Observe at the scale that you release.
Observability built to detect issues early, resolve them quickly and tie issues to your releases.



How it works
Guard every release from the start.
Automatically reduce risk before issues ever reach real users.
Progressive rollouts with live performance and error signals
Release-level thresholds tied to real user impact
Automatic rollback the moment guardrails are breached



Understand what happened, instantly.
See user behavior, telemetry, and flag data together to debug issues faster.
Session Replay shows what users clicked, saw, and did
Heatmaps reveal engagement, friction, and frontend impact
Errors, logs, and traces automatically link to the same session
Flag-aware context shows which features and variations users were under


Fix it fast.
Vega shows you what’s wrong, why it may have happened, and how to fix it—fast.
Always-on analysis across logs, traces, errors, and sessions
Root cause explanations connected to recent changes and releases
Automated investigations launched from alerts or Guarded Releases
Slack-triggered RCA to accelerate team response


Faster-path forensics.
Cut through the noise by connecting errors, system telemetry, and user impact directly to the release that caused them.
Faster-path forensics.
Cut through the noise by connecting errors, system telemetry, and user impact directly to the release that caused them.
Establish what failed—with evidence.
Collect high-fidelity failure data in real time with Logging and Error Monitoring, so you can prove what broke, how often a failure occurred, and which release introduced it.
Follow the failure through the system.
Investigate where a request went (and where it failed) by pivoting from errors to logs and distributed traces with Logs & Traces.
Know exactly who was impacted by the change.
Examine flag evaluations by user, cohort, and variation with Flag Audiences to definitively identify who was exposed, what they experienced, and why the impact occurred.








See what users actually experienced.
Eliminate the guesswork and debug with confidence.
See what users actually experienced.
Eliminate the guesswork and debug with confidence.
Recreate the issue exactly as it occurred.
Reproduce bugs instantly with Session Replay to see exactly what a user experienced before, during, and after an issue—without manual reproduction.
Understand how users interacted with the change.
Identify friction or unexpected behavior introduced by a release by visualizing user interaction patterns with Heatmaps.
Hear directly from users in the moment.
Capture in-app, flag-aware Feedback so you can understand user sentiment and link comments directly to sessions and observed behavior.






Fix what broke — faster than humanly possible.
Resolve issues at the point of release with Vega, the LaunchDarkly observability agent that explains what broke, why it may have happened, and how to fix it.
Fix what broke — faster than humanly possible.
Resolve issues at the point of release with Vega, the LaunchDarkly observability agent that explains what broke, why it may have happened, and how to fix it.
Never miss a signal.
Know something’s wrong in seconds with Vega’s context-aware agent surfacing, which cuts through noisy telemetry and highlights the errors, alerts, and release changes that matter.
Sift through the noise.
Understand why it may have happened with Vega’s root cause reasoning, which performs the same change analysis that developers do manually across code, flags, and environments, in seconds instead of hours.
Solve it with confidence.
Fix issues faster with Vega’s AI-generated remediation and rollback guidance, including GitHub-ready fixes, so teams can reduce MTTR without risky guesswork.






