





Operate, the second of the Four Pillars of Feature Management, encompasses feature flag use cases that improve the operational health of your application. It entails making feature flags a mission-critical piece of your operations. As deployment speeds and infrastructural complexity go up, so does the need for operational safeguards. Feature management is that safeguard.
Teams that use feature flags via a feature management platform reduce risk and ensure customers remain satisfied with their service. They dramatically cut down on serious incidents. For example, Honeycomb has a “change fail rate” of just 0.1%, a feat shared only by the world's most elite software teams. And the company cites its use of LaunchDarkly as a big reason for its exceedingly low failure rate.
But even when teams that rely on feature management do face incidents, they recover much faster than they would otherwise. For example, Jackpocket cut its mean time to restore service (MTTR) down to less than 10 minutes after using LaunchDarkly. Learn more.
In Operate, teams are better equipped to meet their service level objectives (SLOs) and deliver the 100% uptime customers expect. The primary use cases of the Operate pillar include:
- Kill switches and circuit breakers
- Dynamic configurations
- Service metrics (reactive monitoring)
- Safe migrations
For all you DevOps engineers, site reliability engineers (SREs), software architects, and other ops professionals who feel left out of the feature flag discussion, this pillar is for you.
Kill switches and circuit breakers
Feature flags can be used as kill switches and circuit breakers. Both allow you to disable broken parts of your application instantly. Where they differ is in the duration they stay in your code. A kill switch is generally considered a temporary or short-term feature flag. It's something you use in, say, a product launch. A circuit breaker, on the other hand, is a more permanent, long-term flag.

Example of a kill switch
Let's say you release a compute-heavy feature, and it causes latency issues. If you've attached a kill switch to this feature, then you can shut it off as soon as you detect the problem. One person toggles a feature flag—that's it. Compare that to the pain of several people across multiple teams scrambling to change config files, restart the app for all users, perform hotfixes, do cumbersome rollbacks, and so on and so forth.
Kill switches give teams the confidence to release more frequently. For they know that if something goes wrong, they can click a button, and the problem is solved.
Once you've released a feature to all the intended users and are confident in its performance, we suggest removing the kill switch for that feature. Otherwise, technical debt will start piling up.
Example of a circuit breaker
You insert feature flags as circuit breakers, or control points, in areas of your code where you suspect an error might occur. The incident you're predicting might not happen today, it might not happen tomorrow, it might not happen ever. But if it does, it could set off a series of bad outcomes.
For example, microservices architectures often rely on various third-party services. If one of these services goes down, it can wreak havoc on your system and, consequently, your user experience. But if you attach circuit breakers (feature flags) to each third-party service, you can quickly disable a service that has suffered an outage. As such, you take what could have been a catastrophe and reduce it to a modest bump in the road.
Kill switches and circuit breakers give you more control over your application. They play a big part in enabling teams to move fast safely. What's more, they span all of the Four Pillars of Feature Management and are present in all the other use cases of Operate.
For example, when we talk about using kill switches and circuit breakers, we're describing dynamic configurations.
Dynamic configurations
Feature flags allow you to change configurations on the fly. This means you can change the behavior of your application without having to deploy new code, thus avoiding an application restart. If you've placed feature flags strategically throughout your code, then you can control your features in real-time. Dynamic configurations come in handy for things like API rate limiting, load shedding, and adjusting log levels.
API rate limiting when your APIs are getting slammed
Typically, when your API is getting throttled (say, from a DDoS attack), to block the offending domain, you have to change a configuration and then redeploy your application. Meanwhile, the bad actor continues slamming your API and disrupting your service.
But if you assign a multivariate feature flag to your rate limiting rules, you can adjust your rate limit during an attack instantly and automatically. Once a domain hits your API enough times, it will trigger your circuit breakers to deny access to the bad actor. Again, in this way, feature management enables you to maintain system availability for all customers.
You can also use dynamic configurations for more pleasant rate-limiting purposes.
