





One of the most important considerations when designing a system is its capacity to handle failures. This is particularly true of today's increasingly popular distributed systems. However, when it comes to designing for failure, one hurdle is ensuring its testability. Failure paths lacking in automated tests are a major risk factor because they can harbor bugs and require extensive manual quality assurance. Furthermore, distributed systems frequently fail in ways which are unlikely to arise in a controlled manner. With the application of feature flags, it is possible to trigger a variety of failure modes and ensure that all code paths are covered by automated testing.
At LaunchDarkly, we recently completed a project to shore up the durability and resilience of our event processing pipeline, which is responsible for processing events emitted by our clients. Over the course of this project, we made several major architectural changes. One of these was to isolate our data exporting functionality into a separate service. This service reads events off of an internal Event Queue and routes them to configured customer destinations.
In order to guarantee more reliable delivery of events, we wanted to make sure we didn't drop events the first time we failed to send them. Send failures could occur for a variety of reasons—including service failures or misconfigured settings on the customer's end—and some of these issues could take a substantial amount of time to resolve.
Therefore, we needed a resilient retry mechanism that could withstand long-running errors. We chose SQS for this purpose. The idea was that failed events could be sent to an SQS queue and then received from it for processing at a later time. With SQS, we are able to set a delay on event delivery, which allows us to back off our retries until an error is resolved.
Architecturally, the complete data export path looks as follows:
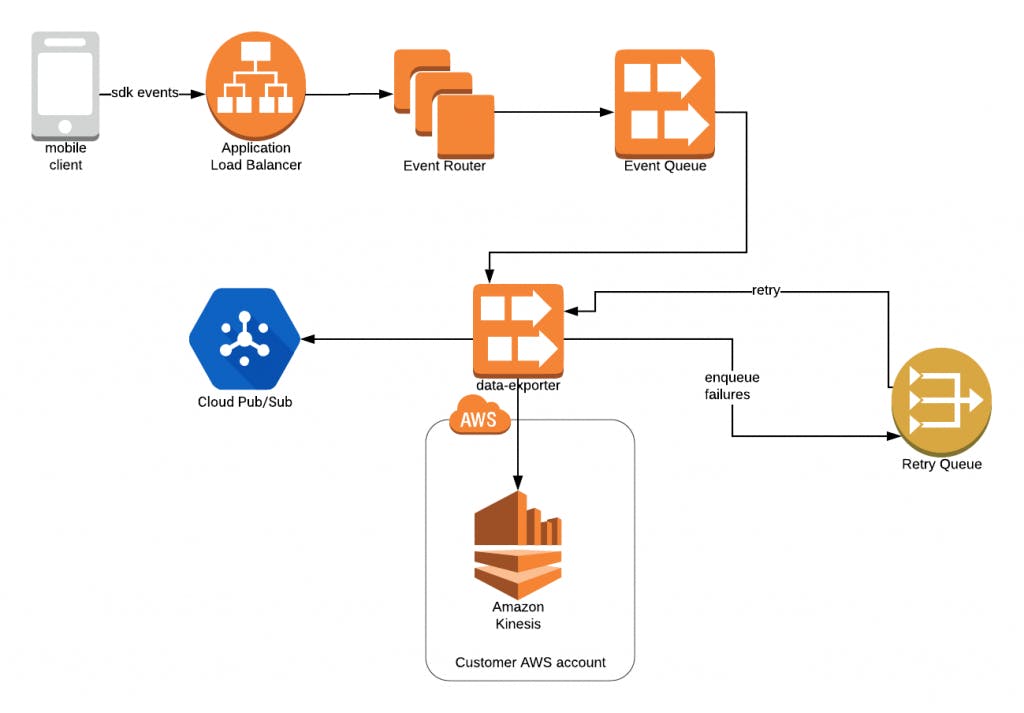
This makes for a fairly complicated sequence in the case of failed event exports. In order to verify the correctness of the complete sequence, we need to be able to verify that an event can:
- Be successfully sent from the Event Router to the Data Exporter via the Event Queue
- Fail to be exported to its destination and thus trigger a retry
- Be sent successfully to the SQS Retry Queue with the appropriate delay, and
- Receive the event from the Event Queue and successfully send it to a configured destination upon retry
The most obvious way to test this is manually. One would set up a data export destination and deliberately misconfigure it such that attempts to export events would fail (for example, by pointing it to a Kinesis stream that does not exist). The human tester would then correct this destination and verify that any requests which occurred during the broken state timeframe eventually come through the stream.