Release safely —
without slowing down.
Ship confidently by guarding every release with real-time performance insight tied to feature flags and versions.
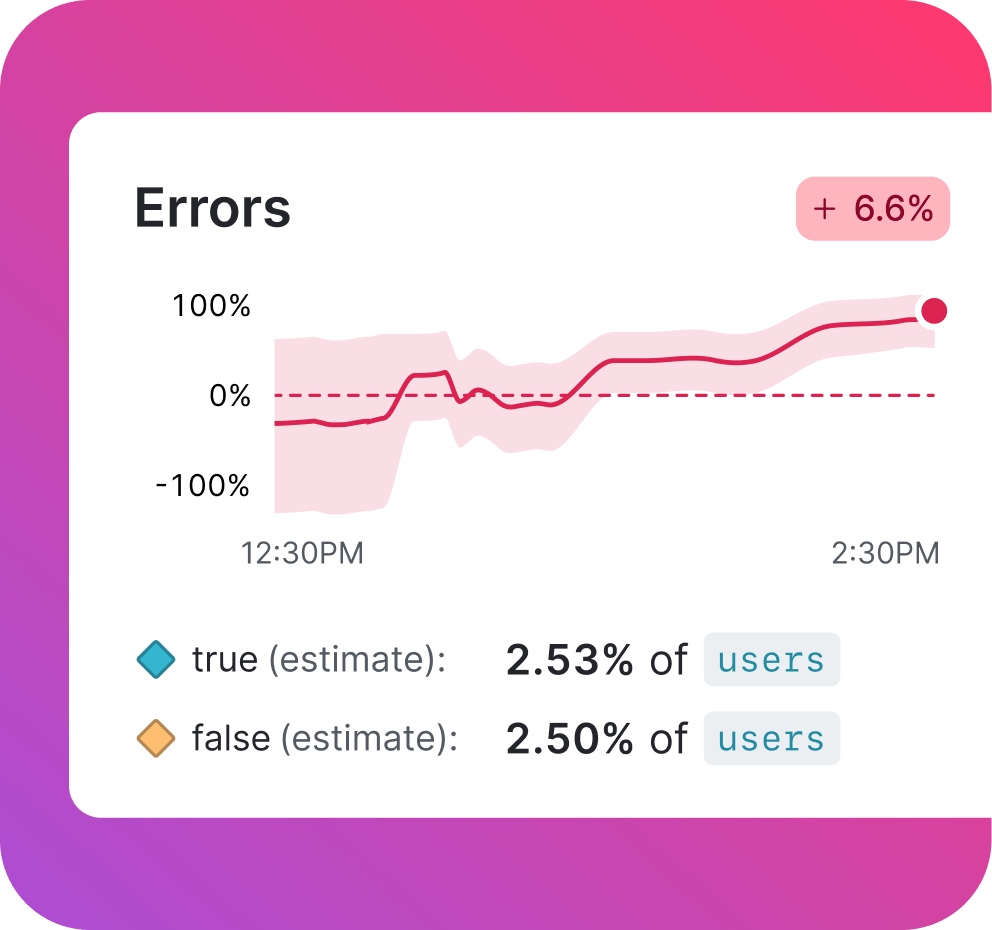
Prevent risky releases from ever reaching customers.
Roll out changes progressively and monitor key signals with Guarded Releases to stop risky releases before they escalate.
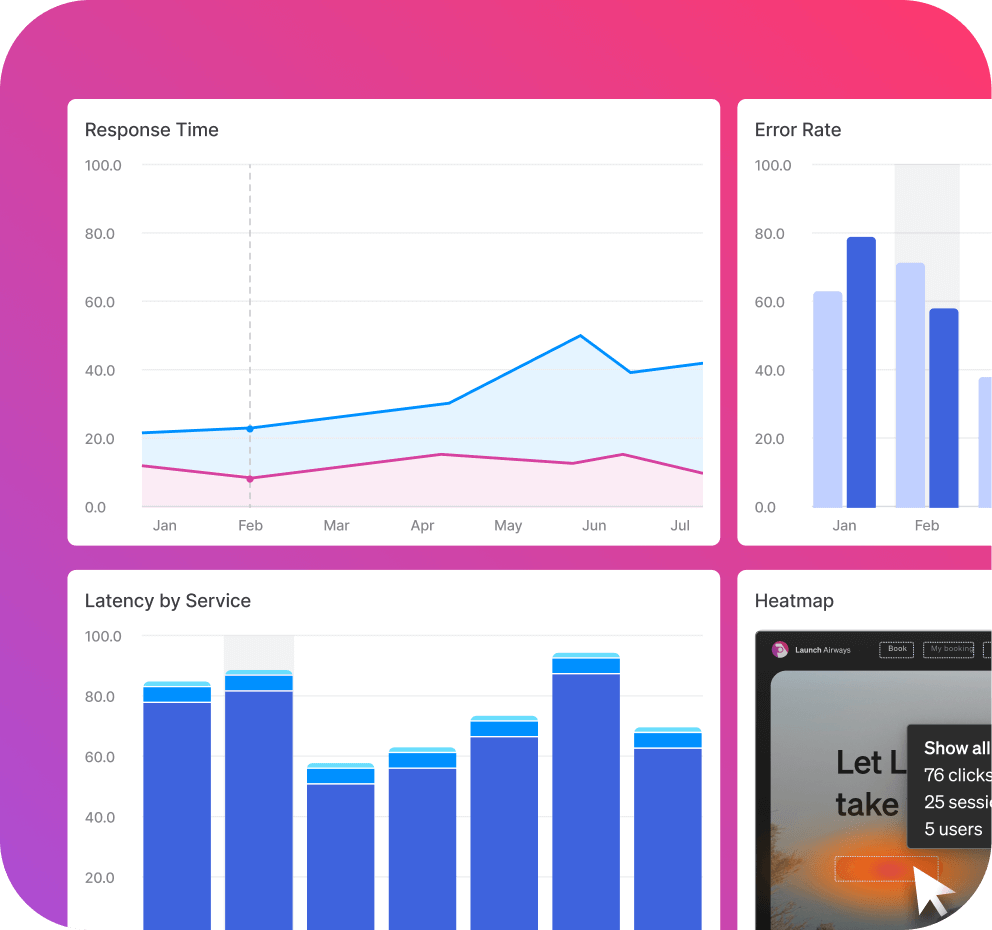
Spot performance risk as exposure increases.
Track service and endpoint performance across environments and flag variations with APM to catch regressions early.
