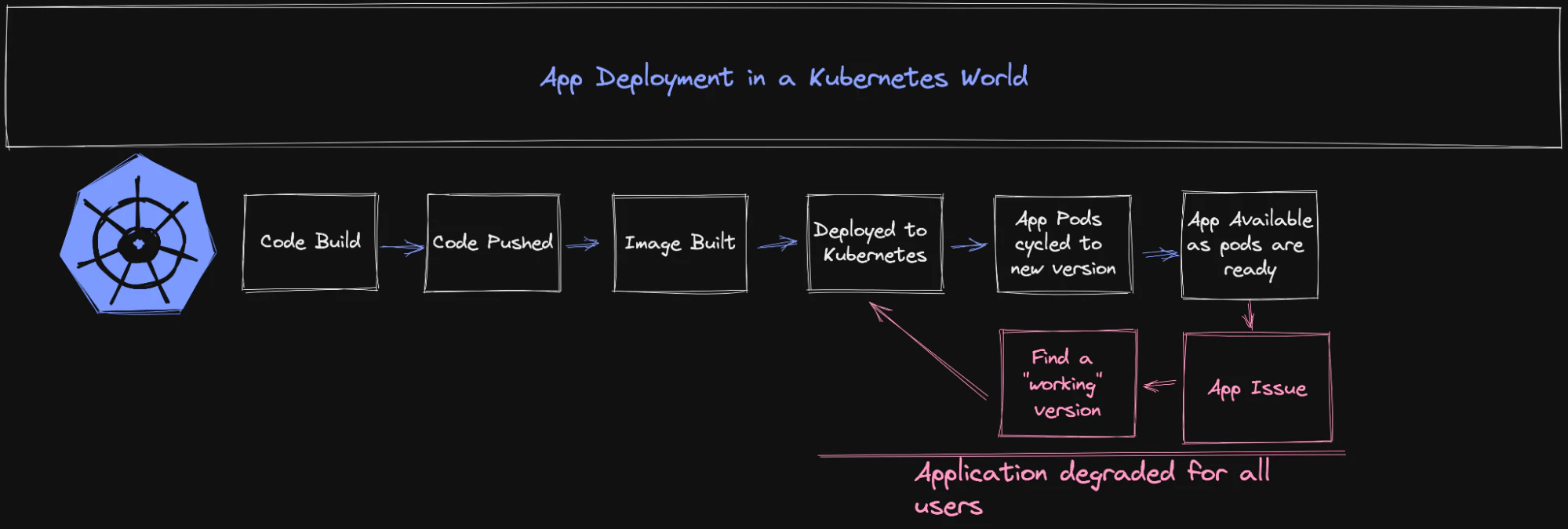
It's worth noting that this really isn't Kubernetes' fault. Remember, Kubernetes is managing the running state of the workload. It's doing its job in the most efficient way it knows how. We can run simple health checks on an application to try and ensure it's healthy, but ultimately Kubernetes has limited visibility inside your application workload itself. Its job is to keep your infrastructure resilient, available, and process the changes and updates you've applied to the running state.
Building Resilient Software Releases
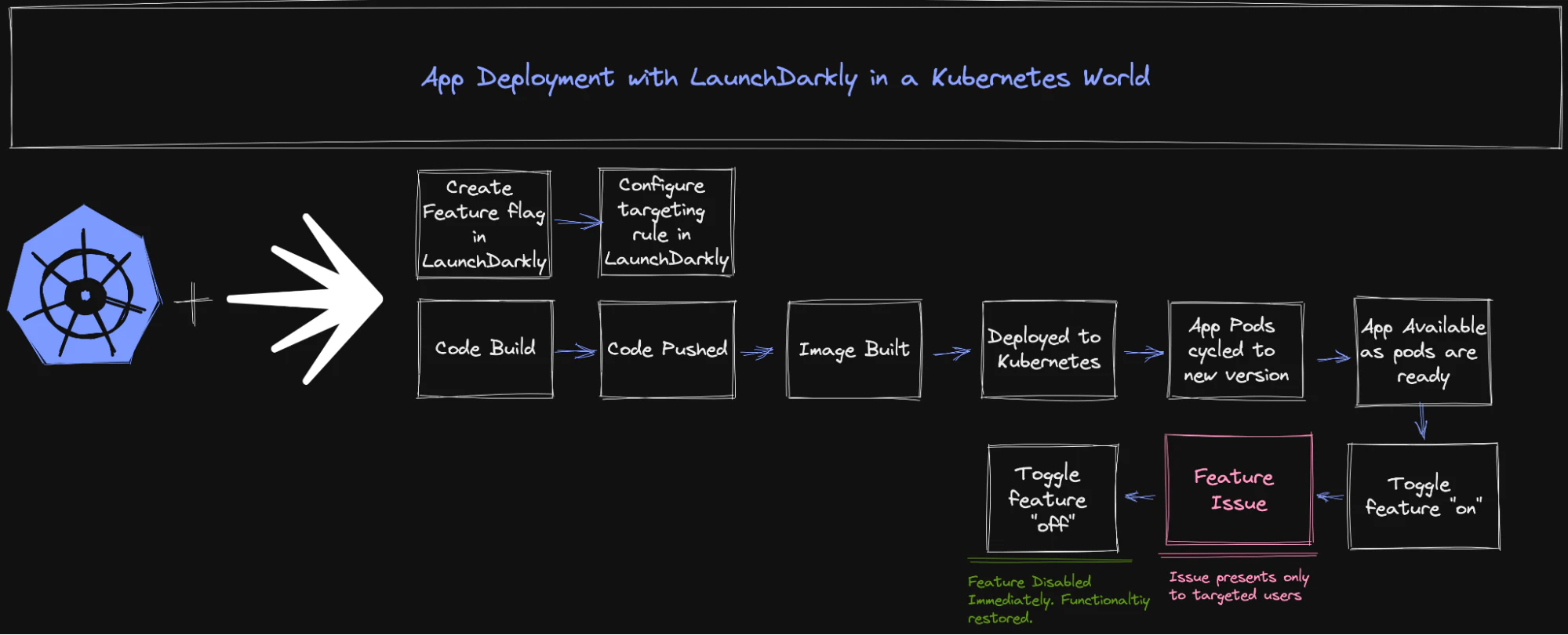
LaunchDarkly helps solve this problem in an elegant way by allowing us to build feature flags around parts of our application functionality (directly within the code), and subsequently create targeting rules around the evaluation of those flags.
These targeting rules allow us to influence what values users will get based on pre-configured characteristics. In practice, this might look like "dev" users receiving a new set of menus within the production website, an updated version of APIs they can work within, or even the example we mentioned above where we want to target only "mobile" device browsers with a change. These flags and targeting rules are created within LaunchDarkly's platform portal, and we embed the flags into the application code. Feature flags are enabled by turning on those targeting rules, making the evaluation possible.
With those items established, the rest of the process looks very similar to the Kubernetes workflow: we build our application, push our code, let our image build, and then deploy onto the Kubernetes cluster. The pods cycle and are replaced with the updated code. Our newly-deployed application has the feature flags present within the application itself, and we are able to enable or disable those features directly within the LaunchDarkly portal.
By living in the actual code of our application, these feature flags allow us fine-grained control over who can even execute those components. For a buggy feature, the non-targeted users are not impacted at all because ultimately the code isn't executing for them. This opens up all sorts of powerful capabilities, including the concept of "testing in production'' which we talk so often about.
