
If the goal is delivering higher-quality software with less risk, it may sound counterintuitive to release faster and more frequently.
And yet, releasing at a quicker cadence can actually make your process safer, according to our Principal Developer Advocate, Heidi Waterhouse.
So if you're skeptical of how concepts like shipping faster and testing in production can actually improve your end result and strengthen your process, watch the the presentation below or dive into the full transcript.
Transcript:
Helen Beal:
Okay, I think it's probably time to get started. So hello everyone, and welcome to this InfoQ webinar, "Safe and Sensible Deployment and Launch with Reduced Risks" with feature management experts at LaunchDarkly. I'm Helen Beal, and I'm your moderator today. Our speaker is Heidi Waterhouse, the Principal Developer Advocate at LaunchDarkly. Heidi is going to present her thoughts to us for around half an hour and then we'll be having a conversation and taking your questions.
So when they occur to you, put them in the question box on your control panel and we'll answer them after Heidi's talk. Heidi, you and I have some things in common like having degrees in English literature and language. What else should the audience know about you?
Heidi Waterhouse:
Uh, I am in Minnesota where it is really, really cold right now. So I'm happy that I did not have to get out and go to the airport this morning because it's nine-below zero Fahrenheit when I got up this morning. Um, I sew all of my conference clothes, even now, which gives me a place to put the, uh, battery pack for the mic in the before times and now it just gives me a good place to clip the mic. And I really find DevOps is an interesting transformation because I've been doing software since the extreme programming days and I think it's fascinating to watch how it's developed.
Helen Beal:
That is just perfect, that's genius, making yourself little pockets. I love it. So tell us all about being safe and sensible.
Heidi Waterhouse:
All right. I'm excited to have you here today. I hope that you get something out of this presentation. Please remember that you can ask questions at any time, and we'll be happy to answer them afterwards. So I put together this presentation on being safe and sensible because I've been spending a lot of time talking about feature management and feature flags, and I get a lot of pushback about how dangerous they seem and how creepy it is for somebody who's doing enterprise level work to talk about going faster because it feels really unsafe.
Heidi Waterhouse:
So why is there so much emphasis on speed in the CI/CD world? Doesn't anyone understand that it's important to be sure to release only sound software? We're working on insurance and banking and healthcare. We're not Facebook, we can't, we cannot move fast and break things. It's deeply unappealing to anybody who's working in a regulated industry or who does operations because the things that break are seldom a developer's problem. They're almost always an op's problem.
So why am I in front of you today to talk about going faster if that's not what is going to be appealing to you? Am I just a hot shot vendor spouting nonsense that doesn't make any sense for your environment? Am I like Kelsey Hightower explaining to you that you shouldn't use Kubernetes in production because it wasn't ready yet? Do you know how many people adopted Kubernetes after that talk? It was appalling. He was appalled.

I might be a vendor who's just spouting nonsense, but I think I have something valuable to offer you, a way to think about being faster and safer. This talk is not a book report on "Accelerate," but it could be. "Accelerate" is a book about how deploying more often is intrinsically safer, and leads to happier teams. Dr. Forsgren goes into the research in this book, but I have some illustrations that might help you understand why going faster is not counterproductive to safety, but in fact, increases it.
So you should see a thing pop up on your screen that is asking you a question. How often do you deploy? Is it once a day or even more? Is it once a week, once a quarter? Don't ask how often I deploy, it's kind of embarrassing. Go ahead and answer that poll because I think it will be useful for you to like, stop and think about how a- often you deploy.
So when I'm talking about going fast, what I'm talking about is continually integrating and testing your code and maybe deploying it. It's not about waiting for long release cycles, or major revisions, at least internally. External releases and internal deployment don't need to be the same thing. In fact, in a lot of industries and a lot of software, it's a terrible idea to keep moving people's cheese, software experience wise, but that doesn't mean that we can't be doing things behind the scenes to get ready for a big change.
There are good reasons why external changes are complicated. The US Army estimates that every time Word does a major release, they spend something like $6 million retraining the people who use Microsoft Word in the US Army to use the new thing. And that's just one example of how much it can cost to make a big external change. And that's one of the things that constrains us from doing changes often, but we don't need to be hung up on that.
And then safe. Safe is about making sure that changes don't cause harm, and ideally, add some value. We worry about changes because we want to be sure that we're doing the right thing. Every time we change an experience or a behavior, there is a risk that it could go wrong. If you make small changes, there's less chance of enough going wrong than it's going to break something. This is the theory behind fixing a typo. Unless you're using certain versions of again, Microsoft Word, fixing a typo isn't going to break a text document even though it might break a code document, you want to make small changes.

I think of it this way. It takes real effort to lose $1,000 at penny slots because you're making tiny, tiny bets. Odds are, you'll need a break before you can feed that many pennies into a slot machine. But if you're playing at the $50 blackjack table, it might not take you long at all. You want the same thing for all of your deployments, for your bets to be so tiny, that losing some of them is small in the overall scope of what you're doing. You want to nudge the wheel just a little bit, you want to do small course corrections, no sudden jerks unless there's an emergency.
