







Hireology builds safe, scalable AI features.

In less than 13 seconds, I can test 3 verticals, 10 tests each with LaunchDarkly. In the time it takes to generate one job description, I’ve tested all iterations programmatically.
Agent behavior shifts in production without warning. AgentControl helps keep agents on track, blocking bad behavior and steering responses in real time.
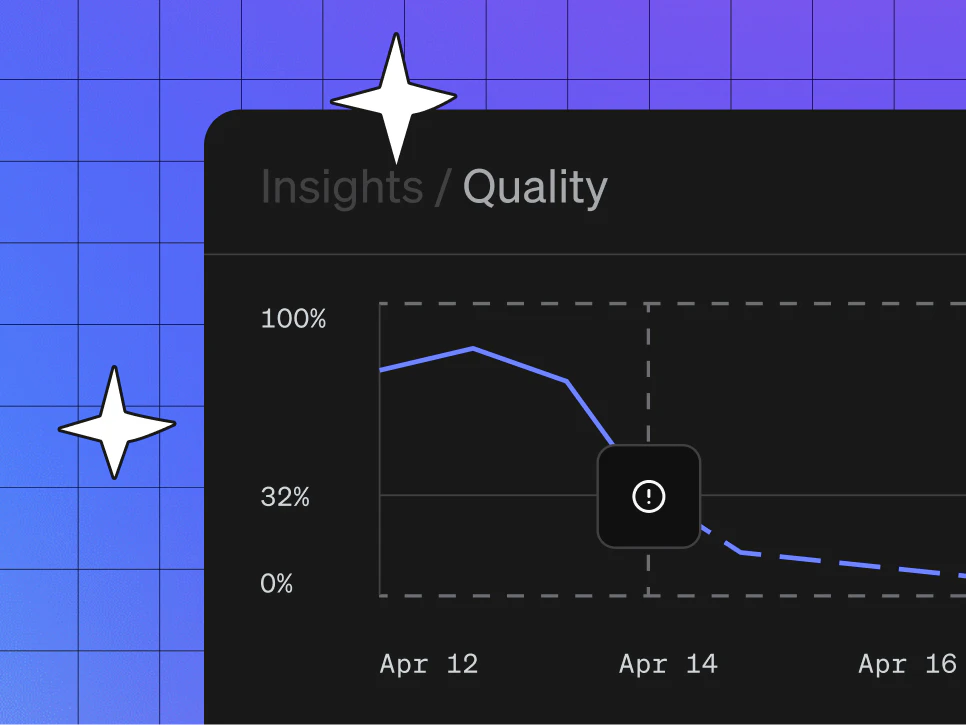
Other tools tell you when an agent fails. AgentControl fixes it automatically. When a response drops below your quality threshold, it escalates to a more capable config—within the same conversation turn, before the customer sees anything.
Other tools tell you when an agent fails. AgentControl fixes it automatically. When a response drops below your quality threshold, it escalates to a more capable config—within the same conversation turn, before the customer sees anything.
Replace hardcoded config with a single SDK call wherever you initialize an agent. Manage prompts, models, and tools in AgentControl, instead of scattered across every service in your stack.
# config buried in code — any change = redeploy
# repeat this for every agent — every team, every update cycle
MODEL = "gpt-4o"
TEMPERATURE = 0.3
MAX_TOKENS = 512
SYSTEM_PROMPT = """You are a triage agent for a medical
insurance company. Classify the query and route to:
provider_agent, policy_agent, or billing_agent."""
def run_triage(query: str) -> str:
return openai_client.chat.completions.create(
model=MODEL,
temperature=TEMPERATURE,
max_tokens=MAX_TOKENS,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": query},
],
).choices[0].message.content# one-time SDK setup
ctx = Context.builder("user-123").kind("user").build()
def handle_model_call(config, tracker):
response = tracker.track_openai_metrics(
lambda: openai_client.chat.completions.create(
model=config.model.name,
messages=[m.to_dict() for m in config.messages] + [
{"role": "user", "content": query}
],
)
)
return response.choices[0].message.content
# each agent is two lines — config lives in AgentControl
config, tracker = aiclient.completion_config(
"triage-agent", ctx, fallback_config
)
handle_model_call(config, tracker)Works with leading providers
and frameworks.
