





I often get questions about how to best implement a set of targeting rules around experiments, especially when there are multiple ways to achieve similar functionality.
In this article, you’ll learn how the flag rules work in experiments and how you can use it to speed up your experimentation program to capitalize on findings.
Flag targeting rules: Targeting the audience for your flag
One of the most powerful features of LaunchDarkly are targeting rules. Leveraging targeting rules on your feature flags is how you can ensure that only certain customers can see and use a feature, allowing for hyper-specific targeting of specific individuals, or by creating custom rules or leveraging segments.
A flag rule gives you the ability to decide which flag state you want to serve to specific customers. In this simple example, I’m releasing a new feature only to Gold tier users of my website. A rule like this would do the trick:
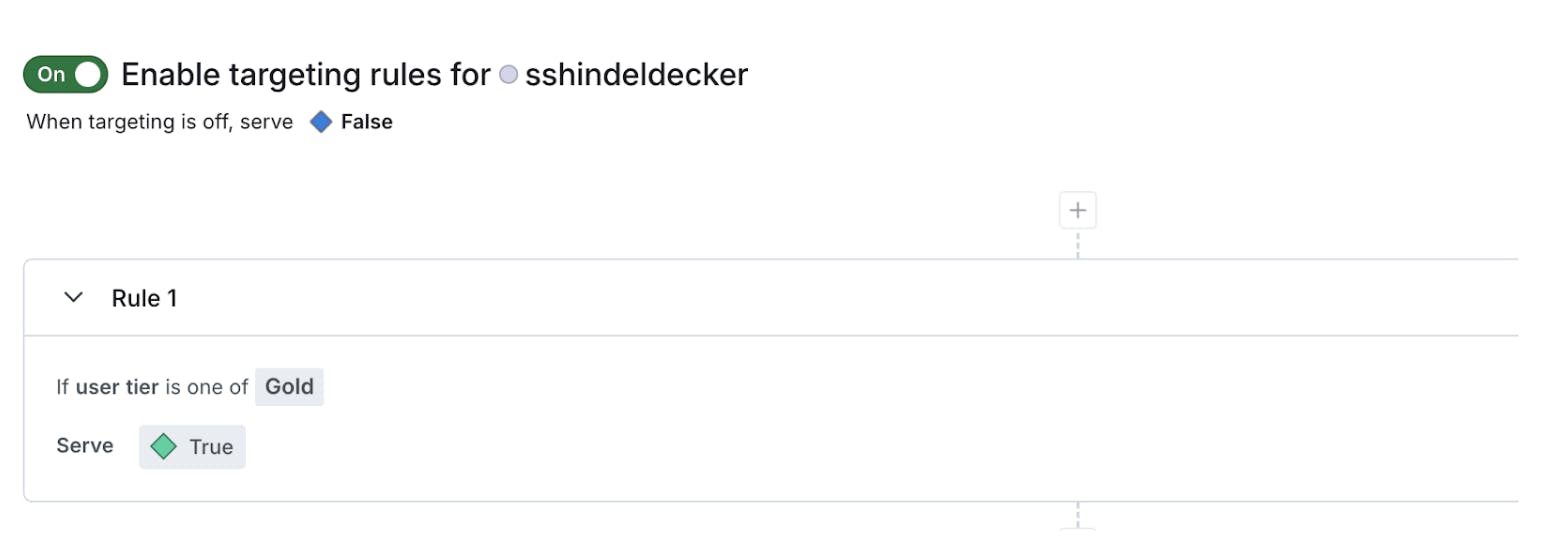
Here is an example of a flag rule targeting
Experiment audience rules: Who is included in our experiment?
When setting up an experiment in LaunchDarkly, after we’ve attached our metrics and our feature flag, we’re given the opportunity to choose our audience. Who do we want to include in our experiment, and who should be left out?
There are many reasons why you may choose to target the audience of your experiment:
Technology reasons — Let’s say the iOS version of our app is ready now and we want to start learning immediately, rather than waiting until the Android version is ready as well.
Product reasons — For example, updating a feature to improve the experience for Platinum tier customers specifically.
Risk reasons — Maybe wWe want to start this test small, in a select representative number of states, to limit the potential impact of the feature if it does not work as expected.