I'm from Minnesota, and like I said, it's really, really cold here this week. It's actually cold enough that the ice on the road sublimates, it doesn't even melt, it just evaporates. But when it's icy on the roads, we know that it's better to be in slightly the wrong place than to make a sudden move and break our traction lock with the road such as it is. Being able to gently nudge your software gives you a lot more safety than needing to make a sudden 90-degree turn.
So when you're thinking about why going faster with deployment might be safer, we're also thinking about how making smaller changes more often could be less dangerous. And you want to be able to answer honest questions. A team at Microsoft told me that their code doesn't count as finished until it's tested, and released and returning metrics. I thought that was such a great definition of done.
So often we stop thinking about code as our problem once we've released it, but returning metrics gives us the ability to understand how things are performing in the real world, in production, and how we need to be adjusting and changing how it operates in production.
Nothing is safe if we don't know what it's doing. It's just not complaining loudly enough for us to hear it. But we've all had silent failures and we all know that those are the worst kind of failures because we don't know that anything is wrong. So let's talk about the answers from your first poll. Can you put those up?
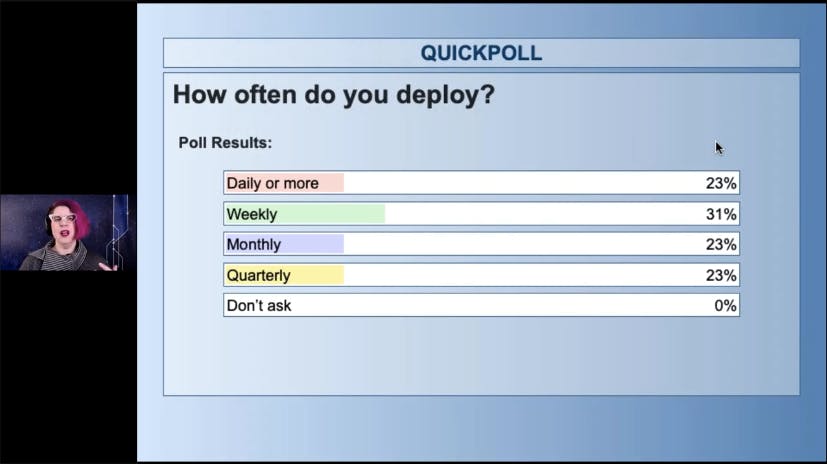
All right, we are very evenly split. About 23% of you deployed daily or more. About a third of you deploy weekly, 23% monthly, 23% quarterly. Fortunately for everybody, there's no one in the don't ask category, but I assure you I do talk to people who are like, yes, we r- release every half year. And it's a major production and it takes like a month to get ready for and everything is terrible. So this deployment speed is something that we talked about in the "Accelerate" book about how when you deploy faster, it becomes less of a deal.
Uh, when you're learning to cook the first time you make a fried egg, it's kind of hard. And the second time you make a fried egg, it's kind of easier. But if you're a short order cook, you don't even think about making fried eggs, you just lay the eggs out and eggness happens. And that's what we want for our deploys. We don't want to have to think about it. We want to just be able to do it.
So here's your second poll question. Are deployment and release the same in your organization? But I'm not going to define those yet because I want you to answer first.
Lots of people use these interchangeably and I think it's a, an interesting problem. All right. Deployment is not release. Remember what I said earlier about how deployment could go on behind the scenes and not affect release, and that we could all make small changes in deployment that didn't translate to user experience?
In order to do continuous integration, continuous deployment, continuous delivery, you need to really internalize that getting your code into production and letting users see it are two entirely different questions. They're not the same thing, deployment is putting things into production and release is letting people see that deployment is a software problem. It's a software organization problem. It's who codes things and whose ops releases a business problem, releases when users want to have it, but they're entirely separate areas of control.
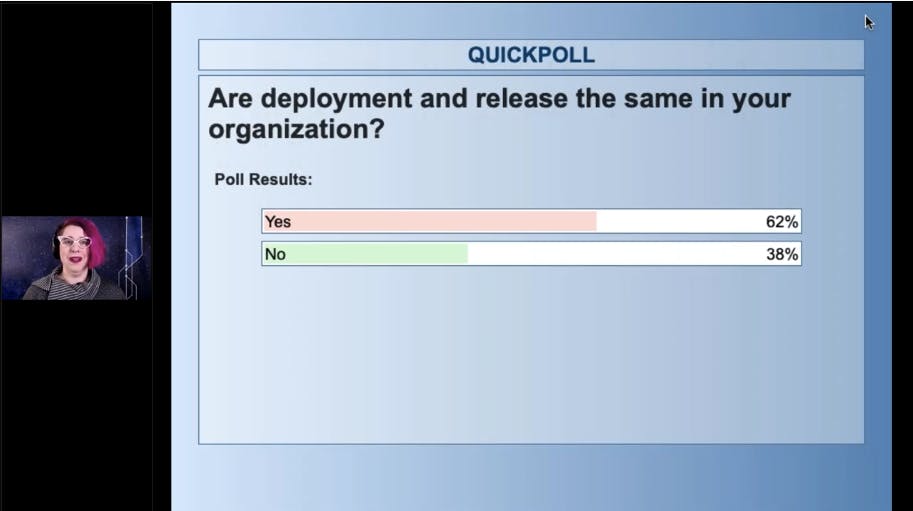
And when you separate those out, when you start thinking of them as different, you start to see why continuous deployment makes sense even if you can't be in an industry where continuous release makes sense. So let's go ahead and look at your answers for that. I got a sneak peek at these and I'm not surprised. For 62% of you, deployment and release are the same thing. Wow, what if we can decouple those? What if I said to you, "You can deploy on Friday, and let everything soak in production, but nobody sees it." Nobody knows that it's there. It's not affecting anybody.