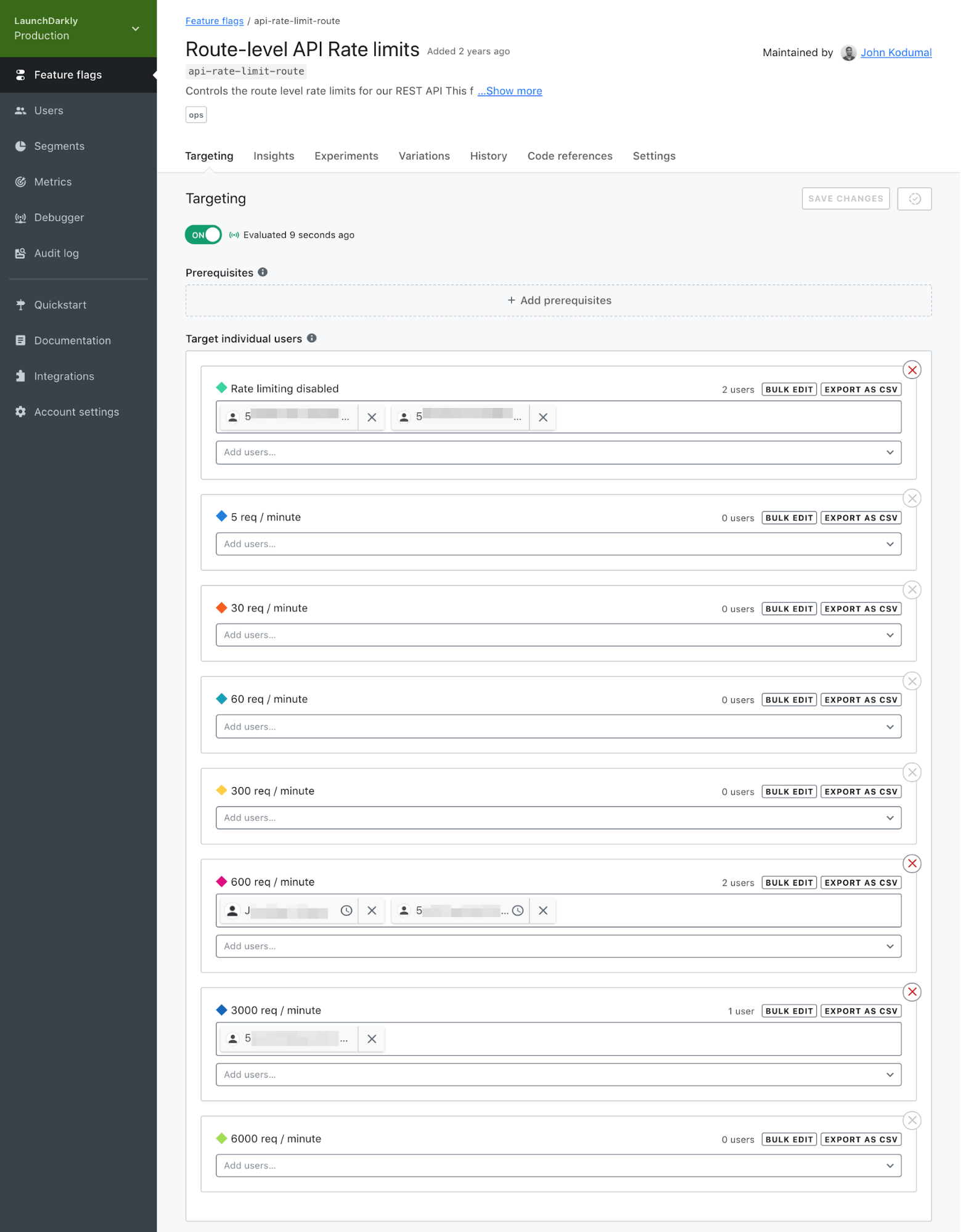
API rate limiting based on customer tier
You can also use multivariate flags and targeting rules to serve up different rate limits to different customer tiers. For example, you may offer 600 requests/minute to premium customers, 60 to standard ones, and five to free-version users. Any time someone signs up for, say, a premium subscription, the relevant feature flag will automatically set the appropriate rate limit. In this case, feature flags significantly improve your operational efficiency. We know this to be true because this is precisely how we manage our API rate limits in LaunchDarkly.
Also worthy of note, this particular rate limiting example fits into the Empower Pillar, in that it employs feature flags for entitlements. More on this in a future post.
Adjust logging levels on the fly
You can also use long-term operational flags to dynamically configure the mode of your server logs. For example, if your observability tool shows a spike in errors, the multivariate flag you've created will change the logging level from WARNING to DEBUG automatically and in real-time. This helps you find and resolve the source of the problem faster. And it also enables you to better regulate your server logs. After all, you don't want your app generating verbose logs any longer than it has to.
Everything we're describing in the Operate Pillar is much easier to do with a centralized feature management platform like LaunchDarkly. For example, LaunchDarkly integrates with several observability and application performance monitoring (APM) solutions such as AppDynamics, Datadog, Dynatrace, Honeycomb, New Relic, and Signal FX. These integrations help you measure how each feature affects key service metrics such as response times and error rates.