To target your experiment to a specific audience,leverage a flag targeting rule from your feature flag when you’re defining the audience. When you select this targeting rule, it will take the place of the default rule, meaning that instead of serving the default, it will randomly serve a variant based on the probabilities you set when you configure your experiment.
In the example below, I’ve selected 100% of my audience who meet my rule criteria to be included in my experiment. You can choose to select less than 100% of this audience and there are many reasons you may choose to do so, for now however we’ll keep it simple with 100% of the audience.
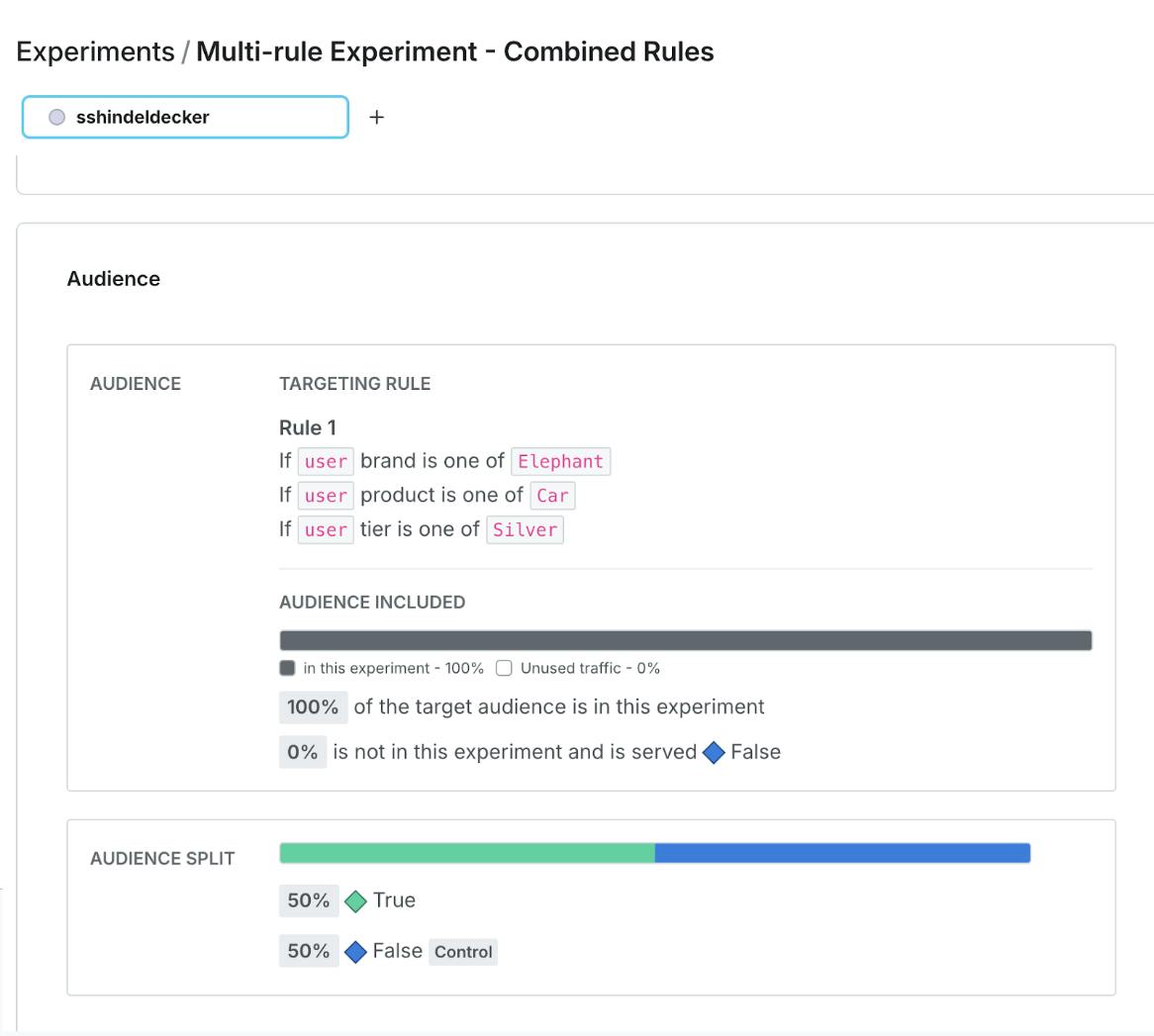
This rule is selected as an experiment is set up, and will determine the experiment audience
Working with multiple flag rules
LaunchDarkly evaluates flag rules in order, which means that the order matters. The top rule will evaluate first, any users that meet the condition in the first rule will get served the variation that was set for that rule, those that do not are evaluated for the second rule, and so forth, ending on the default rule. The default rule is there to evaluate for anyone who has not met the criteria in the rules. An experiment can pull in a different rule to overwrite the default rule.