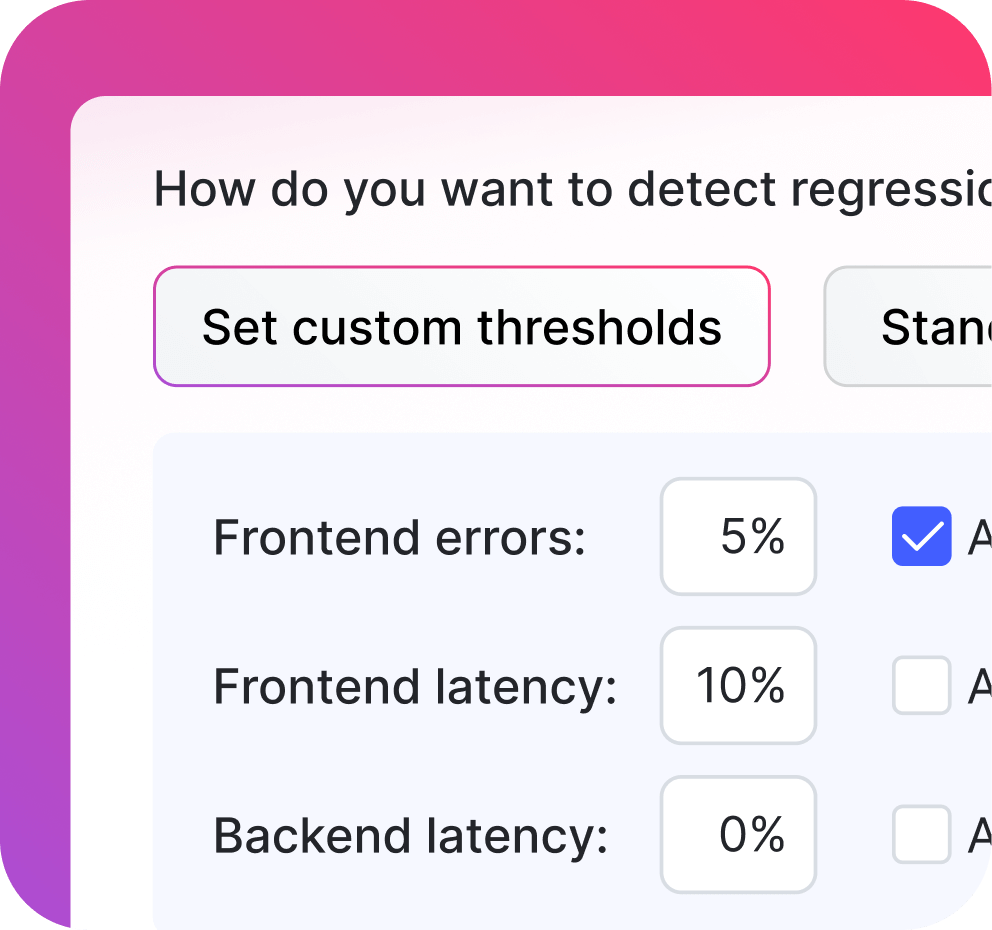
Keep unsafe changes out of production.
Automatically roll back unsafe changes when performance thresholds are breached—no redeploys, no downtime.
Blue Cross of Idaho cuts customer portal troubleshooting time by 75%.
/ /
We've revolutionized our approach to problem-solving, identifying root causes in a tenth of the time it used to take. This leap forward delivers substantial benefits and a clear return on investment.
Read more