This approach moves us away from the "all-or-nothing-dragons" approach that we discussed earlier. We've been able to limit our blast radius to the smaller test group. And, in this case if there is a problem with the code, we have the ability to immediately restore functionality by simply disabling the feature entirely with one quick toggle within the LaunchDarkly portal. With the targeting rule disabled, the feature is removed from the running software state of the application instantly, and you can return back to the development process and correct the code while NOT in the midst of a massive platform outage.
So What's Next?
What we've highlighted here barely scratches the surface of what feature management brings into the Kubernetes world.
When we start to move beyond the immediate problem of bringing flags into your application and how that shifts deployment processes, we start to uncover capabilities like progressive rollouts (gradually releasing a change at specific intervals), and concepts like Feature Workflows to automate the way these flags are rolled out within the platform. We can look at flag triggers, which allow platforms to enable or disable feature flags based on specific configurations or even through pipelines. We can also start to look at concepts like experimentation, that give us better data around our application rollouts, so we can make more informed decisions around what features should become enabled broadly.
Developing with feature flags is a foundational component of building resilient applications, and ultimately, software deployments overall. Establishing a feature flag platform gives you a ton of options around how to keep building faster and safer. And, when you mix those deployment capabilities with the core capability of Kubernetes, you end up in a scenario where the capabilities really are complementary to each other in a meaningful way.


















