





It only takes one bug
In July, a software outage battered several industries across the globe, costing the Fortune 500 an estimated $5.4 billion. The incident is a poignant reminder of just how devastating a single bug can be.
These same risks threaten financial institutions: from banks and fintechs to brokerages and insurance companies. Failure to properly manage risk in your software systems could lead to catastrophe. Thankfully, you can avoid this with five powerful strategies.
In this article, I’ll share strategies that engineers at your financial institution can employ to all but eliminate risk from delivering and operating software in production.
1. Deploy code to production first, release to users later
Traditionally, developers will deploy software changes to a production environment and release them to all users at the same time. The deployment and the release are tightly coupled. To deploy to production for the first time while simultaneously releasing to millions of users is a scary proposition.
Given the risks, teams spend weeks (or months) testing features in artificial environments. Launches are plagued by dependencies, bureaucracy, and risk. Moreover, developers often have to execute these stressful releases in the middle of the night or on weekends.
Developers will perform blue-green deployments in an attempt to separate the deployment from the release. But this only mitigates risk partially. If an incident occurs when routing traffic to the new app version, it requires an emergency rollback or redeploy. Regardless, there is an easier way to decouple deployments from releases: feature flags.
Feature flags let developers deploy changes to their codebase without exposing them to end users, a pattern called “dark launching.” This lays the foundation for testing features in production behind the scenes, which further reduces risk.
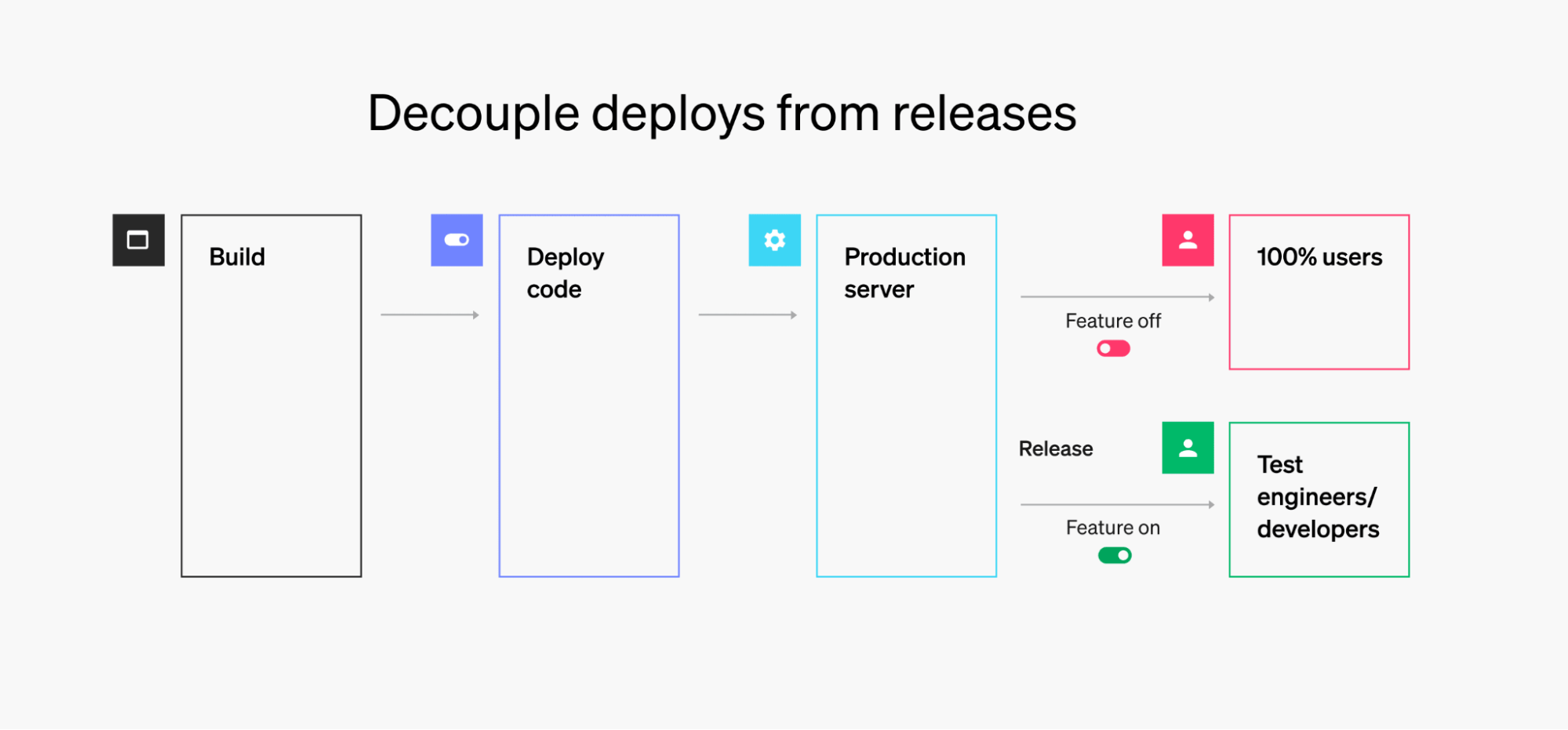
Example: Mobile banking app
With dark launching, mobile developers independently merge their changes with the mainline (trunk) every day. And they don’t need to worry about whether the mainline gets deployed. Their changes will be shielded from production traffic.