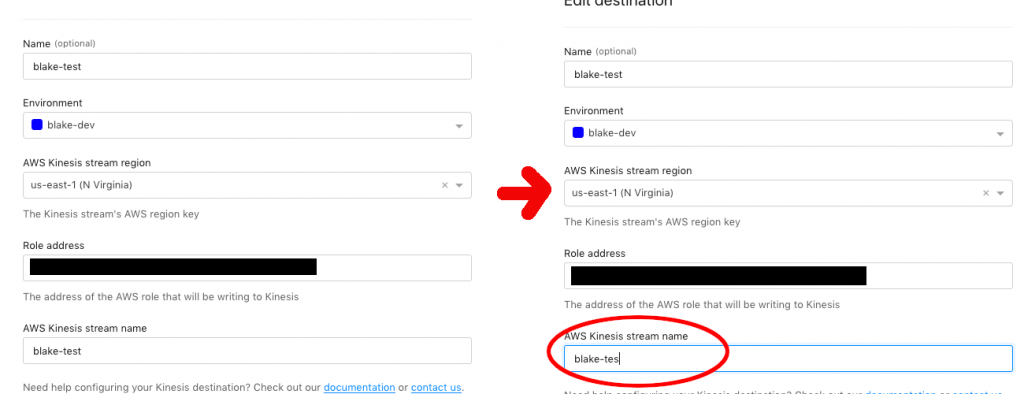
This is not a tenable testing practice in the long term as it is labor-intensive, and verifying events this way is much more error-prone than automated testing. It would be much better if we could automatically induce some data export attempts to fail, thereby triggering a retry, and verify that the consumer still gets the expected events.
We recently rolled out a service, creatively named “data-export-tester”, which simulates a LaunchDarkly SDK by sending a series of requests to the Event Router and awaiting the receipt of the event on a configured Kinesis stream. This fulfilled most of the requirements of the aforementioned integration testing. What remained was to find a way to retry some events sent by the data-export-tester without requiring any manual intervention.
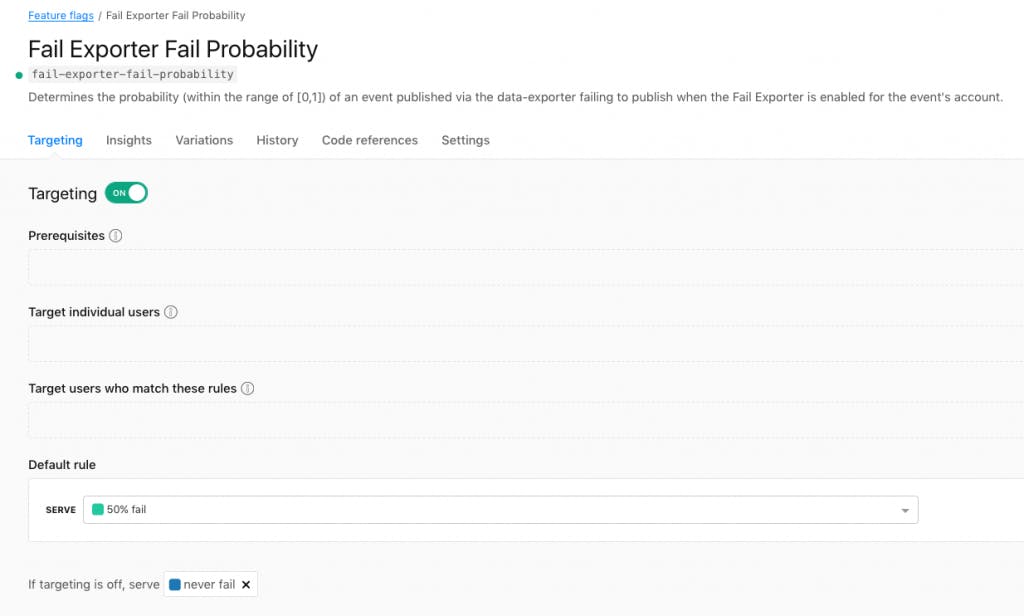
We arrived at a solution for this problem by feature flagging the way we export events. This means that based on the value of a feature flag, we can either export events as usual or force exporting events to fail and retry.
We defined a feature flag which fails some percentage of the attempts based on a specified value.
In our application code, we evaluate the flag using the Go SDK, which allows us to conditionally fail to send events.
failProbability, err:= ldClient.Float64Variation(failProbabilityFlag, user, 1.0)
if err !=nil {logger.Error.Printf("failExporter.PublishDestination:
failed to load flag %s",failProbabilityFlag)}
if cmp := random.Float64();
failProbability > cmp {
// Pretend that all events failed to send and return them for retry
return events, nil} // Publish destinationCopied!
The ability to specify failure probability allows us to fail some percentage of events without overexercising the retry logic and neglecting the primary happy path logic. As configured, events which have already been retried are always sent using the default rule, but one could imagine extending this pattern to probabilistically fail successive retries or to fail in other ways (for example, to timeout upon sending to a destination).
This gives us a complete and flexible end-to-end method of testing a crucial error path of our code. The solution is extensible to an array of other failure modes.
The only requirements to build additional failure modes for a given system are:
- Implement an error handling strategy
- Decide how this strategy could be triggered
- Create a feature flag to simulate the failure for select traffic
You can see how feature flagging provides a powerful way to test failure scenarios of services. By writing applications in such a way that expected failures can be induced, service owners can have confidence that error handling logic is working correctly, even when ordinary requests are not surfacing the required errors. The ability to target specific users with feature flags means that test requests can verify error handling in a production environment, and the ability to toggle the flags to reduce error rate or turn off error-triggering entirely grants more safety should these requests begin to negatively impact the service's health.
Like what you read?
Get a demo