Learn more about Observability.

DEMO
Move at AI speed. Stay in control at runtime.
Watch how LaunchDarkly gives you runtime control after deploy — so you can release safely.

BLOG
Self-healing software with release observability
Ship faster, sleep easier, and catch bugs before your customers do.

VIDEO
Session Replay | Product Updates
See how users interact with your website, product, or app, so you can better understand the errors and troubleshoot.

VIDEO
Error Monitoring | Product Updates
Debug quickly and connect the dots between errors and specific features.

VIDEO
Debug & Triage
Features around observability that make it easier than ever to triage and find root causes to your releases.

VIDEO
Introducing Vega: The AI Observability Agent for Faster Debugging
Built into LaunchDarkly, Vega connects observability data with AI reasoning to help you understand incidents.

VIDEO
How Heat Maps bring real user insight into your release workflow
Heat maps change that by surfacing interaction patterns that explain how people move through an application.

VIDEO
How to capture in-app user feedback for better feature releases
Understanding user sentiment helps teams improve features with confidence.
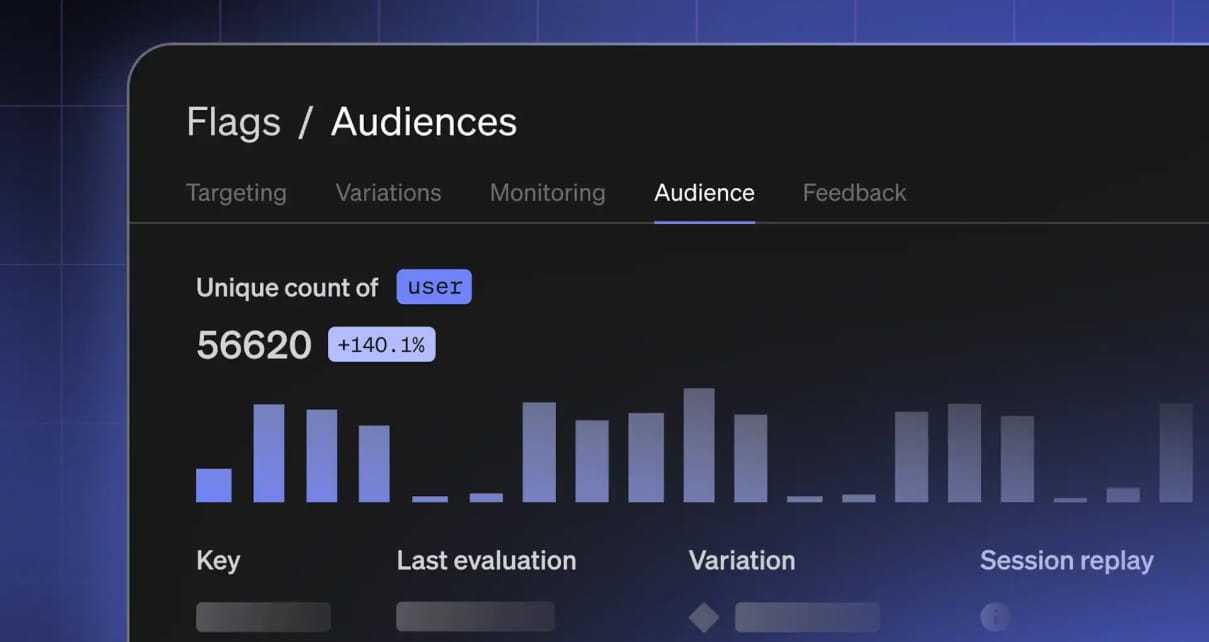
BLOG
Introducing Audiences: See who your flags are really impacting
Instantly trace who saw your flag and what happened next.











Get started with AI-powered observability