Moreover, when dark launching with feature flags, mobile developers submit their features to the app store for approval as soon as they’re ready. But they wait to release them until a later date. The app store approval process has no bearing on when they choose to release features to banking app users.
Decoupling deployments from releases is the foundation upon which the other risk mitigation strategies are built.
2. Progressively deliver to subsets of users
Shipping code without having to release it does, indeed, reduce risk. But at some point, you’ll have to release to your userbase. What then?
It’s a fair question. Any time you release to all users at once, you run the risk of shipping a bug to potentially millions of people. To mitigate this risk, we advise progressively delivering features to small audience segments at a time.

Example: Brokerage firm investment portal
A brokerage firm wants to release a new portfolio analysis feature to its online investment portal. If they release to all users in one dramatic launch, and a bug lurks in one of the features, the impact will be widespread.
Choosing progressive delivery, the firm rolls out the feature to just internal developers at first. Once the feature undergoes testing, developers expand the rollout to a small percentage of high-value customers. Upon passing that gate, the rollout is expanded to additional segments based on geography, customer tier, or some other parameter.
By gradually releasing the feature, they can monitor for performance issues and make adjustments before scaling up. Even if a feature contains a bug, they’ll have shrunk the blast radius considerably. In this way, progressive delivery adds yet another layer of risk mitigation.
3. Use kill switches as a safety net
At this point, you’ve gained much more control over when you release and to whom you release. While these capabilities do a great deal to mitigate risk, they are incomplete; they fail to help you recover faster when incidents do occur.
Typically, if an incident is severe enough, multiple engineers will work furiously to find the cause, write a fix, and then push the fix through their deployment pipeline. This can take hours. Or they’ll roll back to a working older version of their application. This, too, can be time-consuming. Such approaches prolong remediation and hurt the customer experience.
If you use feature flags as kill switches, you will recover faster—much faster.
With feature flags, you tend to ship smaller changes more frequently. And you isolate those changes. This makes it easier to pinpoint the cause of an error. What’s more, feature flags allow you to turn features on/off for specific audiences with the click of a button. If a feature causes error rates to spike, you can disable it instantly, in effect, hitting a kill switch.
Example: Life insurance claims processing bug
A life insurance company updates a claims processing feature, and it causes latency issues across their entire portal. An on-call engineer gets paged at 7:30 p.m.—presumably a time when customers are trying to file claims.
With a kill switch in place, the engineer immediately disables the faulty feature in runtime. That is, they neither have to trigger a new build nor roll back an entire release. They hit a kill switch and immediately restore the web portal to healthy latency levels. Then they go about their evening.
Feature flag kill switches enable you to improve your MTTR dramatically and provide reliable digital experiences.
4. Change broken configurations on the fly
Risk abides in your digital infrastructure regardless of how frequently you introduce change into that environment. For instance, if a critical third-party service goes down, it can bring your app down with it. Or when one of your APIs fails, it jeopardizes the operational health of your system. In both scenarios, the incidents were caused by something other than a new code deployment.
Without a way to quickly change back-end configurations, you run the risk of a full-blown outage.
Thankfully, you can use long-term operational flags to change configurations on the fly. You can strategically place these flags throughout your code and have them govern important parts of your applications. So when, say, a third-party service causes errors, you can disable the flag controlling that service to preserve uptime.
Example: Payments processing in a fintech app
A fintech app relies on a critical API for processing payments. If a DDoS attack throttles the API, it will disrupt customer transactions.
By using long-term configuration flags, the fintech can quickly change the API rate limit and set specific rules to block high-volume transactions from bad actors. This prevents the system from crashing under stress. And it minimizes disruptions for customers making legitimate transactions.
Using feature flags for runtime configuration management is yet another building block of a robust risk mitigation strategy.
5. Implement a monitoring and automatic remediation solution
Engineering teams use monitoring and observability tools to detect anomalies, performance degradations, and other issues in their software systems. These tools excel at detecting larger issues, but they’re less equipped to spot degradations in smaller progressive releases. Moreover, while they detect issues, they do not remediate them automatically.