And then when you're ready to release in a week, or at your quarter, or whenever it is, then you turn it on. And everybody has the same experience. It's a revolution in how you think about CI/CD. Let's talk a little bit about what we mean by the difference between experience and function. All right? Operational is not the same as perfect. Have you ever been on a flight, do you remember flights? I remember flights.
Have you ever been on a flight that was delayed for something that seemed completely trivial? Like a broken latch on a bin or a seatbelt? That's because planes are made of hundreds of thousands of parts. And lots of them are critical for health and safety. And there are some things that force an immediate grounding, but there are some things that exist in an error budget. A set of things that could go wrong without directly endangering anyone, but shouldn't occur in large numbers because it reflects the state of maintenance of the plane.
If a plane exceeds its error budget, even with a broken latch bid, it gets grounded until the number of broken items dips back below the error budget. All right, we're thinking about that. Every plane you ever gotten on is broken, it's just not fatally broken. And every release you've ever made is probably broken. It's just not fatally broken.
So let's think about networks and network capacity. We've learned that computers and networks operate really poorly as we approach 100% capacity. That's because the break point is at 100%.
It's much better to over provision a network and run it 80% so that if there is a sudden spike, we don't break and we can keep running. When we reverse that network thinking to software, we can think of designing our systems. Our microservices are known fragile parts to work effectively, even if they can never be perfect. We can build some slop in, we can have some redundancy. A perfectly optimized system is very brittle because it does exactly what you need it to do and nothing more and we don't live in a world where nothing more is ever demanded.
Sometimes things go wrong. Sometimes we need something to happen. This talk is about feeling safe. I really want you to leave this talk inspired to make your workplace feel safer for you. And one of the ways that we do that, and again, it comes out in the "Accelerate" book is psychology. It turns out that being safe on our teams, feeling safe as humans, lets us make better software avoiding errors is not actually the best way to code something that's solid.
In fact, we need to embrace the fact that there will be errors in order to code something that's resilient. So here's the third poll question. What makes deployment psychologically difficult for you? What makes it scary? What's the hardest part of how deployment goes for you? And remember, I'm talking about deployment, not release. What is the hardest part? Is it testing? Is it getting all of those tests in and also the test from QA who makes your software do things that it was never intended to do?
Is it compliance? You have to fill out all the ticky boxes and they're very important ticky boxes, but you have to fill them all out? Is it risk? Is it like if we launched this, we could take everything down? Tell me what you're scared of. We'll talk about that in a bit. What makes you feel safe? You want to have a trustworthy team, you want to have management that's trustworthy and you want to believe that deploying faster is going to be safer.
The way I explained it is this, when you're an adult, a parent who's teaching a kid to ride a bike, the thing you say to them is pedal faster, and you won't fall down. When you're a kid who's learning to ride a bike, you're like, "I've fallen down before, I'm pretty sure concrete is hard. I'm not sure how going faster is going to make that better." It seems like that would hurt worse. As an adult, you understand that physics means that going faster means that you have more angular momentum, and blah-blah-blah you're going to stay upright.
As a kid, you don't have that faith until you can experience this. This is why so many of us had a parent run along behind us and push so that we could get up to speed and start to feel, start to experience how much safer it is to go faster. So that's one aspect of psychological safety.
Another aspect is that your team communication needs to be blameless, my therapist, my kid's counselors, and the character I have in a cartoon over my desk, I'll say the same thing. Everyone's doing their best given their circumstances.
People really don't maliciously fail or if they do, it's because they're reacting to structural issues. If they're doing things that seem harmful to us, it's because they're maximizing for something that we don't see or don't care about. I know it feels like people are jerks on purpose sometimes. What they are doing is maximizing something you don't care about. I think that a lot of the mask dialogue is about this. It's like I care about being able to breathe freely, or I care about being able to go out in public.
Like they're- they're maximizing different things. So what that means on a team doing software is we need to not talk about people like they meant to screw up because they didn't. The system has brought them to a place that they can't compensate for. Their skills are insufficient to deal with the broken system that they're trying to work in. It's an interesting thing to think about on your teams because I think we've all failed in our teams and we've all felt bad about it, but it takes a special kind of safe place to be able to say, "I failed, and here's the thing that our culture, our environment did that contributed to that failure."