Configure, benchmark, release, observe, and iterate—everything you need to build and run agents in production, without stitching together a different tool for each.
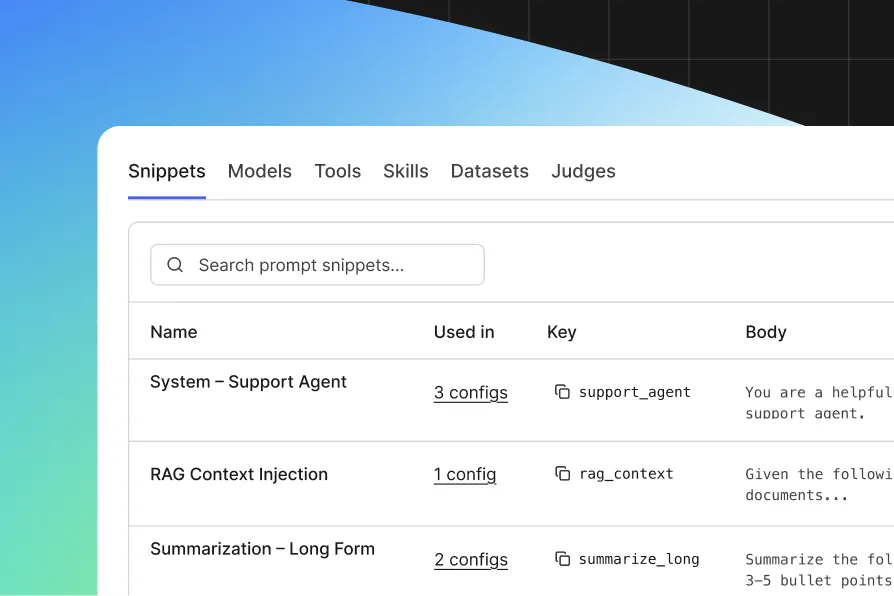
Model settings, prompts, tool configs—all in a central store, separate from the code that deploys them. Shared prompt components propagate across every config automatically. Every change is versioned, auditable, and access-controlled.
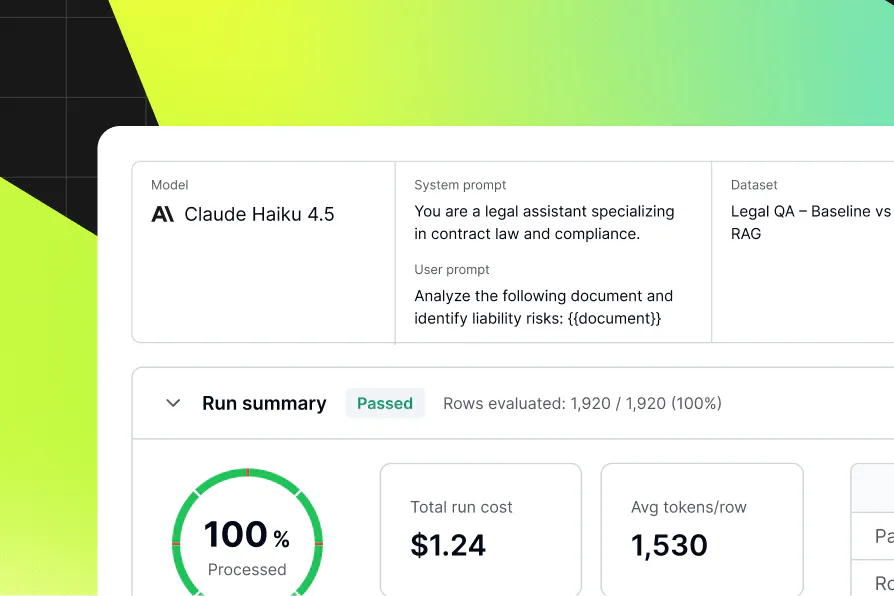
Run offline evals of prompt and model variants against your golden datasets before anything ships. LLM judges score each candidate against your defined thresholds—and only what clears the bar gets to production.