In the example above, the experiment rule had 3 different conditions brought together with an AND statement. Those three rules could have been defined separately as different rules, and there are reasons why I might want to pull each rule out on its own.
I could set this rule up as a single targeting rule:

But I also could leverage the order of the flag evaluations to achieve the same thing:
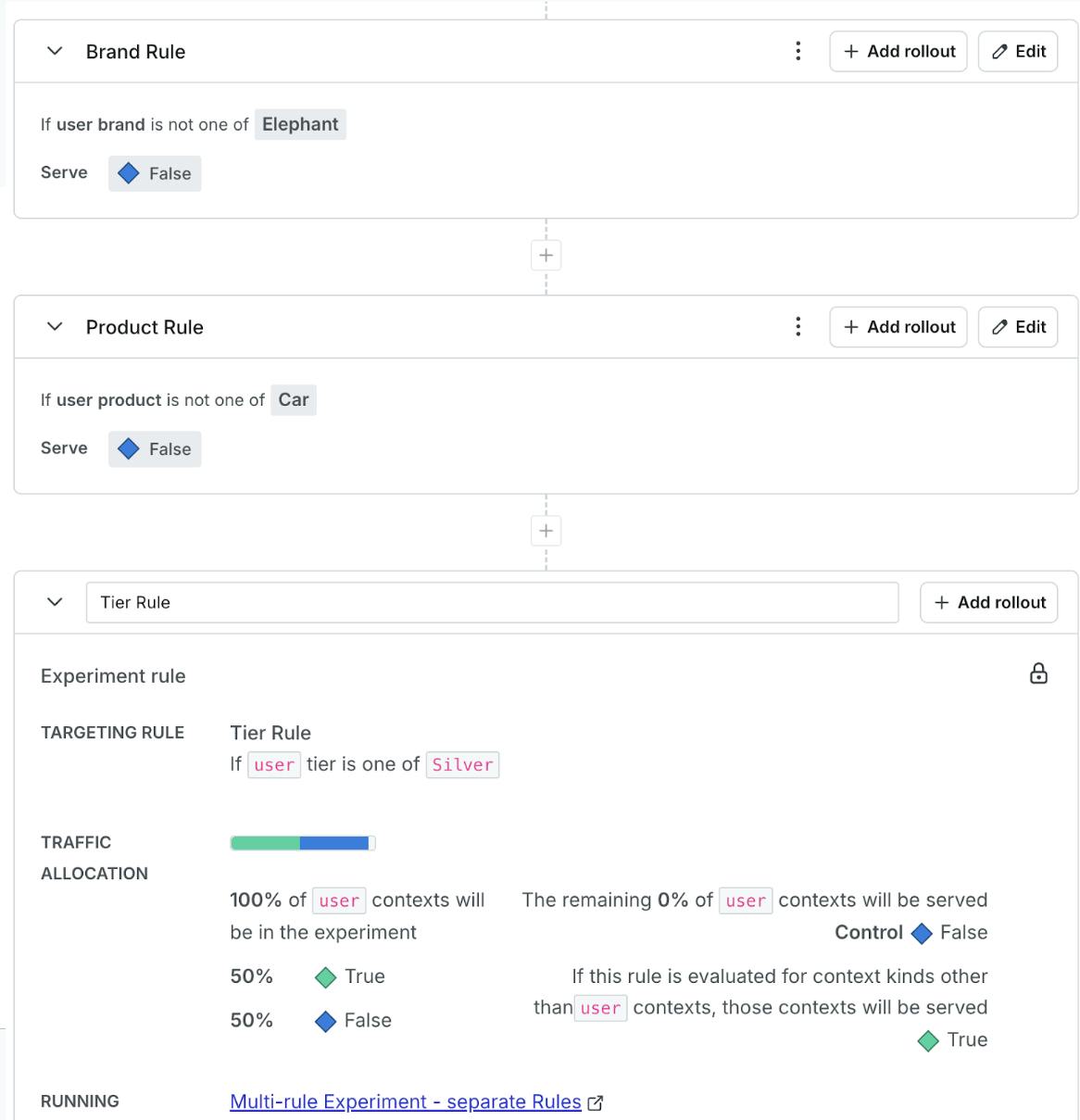
Setting up a flag with 3 separate targeting rules
Is there a difference between these two methods? Do they achieve the same results? Are there reasons to choose one over the other?
