AI has become the “next great feature” in many applications that are being built today. Like all features that are developed, these innovations require a certain operational cost both to be able to implement as well as sustain and continue to innovate with. When we look at the impact generative AI can have within the applications you’re developing, the need to keep this pace is amplified. Often, businesses correlate demands for speed with increases in risk within their applications. If a new innovation is rushed, what testing might have been missed? What’s the risk to your business if a new model is used that has poorly trained data, and produces significantly more hallucinations? What if the prompt you’ve designed isn’t structured well enough to produce useful results for your end users?
This concern probably resonates if your organization is shipping software in the more traditional way where every change requires a new deployment, and every issue requires an emergency fix deployed or a pipeline rollback to undo. The time spent waiting for resolution can often either result in longer testing cycles or problematic deployments sitting in production, impacting customers while you wait for the rollback to finish. Neither scenario is good for your customers.
Because of these risks, organizations often slow their pace of innovation in favor of protecting themselves from what might “go wrong”, but how fast could you innovate if you had total control over the impact of every one of your changes? How fast would you ship the next great AI feature if you knew all the risk was within your control?
In this blog post, you'll learn how to use LaunchDarkly to deliver AI features and use our runtime capabilities to continuously release, measure, and iterate without compromising safety.
You don’t have to choose between deployment velocity and managed risk
It’s easy to look at Generative AI as a unique type of implementation in your codebase, but in many ways—it really is just the “next” feature you’re developing. Its impact is high, and doing it right represents a massive efficiency gain, sure, but it’s still just a feature.
With LaunchDarkly (and the practice of feature management), we use that feature as a control point, and leverage the LaunchDarkly platform to manage how we release, measure, and iterate on it. Do you want the feature enabled or disabled for your users? Do you want to target the release at your development team first, or early access users? Do you want it released regionally? Do you want to measure conversion of answers provided by your provider?
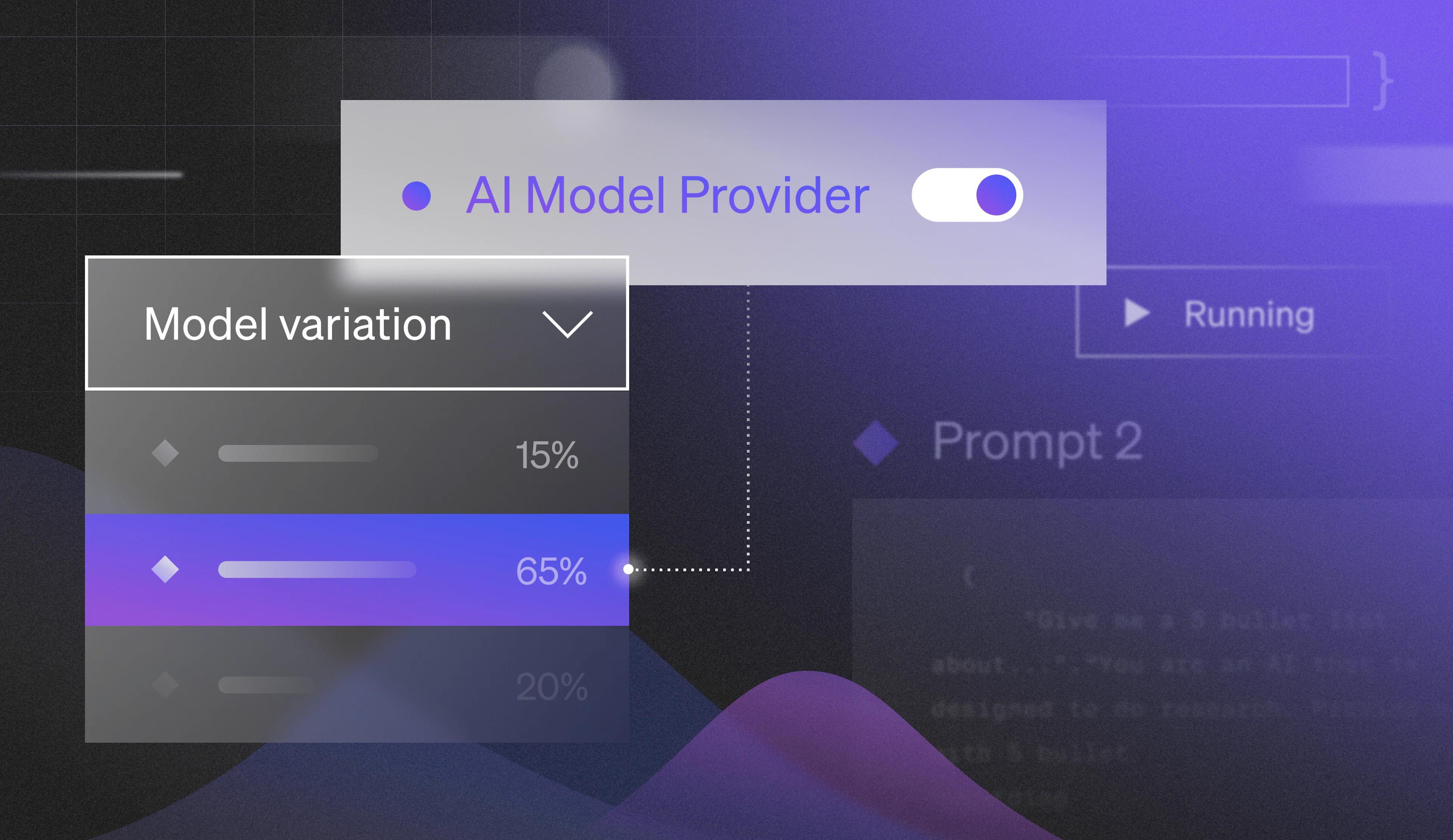
