LaunchDarkly vs. Optimizely
LaunchDarkly gives teams end‑to‑end control over software releases — from feature flagging to experimentation to automated rollbacks — in one unified platform. Optimizely focuses heavily on experimentation and digital experience optimization, but lacks depth, flexibility, and automation in feature delivery, governance, and runtime control.
Key differences

42T+ daily flag evals, sub-200ms latency, 99.99% uptime for enterprise customers
Processes only billions of events daily with 5-10 min freshness
Guarded Releases with auto rollback from metric signals
No metric-triggered auto-rollback; teams rely on manual rollback practices
Runtime control over AI configs and model prompts
No purpose-built, runtime AI config/prompt management (no public docs support)
Multi-context targeting across device, env, and user types
Targets via user attributes and supports flag dependencies; does not offer LD's multi-context model
35+ SDKs with strong mobile, edge, and typed flag support
Fewer SDKs and edge options than LD; typed values supported via flag variables
42T+ daily flag evals, sub-200ms latency, 99.99% uptime for enterprise customers
Guarded Releases with auto rollback from metric signals
Runtime control over AI configs and model prompts
Multi-context targeting across device, env, and user types
35+ SDKs with strong mobile, edge, and typed flag support
Processes only billions of events daily with 5-10 min freshness
No metric-triggered auto-rollback; teams rely on manual rollback practices
No purpose-built, runtime AI config/prompt management (no public docs support)
Targets via user attributes and supports flag dependencies; does not offer LD's multi-context model
Fewer SDKs and edge options than LD; typed values supported via flag variables
Built for product velocity.
Trusted by data-driven teams.
LaunchDarkly powers high-velocity teams with feature flags, experimentation, and AI config control — all in one secure, scalable platform.

Real-time flags, 42T+ daily evals, <200 ms latency, zero cold starts
VS Optimizely
No public scale metrics or decision-latency guarantees; notes 5–10 min results freshness for experiments

35+ SDKs spanning mobile, edge, backend, and IoT
VS Optimizely
Offers core SDKs (web, mobile, server, edge) but with less breadth than LaunchDarkly

Runtime AI configs to test prompts and models without redeploying.
VS Optimizely
No support for runtime or model-aware experimentation

Predictable pricing with experimentation built in
VS Optimizely
Pricing often unpredictable; experimentation sold separately

Supports multi-context targeting
VS Optimizely
Targets by attributes but no documented multi-context or chained flag model