As long as the rules are set up correctly (see below)* both of these approaches can achieve a similar customer experience, ensuring the flag values are appropriately applied to the correct target audience. Meaning, if you get your rules right, the flag rules behave the same in either method, and will return the correct variation.
They do behave slightly differently, and there are reasons you might want to use those differences to your advantage.
The difference is in the data
To demonstrate the difference, I’ve set up two experiments, one with the conditions split, one with them combined into a single rule.
Now I can run some example data through this. I often use Python to quickly simulate some data with the Faker package.
import ldclient
from ldclient import Context
from ldclient.config import Config
from faker import Faker
from uuid import uuid4
from faker.providers import DynamicProvider
sdk_key = 'sdk-xxxxxxxxxxxxxxxxxxxxxx'
config = Config(sdk_key = sdk_key, http=ldclient.config.HTTPConfig(connect_timeout=5))
ldclient.set_config(config)
client = ldclient.get()
brands_provider = DynamicProvider(
provider_name="brand",
elements=["Admiral", "Diamond", "Elephant", "Toothbrush", "Biscuit"],
)
product_provider = DynamicProvider(
provider_name="product",
elements=["Car", "Home", "Motorcycle", "Renters"],
)
price_provider = DynamicProvider(
provider_name="example_in_cart_price",
elements=[93.84, 143.73, 101.35, 86.02, 46.91, 125.62, 77.85, 99.68, 73.99, 148.79],
)
tier_provider = DynamicProvider(
provider_name="tier",
elements=["Bronze", "Silver", "Gold"],
)
fake = Faker()
fake.add_provider(brands_provider)
fake.add_provider(price_provider)
fake.add_provider(product_provider)
fake.add_provider(tier_provider)
num_records = 300
i = 0
while i <= num_records :
fakeUserId2 = fake.uuid4()
userBrand = fake.brand()
userPrice = fake.example_in_cart_price()
userProduct = fake.product()
userTier = fake.tier()
user_context = Context.builder(fakeUserId2).kind("user").set("brand", userBrand).set("product", userProduct).set("tier", userTier).build()
print (user_context)
variation_detail2 = client.variation_detail("test-flag", user_context, 'false')
print (variation_detail2)
variation_detail3 = client.variation_detail("test-flag-2", user_context, 'false')
print (variation_detail3)
i = i+1Here is an example of a customer who meets the criteria to be in our experiment.
{
"key":"dacb86af-12c8-44be-bfe0-176965214759",
"Kind":"user",
"brand":"Elephant",
"product":"Car",
"tier":"Silver"
}
Multi-rule Experiment - Separate Rules
(value=True, variation_index=0, reason={'kind': 'RULE_MATCH', 'ruleIndex': 2, 'ruleId': 'cfb3264d-5385-4144-887f-f0e2bda33e79', 'inExperiment': True})Multi-rule Experiment - Combined Rules
(value=True, variation_index=0, reason={'kind': 'RULE_MATCH', 'ruleIndex': 0, 'ruleId': '2477614a-db24-4d4e-b066-9ab1cb09af36', 'inExperiment': True})What should be noticed here is that the value and variation (what variation the user is being shown) are the same. If you are just using the variation value returned, the customer will be shown the same variation, and the behavior will be the same. A quick note, this user met my criteria, so the data that LaunchDarkly returns adds a field called “inExperiment” and marks it as True for records who are included in the experiment audience.