The final, most advanced stage of risk mitigation maturity is to implement a system that 1) offers feature-level monitoring to correlate regressions with canary segments of any size, and 2) automatically remediates the issues it uncovers. Such a system takes manual kill switches and automates them.
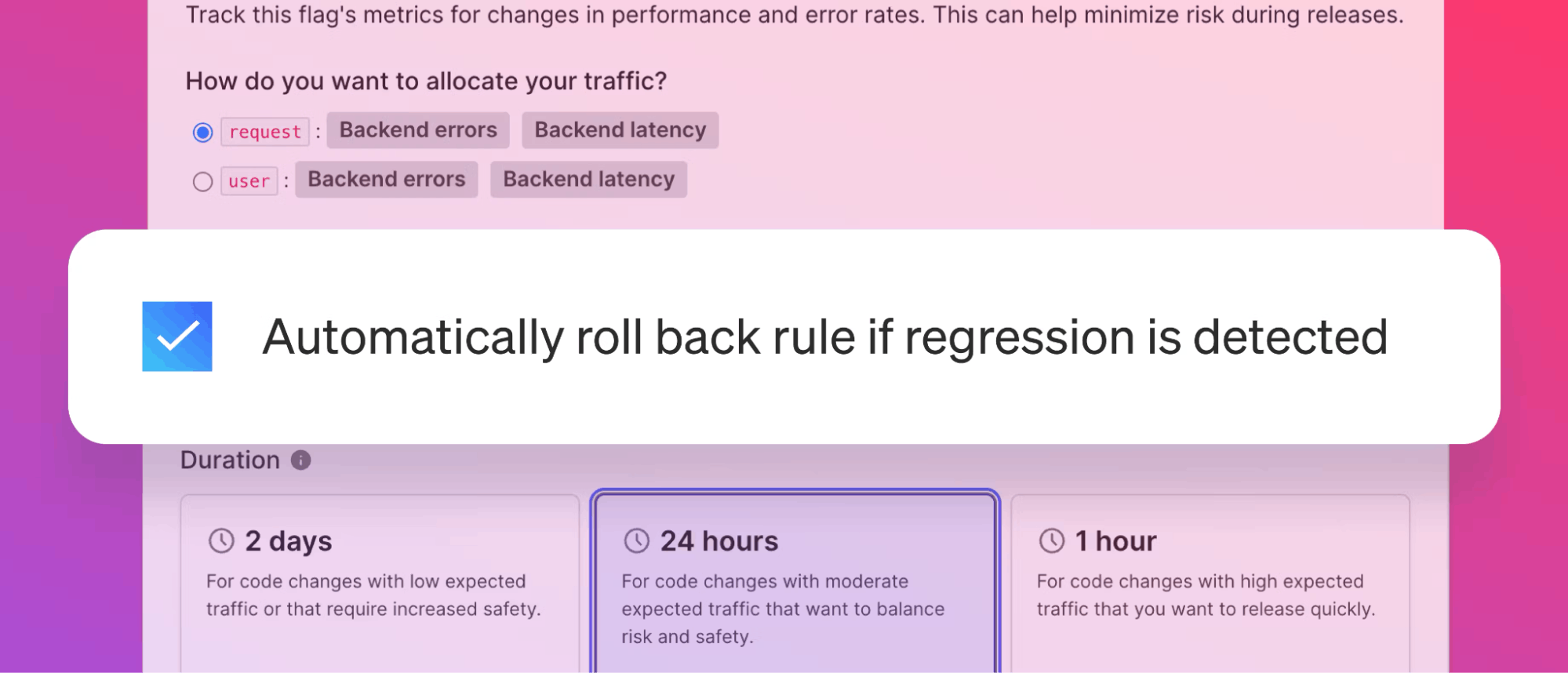
Example: Wealth management platform
An engineer for a wealth management platform is feeling bold and decides to ship a software change on Friday at 5. They stop for pizza on the way home and forget all about the deployment. Turns out, the change had a bug.
Thankfully, the engineer had done a percentage rollout, limiting the impact to customers. But what especially made the difference was they had a feature monitoring system watching the release in the background. The system detected the issue and resolved it instantly—all while the engineer was wolfing down pizza.
While automatic remediation is an advanced risk mitigation strategy, you can accomplish it with LaunchDarkly.
Reduce your liabilities with LaunchDarkly
If you standardize the five risk mitigation strategies across your engineering organization, you will likely see dramatic improvements in your change failure rate, MTTR, and overall system reliability.
As you might’ve guessed, you can easily implement these strategies with the LaunchDarkly feature management and experimentation platform. If you’re a financial institution, and you want to reduce risk in the ways described, then I’d encourage you to explore LaunchDarkly’s solutions for the financial services industry.
Like what you read?
Get a demo