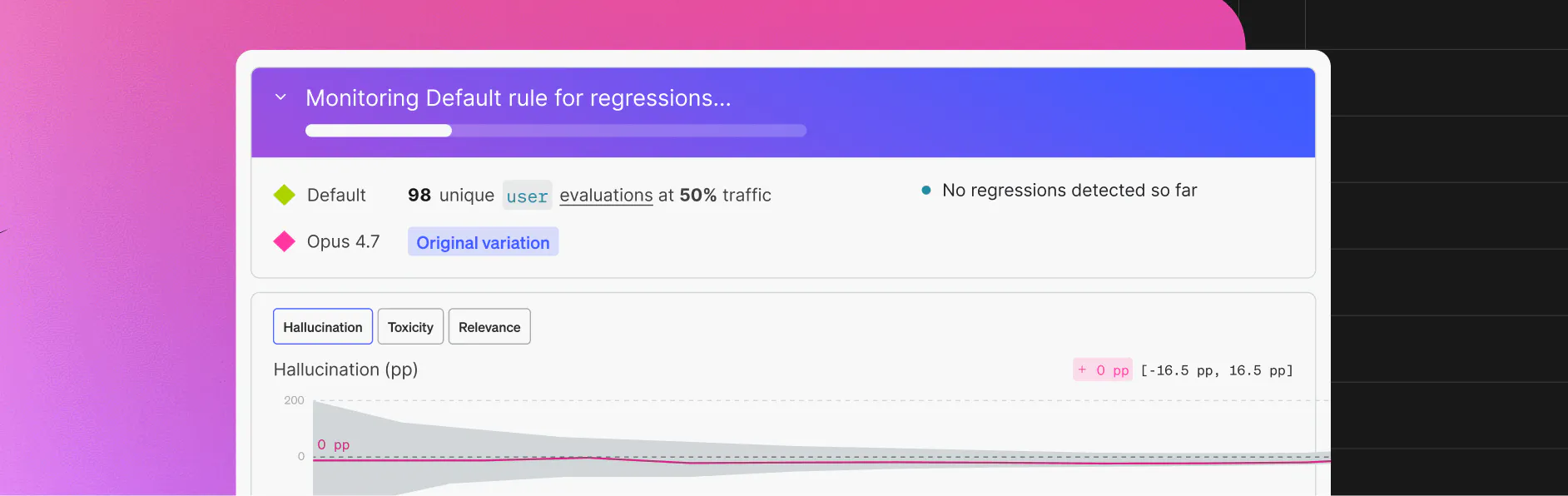
Roll out a prompt or model change progressively to users—no deployment required. Traffic splits and user targeting let you expand at your own pace. Quality metrics watch every stage: Drift triggers automatic rollback before it reaches more users, and critical failures halt the rollout immediately.