Service metrics (reactive monitoring)
When you pair a feature management platform with your observability and APM tools, it allows you to detect incidents faster and react to them in real-time.
Find the cause of an incident with feature flags
Imagine you're seeing a surge in error rates. This metric event will trigger LaunchDarkly to send feature flag event data to your observability and monitoring tools. Depending on the tool you're using, you'll see those events displayed alongside performance graphs. This, in turn, helps you quickly pinpoint which recent feature rollout, if any, impaired your service. In this way, feature management helps you rapidly determine the root cause of an incident.
This is half of the reason why LaunchDarkly customers are able to consistently lower their MTTR. The other reason is, once they find the source of the problem, they can fix it immediately with a kill switch.
Consider another example.
Load shedding
You can also use feature flags for things like “load shedding”. Imagine the response times on your website have exceeded a certain threshold. Perhaps an unusual number of users have visited your site. Let's further assume that you've integrated your observability and monitoring tools with LaunchDarkly. Moreover, let's say you've created a long-term feature flag that instantly disables non-essential services when toggled off.
The moment the metric event occurs, LaunchDarkly will be alerted to the issue and will automatically put your website in a degraded or reduced service mode. While this is not ideal, it does allow you to avert the disaster of having your entire website come crashing down. You keep the service running while you debug and troubleshoot.
Ultimately, tracking key service metrics alongside feature flag events improves the overall stability, reliability, and availability of your service.
Safe migrations
Feature management—and the feature flags that fuel it—also enables ops teams to perform safer infrastructure migrations.
Microservices migration
When adopting a microservices architecture, many unforeseen issues can arise. But if you employ kill switches at each stage of the migration, you can turn off a defective service the moment it starts acting up. This alone removes a good deal of risk in a systems migration. And it reduces the odds of you defaulting on your SLOs.
Database migration
When moving to a new database, you can use feature flags to perform a gradual rollout of the new system. For example, at the start of the migration, you can route 100% of ‘read' and ‘write' events to the old database, while duplicating 10% of the write events and then pushing them to the new database. As you monitor performance and see that your system has remained stable, you can then move to the next phase of the rollout, until 100% of events are funneled to the new system.
In this case, you would have performed a targeted percentage deployment. But instead of gradually rolling out new functionality to customers, you're routing data to a database. And if your application performance suffers during any part of the migration, you can halt the rollout with a kill switch.
Such an approach is safe and controlled. In fact, we followed this very process when witching databases at LaunchDarkly.

Cloud migration
Migrating your infrastructure from an on-premises data center to a cloud infrastructure as a service (IaaS) platform is a stressful undertaking. But feature flags make the project safe and smooth. For example, TrueCar migrated 500 websites to Amazon Web Services (AWS) Cloud with the help of LaunchDarkly.
As with the database example, TrueCar used feature flags and targeting rules to control the flow of web traffic between its legacy and cloud systems. The team would gradually increase the flow of traffic to the cloud when it became clear that it was safe to do so. They also used LaunchDarkly to route web traffic by request type. For example, web searches for “new cars” might have been associated with a cloud database, while searches for “used cars” were tied to the legacy system.
Feature flags simplified these complex routing rules. Moreover, LaunchDarkly's simple and clean user interface made it easy to manage the vast sprawl of web traffic flows. In the end, TrueCar completed its cloud migration with zero downtime due to infrastructure problems.
“Business users and application software engineers used LaunchDarkly’s A/B testing framework to manage traffic flows across the whole infrastructure. For that and many other reasons, TrueCar’s AWS migration was the smoothest, most uneventful of any I’ve ever managed.”
—Regis Wilson, SRE at TrueCar
Regis Wilson details his experience using LaunchDarkly for the cloud migration in a blog post he wrote. You can also read the full TrueCar case study. Lastly, you can learn best practices for infrastructure migrations in our LaunchDarkly Guides.
Feature management equips you with far more control over infrastructure changes than you would have otherwise. And it virtually wipes out risk in the process.
The benefits of Operate
When software teams engage in the core practices of the Operate pillar of feature management, they purge their operations of risk. This is especially true of those who use LaunchDarkly in conjunction with their monitoring and observability stack. Such teams achieve greater system stability, even as developers ship more frequently. In fact, the safeguards of feature management enable this increase in speed.
In Operate, teams experience fewer system failures; and when failures do occur, they recover faster—in some cases, in minutes or even seconds. Lastly, adherents of Operate preserve customer loyalty and trust. It's hard to put a price tag on that.
Like what you read?
Get a demo