Guarded rollouts with automatic rollback
VS Optimizely
Manual rollbacks only — no metric-driven auto-rollback
Ship, test, and automate — in one platform.
LaunchDarkly collapses flagging, testing, and measurement into a single workflow, so teams can ship faster and recover instantly.
Runtime AI prompt testing
No support for GenAI use cases
Flag chaining and multi-level targeting
No support for prerequisite flags or nested logic
Full audit trails, policies, and approvals
Basic RBAC only; change approvals require paid plan
Environment diffing + change tracking
No native diffing across environments
Runtime AI prompt testing
Flag chaining and multi-level targeting
Full audit trails, policies, and approvals
Environment diffing + change tracking
No support for GenAI use cases
No support for prerequisite flags or nested logic
Basic RBAC only; change approvals require paid plan
No native diffing across environments
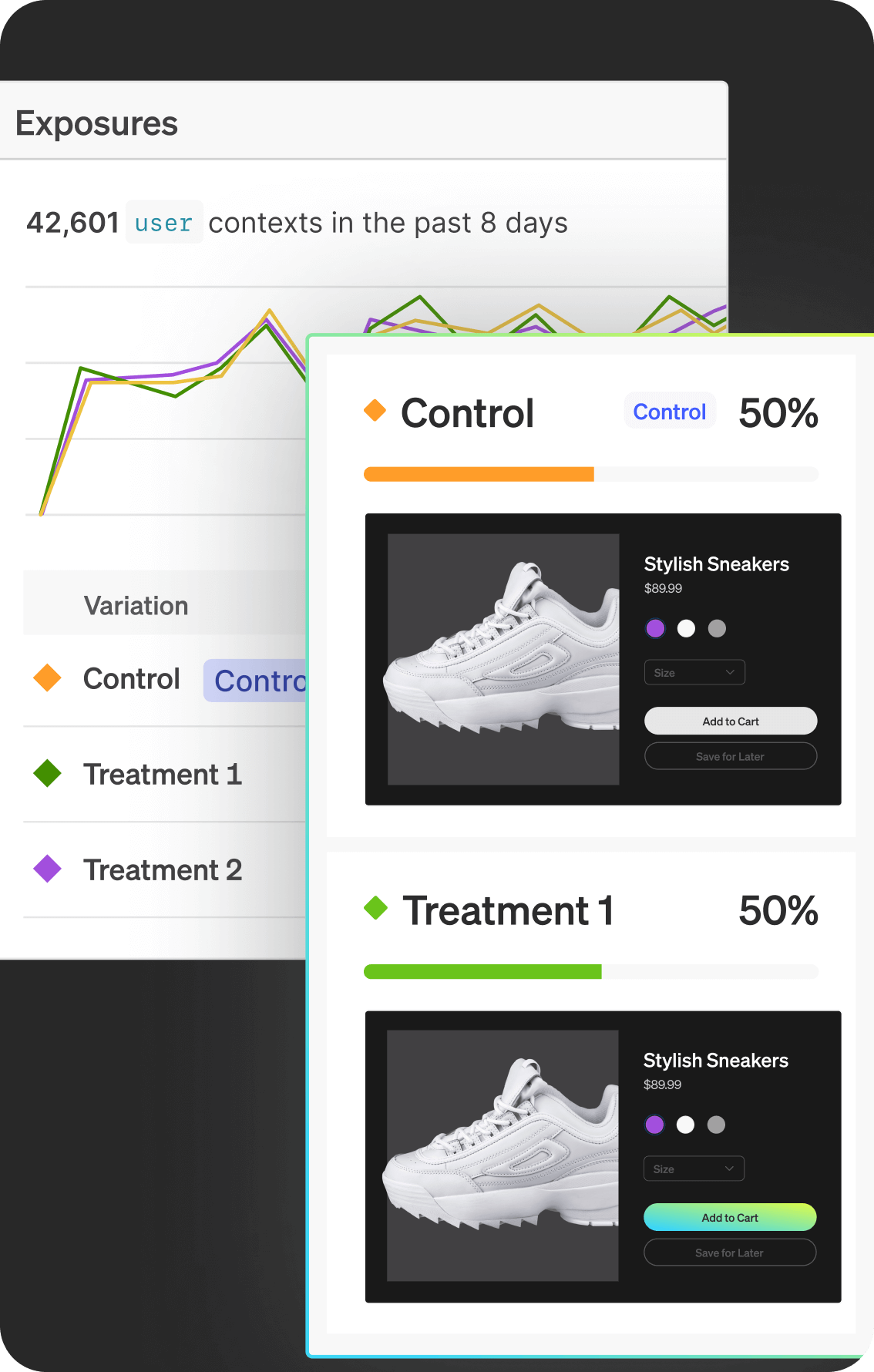
Context-aware targeting with full release control.
Whether you're targeting a flag to users in QA, running AI experiments in prod, or rolling out features to mobile-only audiences — LaunchDarkly lets you target anything and control everything.
Multi-context targeting: device, user, team, plan, tenant
VS Optimizely
Only audience targeting and rulesets via a single context model; no multi-context targeting or chained flag logic.
Flags + experiments unified in one flow
VS Optimizely
Split across separate modules; disconnected UX
Allows rollback triggers based on observability / metric signals
VS Optimizely
No built-in observability-triggered rollback integrations
Supports dynamic, auto-updating segments
VS Optimizely
Segments are static; no dynamic updates documented
Why choose LaunchDarkly over Optimizely?
Release safety at enterprise scale
Auto rollbacks from Sentry, Datadog, or New Relic. 99.99% uptime SLA for enterprise customers and zero cold starts. Proven at 42T+ daily evaluations.
Built-in GenAI configuration testing
Target and tune model prompts or AI agents in real time. No redeploys needed for runtime experimentation.
True multi-context targeting
Target by any dimension: env, plan, device, version, region. Supports chained flags and flag prerequisites for gated delivery.
Governed workflows and audit controls
Custom policies, approval gates, and full change history. Environment diffing and rollback-ready UIs.
Massive SDK coverage + edge ready
35+ SDKs across client, server, mobile, and edge. Typed flag support and CI/CD automation.
* This comparison data is based on research conducted in November 2025.
Trusted by the world's most innovative teams
Join thousands of teams, including 25% of the Fortune 500, who use LaunchDarkly to de-risk delivery, run experiments at scale, and delight users faster.

Join innovative companies like these
"LaunchDarkly helped to democratize the experimentation practice and bring together data, product, and engineering teams working together around the same project."
David Tieba
Head of Product Analytics

"LaunchDarkly has given us much more flexibility than our previous tools for feature flagging and A/B testing. We’re able to experiment more effectively and make better data-driven decisions.”
Rema Morgan-Aluko
SVP Technology

"The ability to target experiments and analyze results efficiently has been a game-changer for us. It’s enabled us to run more tests and gain actionable insights much faster. ”
Riley Duncan
Sr. Data Analytst
"By connecting to Snowflake, we can move more quickly when new models are released, which means we can say yes to more ideas. We can take real risks on these things.”
Jon Noronha
Co-founder and Chief Product Officer

"LaunchDarkly helps us safely roll out and experiment with AI and product features without requiring engineering deploys for every variation.”
Vincent L.
Data Scientist, Information Technology and Services Company
"We can test new features with specific users, run A/B tests, and turn off features instantly if something breaks. This means fewer production issues, faster feedback, and more control over our releases.”
Jwalit Shah
Software Engineer






Build with confidence, experiment with ease.