Here is a customer that does not meet our criteria, and you will notice a slightly larger difference:
{
"key":"66f99739-6755-4d43-95ec-be92e40ca5ce",
"kind":"user",
"brand":"Elephant",
"product":"Home",
"tier":"Silver"
}Again, here is the data that is returned from evaluating the same user against the two different configurations.
Multi-rule Experiment - Separate Rules
(value=False, variation_index=1, reason={'kind': 'RULE_MATCH', 'ruleIndex': 1, 'ruleId': '7a8b3b9c-f4ab-40e8-8ce5-e06a9e9fbdcc'})Multi-rule Experiment - Combined Rules
(value=False, variation_index=1, reason={'kind': 'FALLTHROUGH'})In this case, we see it is a different reason returned from the flag evaluation when the user context does not meet the experiment criteria.
If you are exporting data from LaunchDarkly to perform further analysis, this difference is one to note as you develop methods to analyze your data more fully.
A note on rule clarity
One thing that should be reinforced is that Targeting Rules and Experiment Rules are asking slightly different questions.
A targeting rule is saying: “For users that match this criteria, serve this specific variation. Otherwise, move them to the next rule.”
An experiment rule is saying: “Users that meet this criteria are eligible to be included in the experiment.” They still might not be in the experiment, depending on the percentage you selected to be included. This means that there is a section of users who are served “False” from this rule because they are in the experiment and randomly selected the False variation, and there is another section of users that are not in the experiment and are served the False variation.
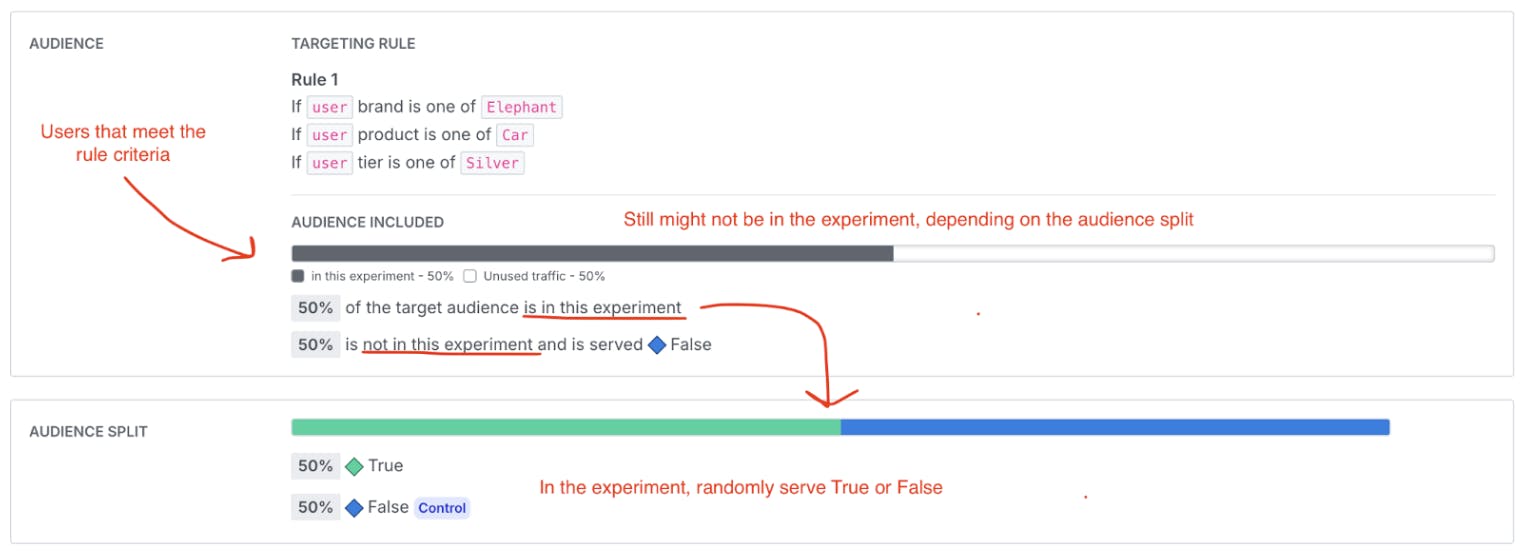
I’m almost embarrassed how often I find myself tangled in Not In vs. In statements. This article itself had a few false starts as I had to remember that for my experiment with separate targeting rules, I needed to write the first two targeting rules as exclusionary.