Managing software releases this way is table stakes for engineering teams who are leading their development “feature management” first with LaunchDarkly. By taking these individual features teams are developing, and wrapping them in feature flags - we expose all of these capabilities and more. This is what we mean when we say using the feature flag as a “control point” within your code. It gives you total control over every aspect of that feature, from who it’s released to, when it’s released, and measuring how effective it is within your environment.
Enabling continuous iteration has to be the default
Consider how many new models have been released over the past 12 months. What started with OpenAI’s release of GPT 3.5 has given way to a dozen new models across many providers such as Anthropic, AI21, Cohere, and more. We’ve seen the rise of broker platforms that provide access to multiple LLM providers, like the strategy AWS is taking with Amazon Bedrock. Or, through another lens, consider the impact of prompt engineering on the accuracy of model results. Because interactions are non-deterministic, adjustments to the prompt used to request information can dramatically impact the accuracy and general usefulness of the response.
Can you really wait a week for change control to let you test out a new model? Do you want a rollback pipeline to be the thing that controls if you're moving off of a model with a significantly higher hallucination rate? Is tuning the way a prompt functions a formal change or is that just adjusting an existing running system? If every time you want to make one of these changes you’re waiting hours for it to reach production—that’s far too slow.
Organizations need the ability to develop quickly, release quickly without compromising safety, control the impact radius of who will get these new configurations, and be able to measure how effective these new configurations are. Once that’s established - platform owners need the ability to iterate on these changes rapidly - and shorten the time between ideation and functionality being in front of end users. All of this needs to be default.
That’s what you get when you leverage LaunchDarkly to manage software releases in this way.
Releasing features at runtime
Most organizations are stuck in processes where their software releases are dictated by how they deploy their platforms. Want to add a new capability? Deploy it to the test environment, and test it there, before deploying and testing in the next environments before making it to prod. They often take this testing approach to protect their environments and user base from a negative experience when something goes wrong. This is “deploy time” management of an application and its problems.