It needs to be non-catastrophic. Mistakes are going to happen by the very nature of humanity. We can work to minimize the frequency, but our systems are both complex and involve humans and we can't get around that. So let the mistakes be small. Something you can correct with a nudge or a rollback or a flag flip. Something that isn't about downtime measured in hours, or costs measured in millions. It's a lot easier to be blameless when the whole incident report from report time to recovery takes less time than the post-event retro.
Make your changes small, use steering techniques appropriate to your speed and vehicle. The smaller the bet, the less catastrophic the outcome. So if you think about somebody again, who's- who's betting in Vegas like if you're betting your- your pocket money, your allowance, it's one thing if you're betting the mortgage, it's another thing and one of them is going to get you a lot more blame at home. The last aspect of psychological safety is curiosity. You can't be curious if you're feeling unsafe, you can't really ask good questions if the main question in your head all the time is, am I going to get fired?
So when we're psychologically safe, we have room to be curious. Why did it happen that way? What in the system caused that? What could we do differently? There's something we're not thinking about.
My wife used to do tech support at a university and she had this great story about a monitor that gave one of her users all sorts of trouble going out intermittently, but it never made sense. It wasn't timing, it wasn't software, it wasn't hardware. She finally got the idea to walk around and look at what else was going on and it turns out the monitor was against a wall that had an electron microscope in it.
This makes sense in a university, but it's unlikely to happen to most of us. The thing is the problem was solved because she was curious about what else could cause the outages besides the usual things. This is what the observability people are talking about. High cardinality data, and the ability to interrogate it gives you the chance to ask questions you couldn't predict needing to know about. Logging is about asking questions that you can predict. Observability is about asking questions about the unknown, unknown.
And I think making a psychologically safe team makes observability make more sense. In an unsafe team where there's a lot of blame going on, observability is harder to sell. One of the ways that we get psychological safety is by giving ourselves guardrails. If we know that there's something dangerous, we can add layers that prevent the bad thing from happening. Are you excited about the idea of Apple bringing back MagSafe connectors for laptops? Have you ever actually completely destroyed a laptop by tripping on the cord?
But even if you haven't, you're going to feel safer knowing it won't happen because of the MagSafe connector. It's a psychological safety that you find valuable. So there are two aspects to this. The first one is risk reduction. Risk reduction is trying to make sure the bad thing doesn't happen. It's things like vaccination, and anti-lock brakes and train gates. They prevent the bad thing from happening. They are guardrails that prevent us from going off the road.
Risk reduction is a really important part of how we design our systems, but we also have harm mitigation. Harm mitigation doesn't matter until something goes wrong. No matter how much we try to avoid and mitigate or avoid risk, the truth is that bad things do happen. That's why we wear seat belts and life vest and why we install smoke detectors and sprinkler systems and doors that swing outward. Ideally, we wouldn't have house fires in the first place, but if we do, we can design our buildings so we don't die of them.
Things like seat belts and building codes and RAID arrays exist because we know the bad things are going to happen. Drives do fail, buildings do catch fire, car accidents do happen. So if that's going to happen, how can we make this less catastrophic? How can we make bad outcomes less bad? Well, let's talk about the beautiful future of where I hope we're heading. In the beautiful future, a lot of our work has been taken by robots or automation. They're not smarter than we are, but they never accidentally add an extra space in Python.
As we climb up layers of the extraction from machine language, we get closer to telling programs what to do instead of how to do it. After all, we can only tell computers to be slightly dumber, it's more patient than we are. This is the airbag construction from the Pathfinder mission to Mars. This is a thing that NASA and JPL launched and they didn't know how it was going to land. But they knew it was going to land safely because it was going to bounce. All of these games like “Angry Birds” that have physics engines, nobody exactly sat down and calculated what each pixel deviant path was going to do.
We built an engine and then we said to the engine, take care of figuring this out. We want to test the experience of what people are- are having and not what we intended to do. It's really easy for us to think of tests and test results is real, but they aren't. They're symptoms of the living, evolving organism that is software. We have so many layers of distraction that we don't actually know what's going on. We just believe we do and the sooner we understand that we're dealing with a system and not just a program, the more we're going to learn to ask the right questions.
When we go to the doctor, the doctor doesn't ask us if our thyroid is feeling good because we don't know. The doctor asked if our hair is thin, if our muscle tone is bad, if our fingernails keep breaking, and if it seems like we might have a thyroid problem based on those symptoms, the doctor does a blood test and says, "What did they say? They say your thyroid stimulating hormone is very high, your body is trying to get your thyroid to kick in and it's not working very well."
We can't directly test thyroid hormone, we can only test the thyroid-stimulating hormone that tells us what our body thinks is going on. I think that's an important thing to remember when we're thinking about how testing in software works. And this quote is like the way to sum all that up. You can have as many nines as you want in your service. But if your users aren't happy, it doesn't matter. It doesn't matter if you have uptime if you don't have an experience that people are finding useful and reliable.
I want you to do all your things in production. Remember how I said that deployment was getting things to production and release was getting things to people? If you get things to production, you're going to be able to test them. Maybe some staging, but you can't replicate the level of traffic that you're getting on your service in any way other than production. You're not going to find the edge cases and problems without testing the amount of traffic. We have an enormous difficulty replicating the complexity, scale, interoperation and generalized weirdness of production.