I do not want Brands other than “Elephant” in my test → Serve them false else
I do not want Products other than “Car” in my test → Serve them false else
I DO want Tier “Silver” only included in my test → Randomize else serve them false
When writing my targeting rule that I intend to use in my experiment, I needed to remember to flip that last condition, because I want to serve anyone that falls through the previous two rules to be INCLUDED in my experiment.
In my brain, it is much cleaner for me to think about the population I want included in my experiment, so writing a single rule with AND statements was just easier for me to do.
I want only customers who have the Brand “Elephant” AND the Product “Car” AND the tier “Silver” as a part of my experiment, everyone else is out of the experiment and served control.
If your brain works like mine, it may be easier to include your experiment targeting criteria into a single rule to make it easier to remember what is what!
Best Practice: Target experiment subgroups to capture margins
There is another really powerful way to use the targeting rule order to capture as much of your experimental gains as you can, as quickly as you can. For this, I need to leverage both user attributes attached to my context, an experiment with some data, and the flag targeting rules.
Because flag targeting rules fire before the experiment rules do, you can take quick advantage of experiment learnings if you find them by adding a new targeting rule to capture winning margins. Here’s an example:
Note: I’m using the same attributes here, but this is a new experiment
In this example, I’m not adding any targeting rules to start. I want to learn what is working, and I’m going to do some analysis by Product, Brand, and Tier.
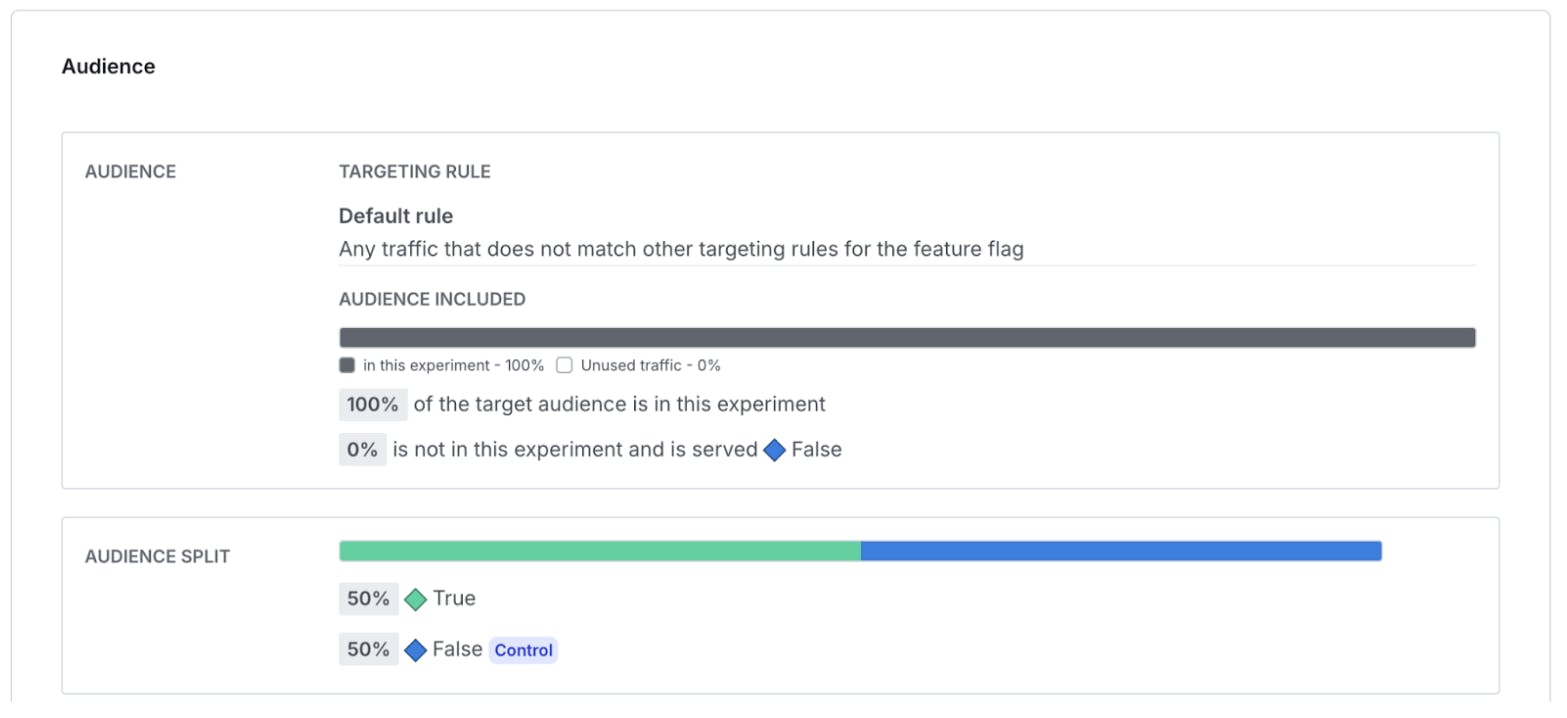
No targeting rules to start with on this experiment
Now I need to run this experiment and generate some data.