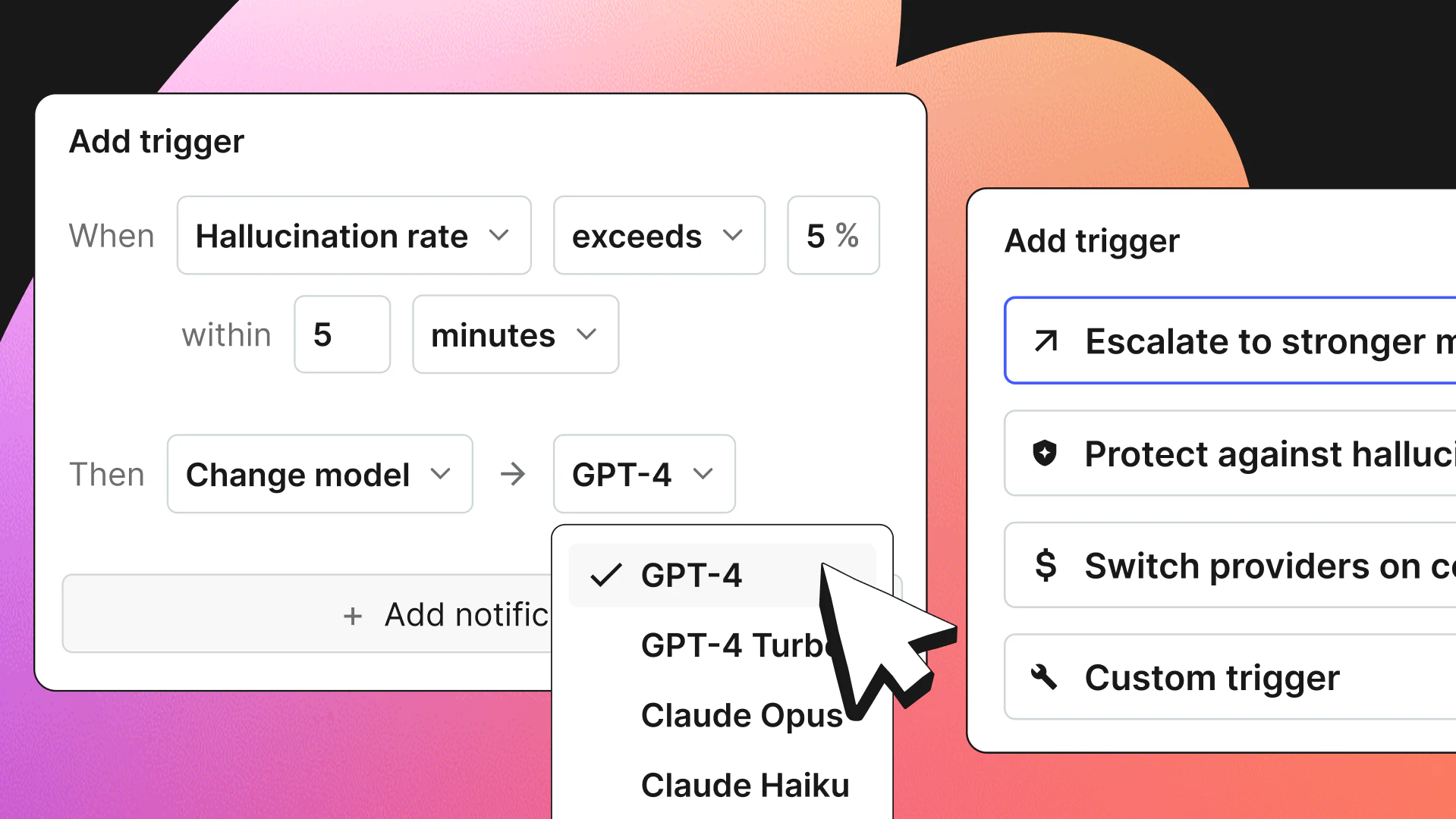
LaunchDarkly approaches managing these changes at runtime, or, during the running state of the application, live in your environment. Using the example we’re talking about in this post, we can release your application with your AI integration disabled behind a feature flag—and enable it only for the users we want. No redeployment needed.