You're going to pay for licenses for all of those APIs that your production server is linked to. Are you going to do artificial data that is weird and, uh, unnormalized on your test server? No. Test it in production, just don't show people that you're testing it in production. Test it in production, but keep it away from the general public because when you think about it, we're all testing in production.
We all find things in production that cause outages or poor experience, just some of us are doing it on purpose and some of us are finding out about it the hard way. So let's talk about the answers to question three.
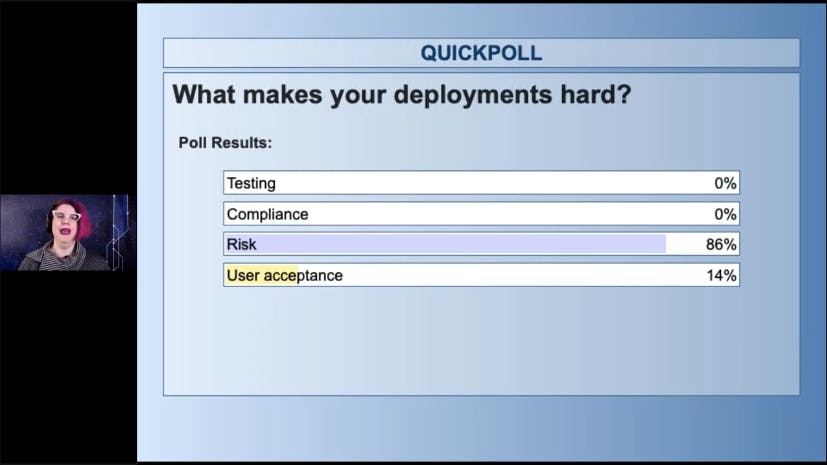
What makes your deployment hard? Almost all of you said it's not testing, we have automated testing for most of it. And it's not compliance, we know how to fill out the ticky boxes. It's risk. A thing that makes deployments hard is risk and the thing that makes deployments risky is making them too big and too slow and too massive.
If you make them smaller, it's going to be less risky, I promise. So what can we do about this state of constant breakage and unreliability? How can we make our teams feel like it's possible to try new things without taking risk? How does going faster matter? Well, it depends on how crucial your product is. If you're in a life critical software system, almost none of this talk is directly relevant. Some of it's indirectly relevant, but you have different constraints. But how crucial is your product, and how many people are using it?
If it's a news service, how spike resistant is it? Because the times that you get spikes are because people need the news.
So think about your product and your audience and figure out how much failure is tolerable. Reduce the potential for catastrophes. A catastrophe is when a bunch of errors pile up together. Humans are slow in reacting to emergencies, that's why we have circuit breakers. When something goes wrong, the circuit breaker makes sure the system fails to a safer state rather than causing harm.
So producing cascade failures is part of how we make sure that our deployments are less risky. Putting stops in to make sure that failures are contained to one area of the software means that you can keep working and reduce capacity. And adding control points to your system allows you to react flexibly instead of just turning it all on or all off. Maybe you're having page load problems and you could take off like the- the user ratings at the bottom and still have your core business functionality.
Think about where you could add controls to bypass third-party integrations or known flaky servers. So here are the things that help reduce catastrophes, by breaking your risk up into smaller chunks. Circuit breakers, isolations, control points, the ability to do rapid rollback, layered access so that people can't just YOLO things into the public and using abstractions to manage your change because failure is inevitable.
It is the condition of everything we do, every complex system has a lot of failure modes, but catastrophes are almost never the result of a single failure. Instead, they're a collection of small failures that systems of safety protect us from most of the time. It doesn't matter that you put the lid on your travel mug wrong until you start to grab it, uh, drop it and grab it by the lid. Most of the time, it's not going to matter until it does.
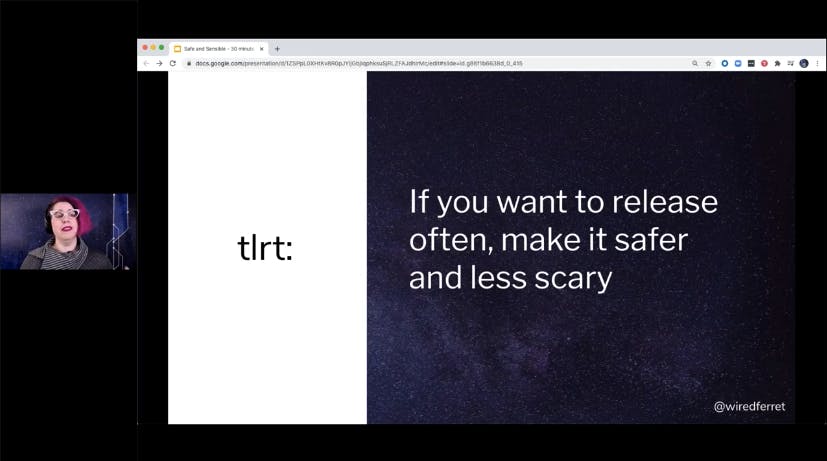
So if this talk was too long, and you read Twitter instead, let me say if you want to release often, and you do, make it safer, and less scary by making it smaller, and more often. So thank you for your time. I'm happy to a- answer your question. It's going to be great.