Through the magic of writing. Done
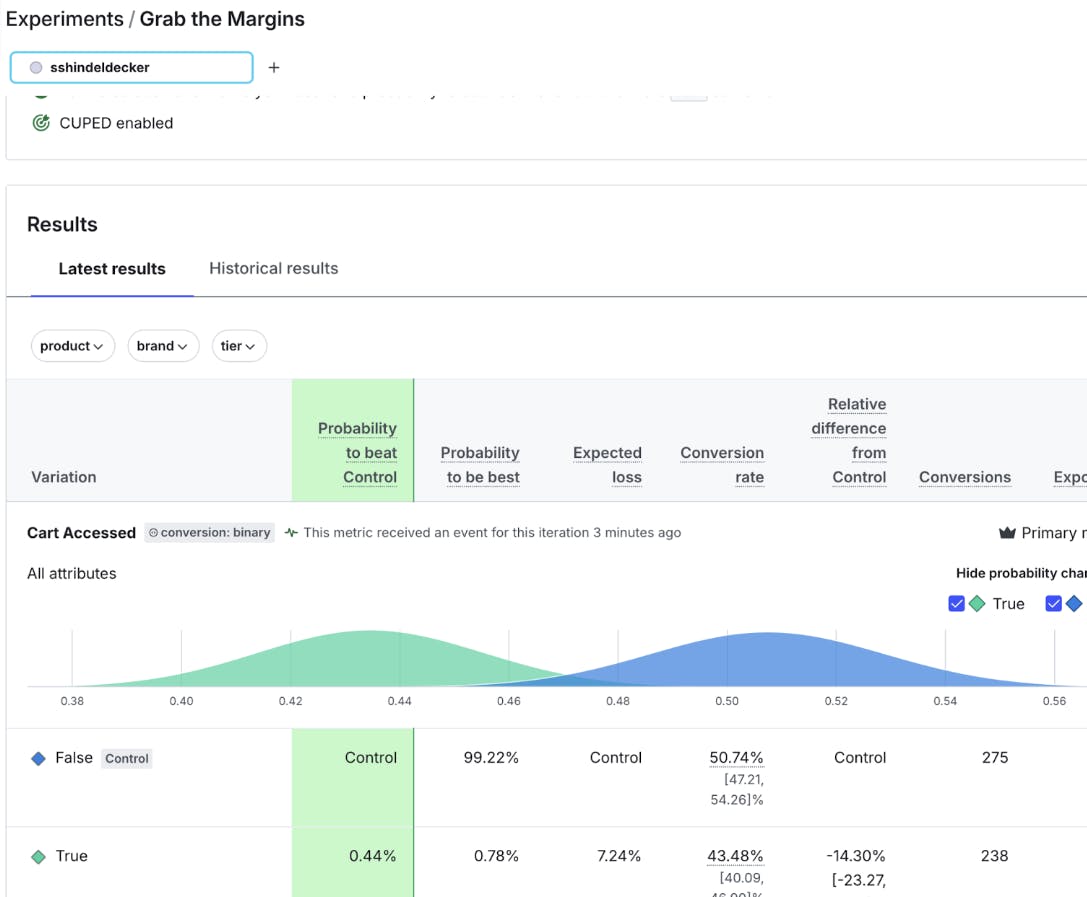
A sample experiment with simulated data showing Control beating Treatment soundly
Above you’ll see my experiment results for this example experiment. In it, Control is pretty confidently outperforming treatment. I think that we have learned in this case that for our overall population, our Control variant is currently winning. We might be able to make a call that Control wins and roll back our feature.