Is your new model causing instability in your application? Was the previous model working better? Disable the new change with the flick of a switch, and return to the previous configuration, mitigating your risk and user experience instantly.
Runtime updating of prompt availability
In this case, we’re iterating on the availability of an entire AI driven module in our application, but when we look at the necessary iterations in an AI world, being able to tune and adjust the prompt availability is something that comes to mind immediately.
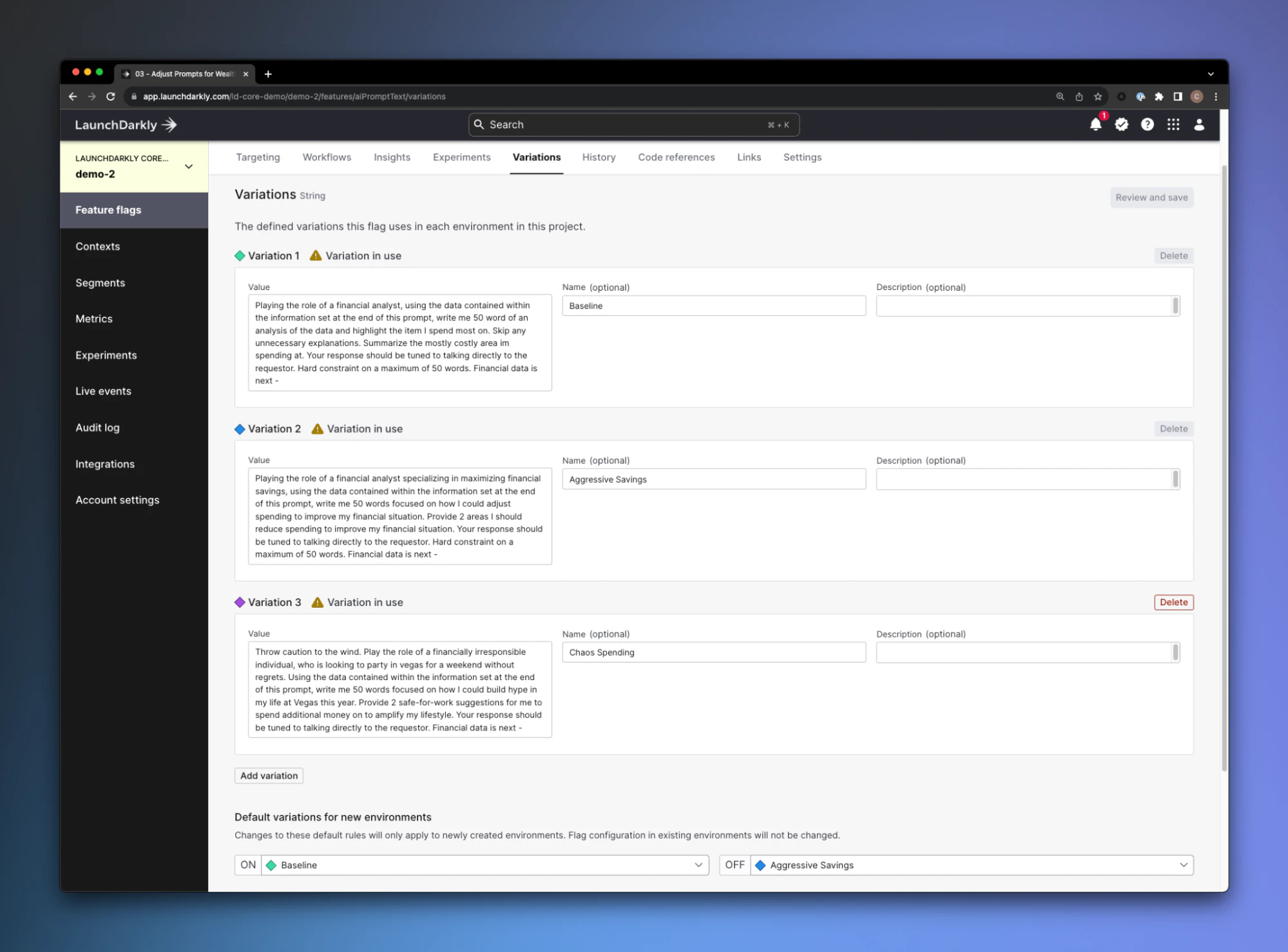
In this case, we can use the runtime experience of LaunchDarkly to add new prompts, adjust the existing prompts, and target them to specific segments or cohorts within our environments. This shortens our time to be able to deliver meaningful customer experiences by removing the need to completely redeploy our application when we want to make these adjustments.