Q&A Session
Helen Beal:
Oh, it was fantastic. Thanks so much Heidi. We have some feedback from Eric in the audience, almost a religious fervor when you were talking about psychological safety and particularly, the elements of being blameless. He said he's really concerned about this for him, um, and others. Um, I've done some research into blame and actually one of the things I've discovered in some of the reports I read is that blame is actually addictive in the brain, so it kicks off your addiction circuit, so we really like it as humans.
I assume that that's because we're kind of making ourselves free and it feels good that we've- we've- we've now got that stressed away from ourselves. But I wonder- wondered what tips you have for the audience on how to move from a culture of blame into a culture of accountability, what- what works?
Heidi Waterhouse:
So Etsy did a lot of pioneering research on how to do blameless, uh, PagerDuty has certainly continued their ... It- like, I realized they're not all doing incident response, but their discussion about how to make a culture more, less- less, less blameful and more investigative and researching. Uh, those are the two places that I'd look to start, but I think it's useful to understand why you're being rewarded for blaming people.
Like I did a talk a couple years ago about dog training, and humans. And honestly, all of the best management books I've read are dog training books because once you take the like human interaction element out, you can really see that we do things that we are rewarded for. And we avoid things that we are punished for. But actually, the reward stimulus is much stronger. So when we want to make a more blameless culture, what we need to do is start rewarding people for doing the right thing.
So I've worked at companies where people get an award for taking down production. They're like, "Hey, you found a new way to take down production, you get, you know, ad-, like, we fixed it now, you get a dinner out for finding that flaw. And now we fixed it, and it's never going to go down that way again." That makes it a lot less terrifying to report that you've taken down production if you're going to get a treat for it than if you're going to get fired for it.
I really like the stories about AWS where like if S3 goes down, we all have a bad day, right? Um, and somebody said, so the- the guy who pushed the button that took S3 down, I think it was like five years ago, uh, did he get fired? And they're like, "First of all, we're not telling you who- who it was because that would lead to blame. And second of all, no, we just spent millions of dollars teaching him never to do that again (laughs), and teaching our organization that we needed a guardrail there."
It's not human error, it's a system failure of there's also a bunch of stuff uh, Paul J. Ree- or J. Paul Reed, uh, does a bunch of stuff on how to do blameless culture and risk and- and analysis. Um, I'm trying to remember the name of the conference, it was really great. I want to say it was REdeploy, uh, where we just talked about failure. So talk about failure in normal life, it- and when you make it smaller, it's a lot easier to not get completely bent out of shape.
I- I love that dog training idea and I love that you- you really get how the brain is working. So what's happening there kind of from a familiar neurology perspective is right at the back in our amygdala. Um, we've got our kind of fight, flight response, our kind of basic lizard brain. So we've got, um, our avoidance response when we're afraid of something and then as you've said, um, the novelty, um, drives our approach response and that is stronger. So if we can switch people from, um, fear and avoidance to novelty and approach that really, really helps, but, I think [crosstalk 00:35:11]
Heidi Waterhouse:
Oh sorry.
Helen Beal:
That's okay.
Matt Stratton does a great talk called, uh, flight, fright, or freeze about learning to do, uh, less blameful culture. And it's very much, um, about PTSD. And- and the psychological trauma that people can end up with especially from working in Ops because it's been so blameful for so long.
Helen Beal:
Yeah, deeply damaging. So we definitely need to find ways to help people get out of that- that cycle. And it's really interesting that, um, you talk about catastrophic failure. And then there's different types of failure. And I think there's different shades of failure. And I want to link that to the poll that you did where, um, 86% of people reported that the biggest challenge they had in deployment was around risk.
So I'm wondering if there's any tools or frameworks or ways that we can help people balance those shades of failure with the- the risk profile, how do they build like a matrix? Who gets involved, um, from the organization in terms of making those decisions? And is there any way to automate some of the decision making perhaps using AI ops or monitoring around SLIs or something like that? What do you think?
Heidi Waterhouse:
Um, so in a couple weeks, I'm doing a- a presentation with Dynatrace about pretty much exactly this. Uh, we call it automatic remediation. Uh, so if you're using AI ops to monitor all your stuff, there's no reason you can't set up triggers with feature flags to say like something's going wrong here, we're going to shut off whatever it is and then we will loop a human in, like a circuit breaker because if we give people a little more time to react, instead of like rolling out of bed and trying to figure out what's going on and turn it off, and maybe they can't turn it off easily. Maybe you have to redeploy and every time you redeploy in a hurry, you're taking a bigger risk.
Instead of doing that, I think we can use all of our monitoring and alerting and awareness to be able to turn things off or turn things down. So that we have a lower level of risk. I think the people who need to be in the room when you have this discussion are the people who are closest to the customer. Uh, that's who we forget to include in these, these risked conversations. Uh, we get the, like the closer to the customer we get is the business owner was like, "I will lose money if you go down. Don't ever do it."