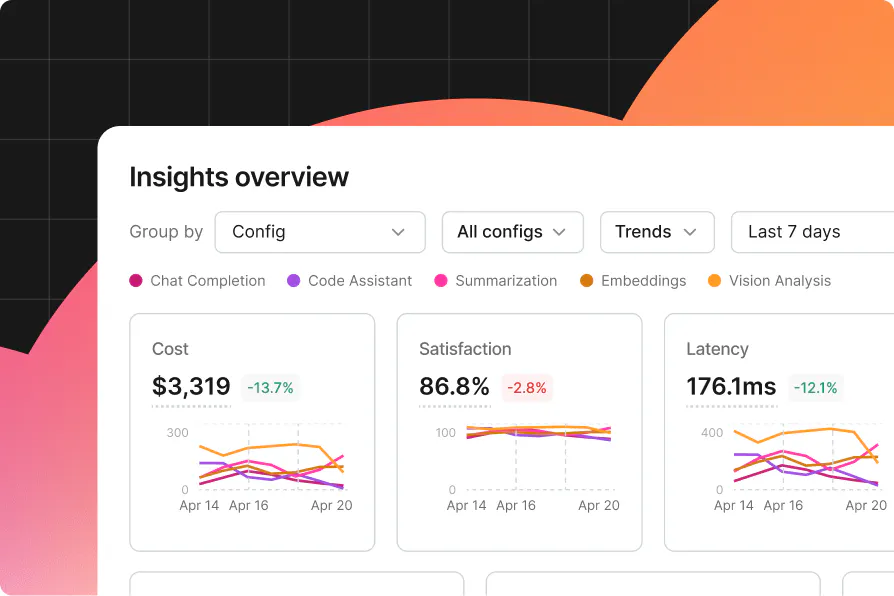
Full traces across every agent invocation: What was called, in what order, and how long each step took. Online evals run continuously against production traffic, scoring for quality, cost, and any custom metrics you define. When metrics shift, you'll know which config change caused it.
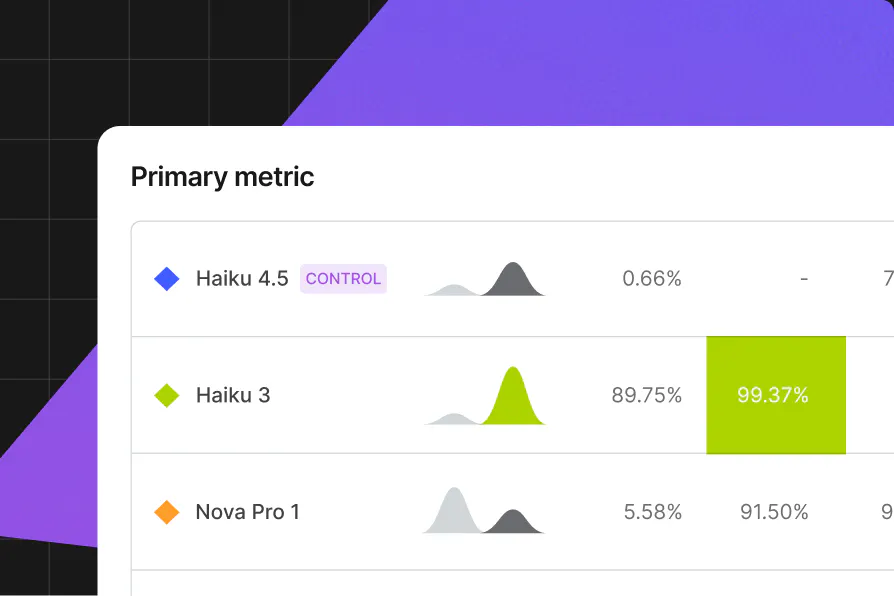
A/B and multi-armed bandit experiments on live traffic, scored by LLM judges and business metrics. When a winner emerges, it ships automatically. Every experiment leaves you with better data for the next.
AgentControl is built on the same infrastructure LaunchDarkly uses to serve 50 trillion flag evaluations a day across some of the largest engineering teams in the world. That means reliability, security, and compliance are solved problems before a single agent goes live.
50T+
Flag evaluations per day
< 200ms
Config propagation, globally
99.99%
Enterprise uptime SLA
SOC 2 Type II
Certified
ISO 27001
Certified
ISO 27701
Certified
FedRAMP
Moderate ATO
In less than 13 seconds, I can test 3 verticals, 10 tests each with LaunchDarkly. In the time it takes to generate one job description, I’ve tested all iterations programmatically.