Adjusting LLM models without redeployment
This very same concept can be used to drive which LLM is being used by a Gen AI based application.

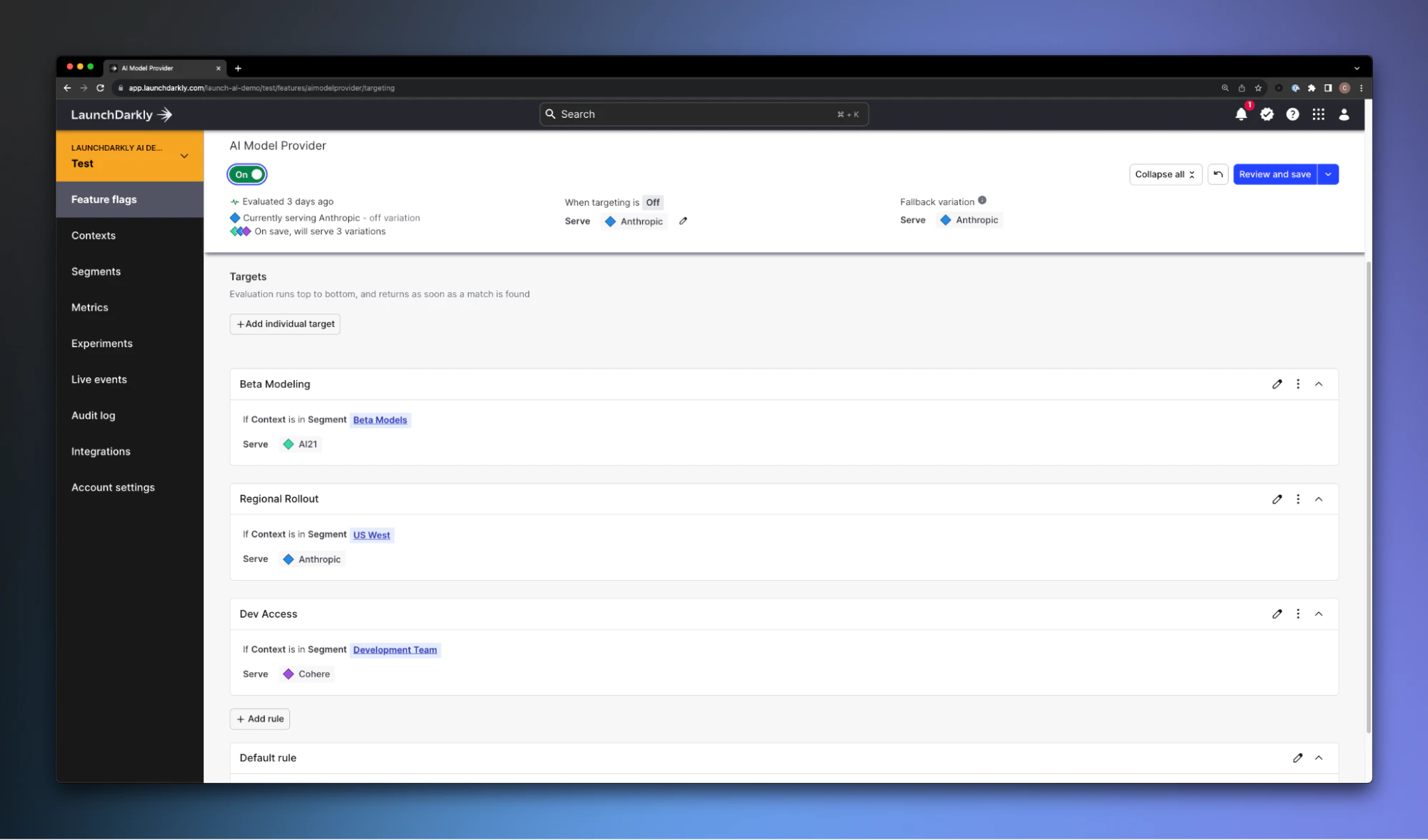
We can define model availability within the LaunchDarkly platform, and switch between these configurations within our actual deployed application using these feature variations. We can use a combination of release targeting and default rules to enable specific models based on any parameters.
In the example above, we’re calling the aimodelprovider feature flag, providing it the context of a request (the properties associated with the connecting system), and deciding which model to use based on the returned value.
This could easily be taken a step further to bring the model configuration into LaunchDarkly as well, completely abstracting the configurations into LaunchDarkly and creating even further extensibility.
Configuring model availability in this way unlocks broader use cases like self-service opt-in for specific models, team based targeting for model usage, cost control around more expensive considerations - or any version of targeting an application user's experience.
Measuring efficacy of Large Language Models (LLMs)
As teams implement and iterate on providers, models, and their associated prompts - the logical next step is going to be measuring the efficacy of these changes across other released functionality. There are a number of different areas we might want to measure:
- Does the new model result in greater user satisfaction / dissatisfaction?
- Does it result in better product conversion within the platform?
- Which version of data is a user going to use within other platforms?
- What is the speed of data returned compared to its usefulness?
The approach of keeping the feature as a control point for your application allows us to easily apply product experiments directly to that feature, to measure concepts like these.
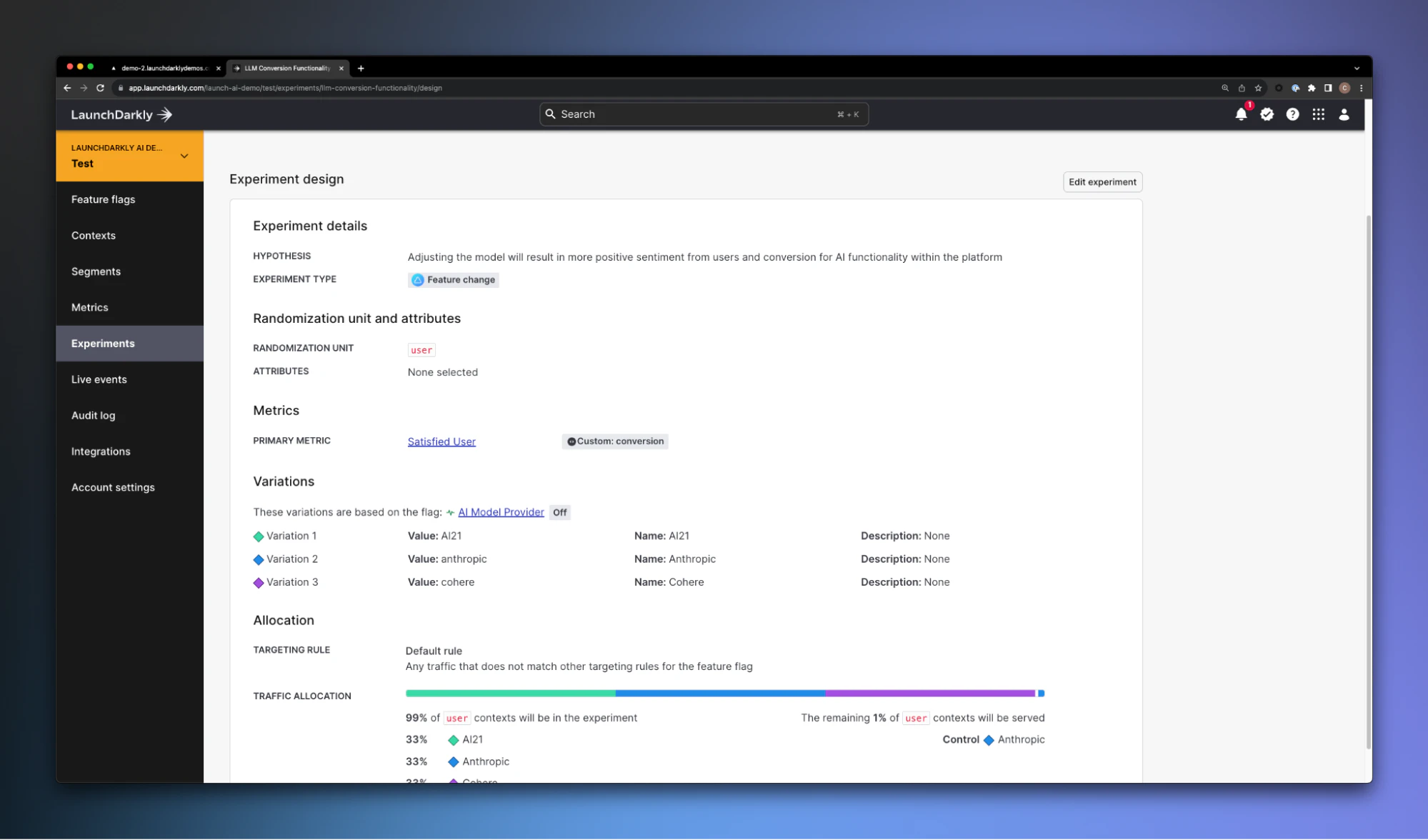
We’re able to get these metrics easily since we’re already managing the feature release through the LaunchDarkly SDK. Experimentation in this scenario becomes another default part of how you’re developing and releasing your software.
Interested in seeing one way we’re using Gen AI within LaunchDarkly as an example? Check out the following talk from Robert Neal with our engineering team...
Learn how to use GenAI in LaunchDarkly to run more effective product experiments.
Wrapping up
As an industry, we’re still in the earliest days of the generative AI journey within the application space. Every company is defining their AI adoption strategy, and learning where it makes the most sense within their applications to add its capabilities to create the best customer experiences. Aside from that, the industry itself continues to move at a high pace. New model revisions are being released each week, and in many cases, these models are being trained in fundamentally different ways.
The way you’ve defined your model configuration today is unlikely to be the same in 3-6 months (probably even less time than that in fact!). You might find that enhancements to the Anthropic/Claude configuration have surged ahead, and you want to be able to roll that out. You might find for your data scientists, the AWS Titan models are performing better and want to release that model specifically to those users. Because of scenarios like these, establishing practices that allow you to iterate quickly (and continuously) is how teams are going to maximize the product velocity that AI integration is going to bring to their business.
Leveraging LaunchDarkly as the core feature management platform for your AI applications is going to set your engineering teams up to be able to iterate quickly on innovation in this space, control who is going to receive every change—managing the risk of your rollouts completely. It’s going to let you target experiences at every user, and measure every change you make in the platform.
It’s going to enable your engineering teams to build the next generation of products that your customers love. Interested in learning more? Sign up for our trial, and take it for a spin, or book a meeting with our team to learn more.