Like, "Yes, we're trying not to, but you're not helping by stressing us out." I'd say invite customer support, invite product management, they're the people who are closest to the sharp end of the stick for your users. And you can say like what would be better for the users if they had reduced functionality for 10 minutes or if they had no functionality for 30 seconds? Like you're the people who know which one is better.
And in some organizations, in some things, like out for 30 seconds is better than reduced functionality. But for most of us, reduced functionality is much better than outage. So whatever your business needs are, you should be talking to the people who are super close to the users who can represent the users and say this is what our users experience and need.
Helen Beal:
Absolutely, it's all about the customer, isn't it? And I love that quote that you put up. Was it Charity Majors?
Heidi Waterhouse:
Yes.
Helen Beal:
Yeah, so the mindset matters if the users are unhappy. So if we extrapolate that a little bit more, so it's not all about performance, right? It's about value. So how should teams estimate what value they want from their product enhancement or their new feature? And how would they go about measuring whether that, um, deployment or release of the actual feature, um, is doing what they- they thought it should? How did they do that?
Heidi Waterhouse:
So I think A/B testing is like the way here. For anything that's customer facing, um, we want to talk about progressive delivery. We don't want an all on or all off delivery mechanism. Um, because relief is once you've decoupled it from deploy, there's no reason it can't go slower than that. So I keep bringing up Microsoft, I just talked to them recently which is why. Um, they have something a model they call ring deployment.
And so you have a new feature and you deploy it to internal customers, like in- inside people in your own company, and you monitor it and if nothing blows up, you go to your like beta users, and if nothing blows up, you go to like 10% of your users and you automatically scale out instead of doing an all on or off, but then gives you a chance to see if your product is actually doing what you expect it to do, if people are taking it up, if it's causing weird performance problems that you didn't anticipate.
So when we're talking about A/B testing, a lot of people think of this as a front-end only activity, but you can A/B test like trace routes, you know. Is- is this pathway more efficient than that pathway, uh, is- is this, you know, a set of clusters more responsive than that set of clusters? If you can switch your traffic in any way, you're going to be able to see which one's more efficient. And then again, I think that a AI- AIOps could come into that and say like, "I'm automatically routing through like the, you know, 200 different possible routes, this one's most efficient and I'm going to send most of the traffic that way." Without needing human intervention.
Helen Beal:
So I'm going to pop in a- a question from the audience from, uh, one of the answers in for a moment which is about continuous deployment. So the question, uh, really is, um, does this require us to use continuous deployment? And does everyone have to do, um, continuous deployment? Is it- is it a must?
Heidi Waterhouse:
Uh, I think that it will become more and more the norm. We're not cutting gold master CDs anymore. Almost all our software is delivered over the wire somehow. And so when we're doing continuous deployment, what we're doing is catching up to the fact that our technology is kind of always on. Um, and continuous deployment gives you the opportunity to make sure that things are going to work well when you actually release.
So the high-performing teams in software currently are all doing CI/CD, or something very close to it. They're doing very rapid deployment like the birth of DevOps is probably the like how we do 10 deploys a day talk, right? Like that was- that was the aha moment for so many people. They're like 10 deploys a day, are you nuts? Isn't that- what- Why would you do that? And- and now we're talking about people who have trunk-based development, and CI/CD, and Google is literally never not deploying, Facebook is never not deploying, there is no moment when they're not rolling new code in.
And I think we're going to, especially if you're doing SaaS, Software as a Service, you're going to move to that. If you're doing things that are more regulated, um, maybe not, maybe like some variation on that. Uh, but I've been surprised by how many people end up being able to use it. Like, I wouldn't have thought IoT was conducive to continuous deployment. But it is, like there's no reason you can't push things out when you get a chance whenever your device calls home.
So I'm glad you mentioned regulated indu- industry, so I was going to mention them, um, next. I've had the privilege of working with quite a few banks and insurance companies. And when I worked with them, I often do kind of definitions of what continuous integration is and we say set when all developers commit daily to trunk and we do a number of tests, probably unit integration and user acceptance, um, before it's accepted into trunk.
Um, and then we've got continuous delivery which we talked about being the state that you get yourself in when you're doing continuous integration and that your software is always in a releasable state. And then we talk about continuous deployment and the different side kind of talk about is setting continuous delivery. We've got a manual intervention before we go to deploy and release whereas with continuous deployment, if those tests pass, it goes all the way through.
And those regulated industries I work with, they're always really nervous about and they'll kind of say, "Well, we'll never get there. We're never going to do continuous deployment. We'll just stick with it, that manual intervention." But of course, that- there becomes a point where it becomes impractical when we're doing X amount of, um, deploys and releases, um, a day and you don't really want somebody to start there pressing a button.
Helen Beal:
So how can we collect data from, um, your kind of system and other related systems perhaps things like Dynatrace that can help people build the evidence to communicate with their teams that, um, they should be trusted to perhaps experiment with continuous deployment and how can they build that proof?
