Your warehouse is the source of truth for your decisions. A year ago, we made it the source of truth for your experiments, too, bringing warehouse-native experimentation to Snowflake so teams could analyze experiments directly on the data they already trust, with no copies and no second version of the truth.
Since then, adoption has grown steadily, and we've learned a lot from teams running real experiments against their own warehouse data. Today, we're putting those lessons to work, with updates on two fronts:
- Wherever your data lives. Warehouse-native experimentation now runs on BigQuery, Databricks, and Redshift, alongside Snowflake, so you can run it on the warehouse you already use.
- Whatever your analysis demands. It now includes advanced statistical capabilities that were previously available only in hosted experimentation.
Wherever your data lives
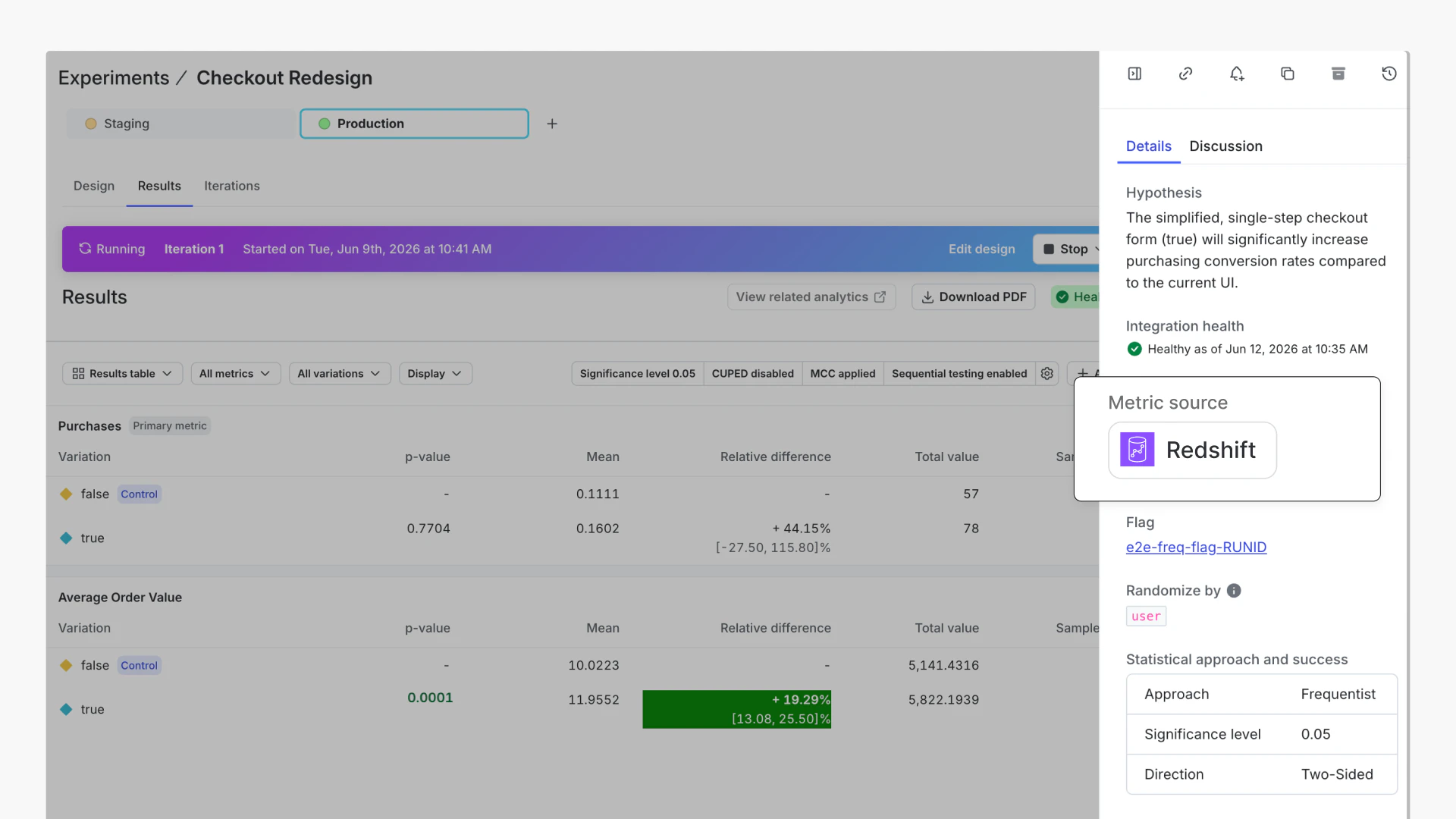
Whichever warehouse your organization relies on, you can now experiment directly on your own data. With BigQuery, Databricks, and Redshift joining Snowflake, warehouse native experimentation gives you the same trusted experience, while keeping your sensitive data in your warehouse. LaunchDarkly only receives aggregated, de-identified experiment results to power reporting in our product.
And the workflow stays the same, no matter which warehouse you rely on:
- LaunchDarkly syncs experiment exposure data into the warehouse via Data Export.
- Metrics are defined from metric sources, which draw on the tables in your warehouse, and are computed directly against them.
- Results surface back in LaunchDarkly for analysis and decision-making.
You define your metrics in LaunchDarkly, and they compute against the same governed data your team already trusts. No reconciling, no second version of the truth, and no asterisk on your results.
Whatever your analysis demands
Trusted data is only half of it. You also need the statistical rigor to act on results with confidence. Over the last few months, we've brought the depth of hosted experimentation (where LaunchDarkly stores your data and computes results on our own infrastructure) directly to your warehouse. These are a few of the capabilities we've shipped:
- Sequential Testing: Call experiments the moment they're conclusive, minimizing the false positives that come from peeking early.
- Multiple Comparisons Correction: Test many metrics and variations at once while keeping your false-positive risk under control, even as the comparisons add up.
- Adding metrics post-experiment start: Add metrics on the fly and see results immediately, without committing to a fixed set of metrics upfront.
- Result Segmentation: See how different user segments respond to your hypothesis, not just the aggregate.
Snowflake, our longest-running integration, goes a step further with metric winsorization and windowing for even finer control over how outliers and measurement windows shape your results. We'll also be rolling these features out to other warehouse integrations soon, and going forward, we're aiming to bring new capabilities to every supported warehouse at the same time.
For product teams, this means faster experimentation cycles. For data teams, metrics stay governed in the systems they already manage.
Get started
Warehouse-native experimentation is available today on BigQuery, Databricks, Redshift, and Snowflake. Set it up on the warehouse you already use:
New to warehouse-native experimentation? Request a demo and we'll walk you through running your first experiment on your own data.