Heidi Waterhouse:
I think one of the things that is useful for people in regulated industries is to CI/CD a non-critical part of their infrastructure and see how it goes. Like other people's numbers are never going to be as compelling as your own. So if you're in banking, you have all sorts of extreme regulations around how you handle money, uh, but you have less regulation around how you handle your website. So like partner with the web team and see if you can like get closer to CI/CD with them and then collect metrics on how many failures do you have and how many unexpected events.
And if that number is lower, I think it's more compelling. If it's inside your own organization than if somebody's like, "Well yes, I'm- I'm trying to think of which banks that are our custom-" We have several banks who are our customers at LaunchDarkly and, uh, they use it for all sorts of stuff. Like we do payroll processing, organizations and stuff like that. Um, they just use it in a way that sort of sneaks up on doing the- the regulated industry part, uh, so that they can figure out what they need to collect to be reassuring.
Helen Beal:
It's such a great practice on a low risk application. It's yeah, it's such a- a- clever way of- of getting that evidence building up. Uh, we have another audience question from Raymond. He says, "You considered risk as the uncertainty of something going wrong. However, uncertainty also impacts things that need to go right. What have you seen organizations do to ensure that software deliveries have the intended outcomes in the presence of uncertainty?"
Heidi Waterhouse:
I think you need to test for that. Um, a lot of times when I say test in production, people feel like I'm giving up on testing and that w- I'm not. I want you to be doing your unit test, I want you to do your integration test, I want you to do your acceptance test, I kind of don't care about your staging test because it's a lie, the comforting lie that we tell ourselves, uh, because staging is a lie. I mean, it's not real.
We- we- we still have a staging server, but like stuff passes through it in about half an hour. Um, so when you need to know that something's working, you still need to have a test on it. Like am I getting the positive affirmative response that I expect from this change? Uh, is it actually out there working the way I think? And that's what instrumenting all of your data is about so that you can go out and say like, "Did the feature get out there? Is anyone using it? Is it performing the way I expect?"
Helen Beal:
We have this thing certainly about being experimental and I think this might be a psychology question again, it's like, I think it's to- maybe to do with command and control hierarchies, but we're tempted to do work and if it doesn't work like we said it was going to work, then awful things happen. But of course, if we're experimental, um, we're kind of open to what happens, we have a hypothesis, but, um, it doesn't kind of matter if it doesn't do what we thought it would because we've still learned something from it. So what do organizations need to do in order to shift their culture to be more hypothesis-driven?
Heidi Waterhouse:
Right. So one of the things, like there's some really good hypothesis-driven development talks of ... A speaker from Betway has really great one in the UK. Um, hypothesis-driven development, you need to accept that the negative result is still a valid, useful result. So I think one of the things we need is to work with our business owners to create hypotheses that actually reflect what we need to happen. Uh, so frequently, we're like, "If I change this thing, I'm going to have a 40% increase in signups."
Um, framing it that way means that if you only get a 30% increase in signups, you failed. Well, except you have 30% more signups like, "That seems great." So I think it's better to say when you're formulating the hypothesis like changing this thing will change the signup level if at least, you know, N percent is an increase, then we will switch over to it, otherwise, the cost of the change is too high. And so writing the negative case, as well as the positive case allows you to understand that you've now positively affirmed that it's cheaper to stay doing it the way you are.
Helen Beal:
So great to inspect and adapt and treat everything as a learning opportunity. So your final question for today's talk is around top tips. So what is the one thing that you hope people learned from this talk? What's the key takeaway for you?
Heidi Waterhouse:
I think the one thing that I hope people take away is that when we make something smaller, it's less dangerous and it's easier to be kind to ourselves and others if it doesn't work. If we make it too big, it's too hard to swallow.
Helen Beal:
And if we can't be compassionate to ourselves, how are we ever going to be compassionate to other people? So it all starts here with- with oneself.
Heidi Waterhouse:
Mm-hmm (affirmative).
Helen Beal:
Um, so I think we're ready to see, uh, your final slide. Um, and is there anything else you want to share with the audience at this stage?
Heidi Waterhouse:
Uh, so I do work for LaunchDarkly. We do feature management as a service, we make it easier for you to break your deployment up into smaller chunks, and to do it with less risk. And I hope that you will go do some investigation on your own on psychological safety. I hope that you go buy and read, uh, a copy of "Accelerate." Um, and I hope that today is the day that you feel a little bit safer taking a chance.
Helen Beal:
That's right behind me. It's like one of those Bibles in our industry coming off the shelf. (laughs). Great, thanks so much Heidi, this was the InfoQ webinar Safe and Sensible Deployment and Launch with Reduced Risks with feature management experts LaunchDarkly. Of course, if you visit the LaunchDarkly website, you can grab yourself a demo. So what are you waiting for? I'm Helen Beal, your moderator today, and I'd like to thank you all for listening to our amazing speaker Heidi Waterhouse, and a huge thank you to her also for sharing your knowledge and expertise with- with us all. Thank you very much Heidi.
Heidi Waterhouse:
Thanks so much Helen.
Helen Beal:
Thank you. Goodbye everyone.
Catch up with more LaunchDarkly team talks by checking out our full list of upcoming and previous presentations.