But what about digging into the data a little more, maybe we’ll find a population where there is a different finding? I can do this by using the attribute filtering function in the LaunchDarkly Results screen.
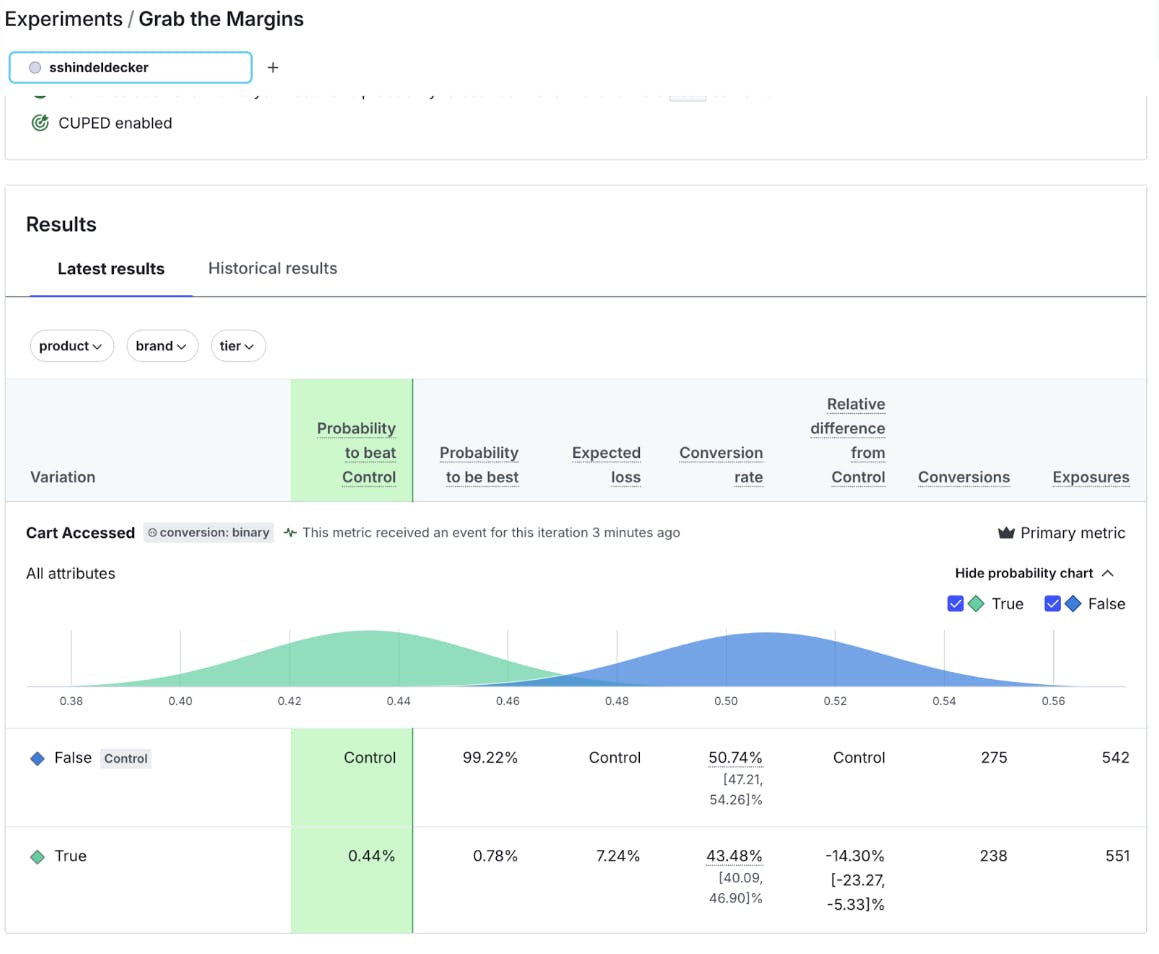
Since I simulated the data, I know where to find it. Look at how the customers who are our Home product customers respond to our treatment:
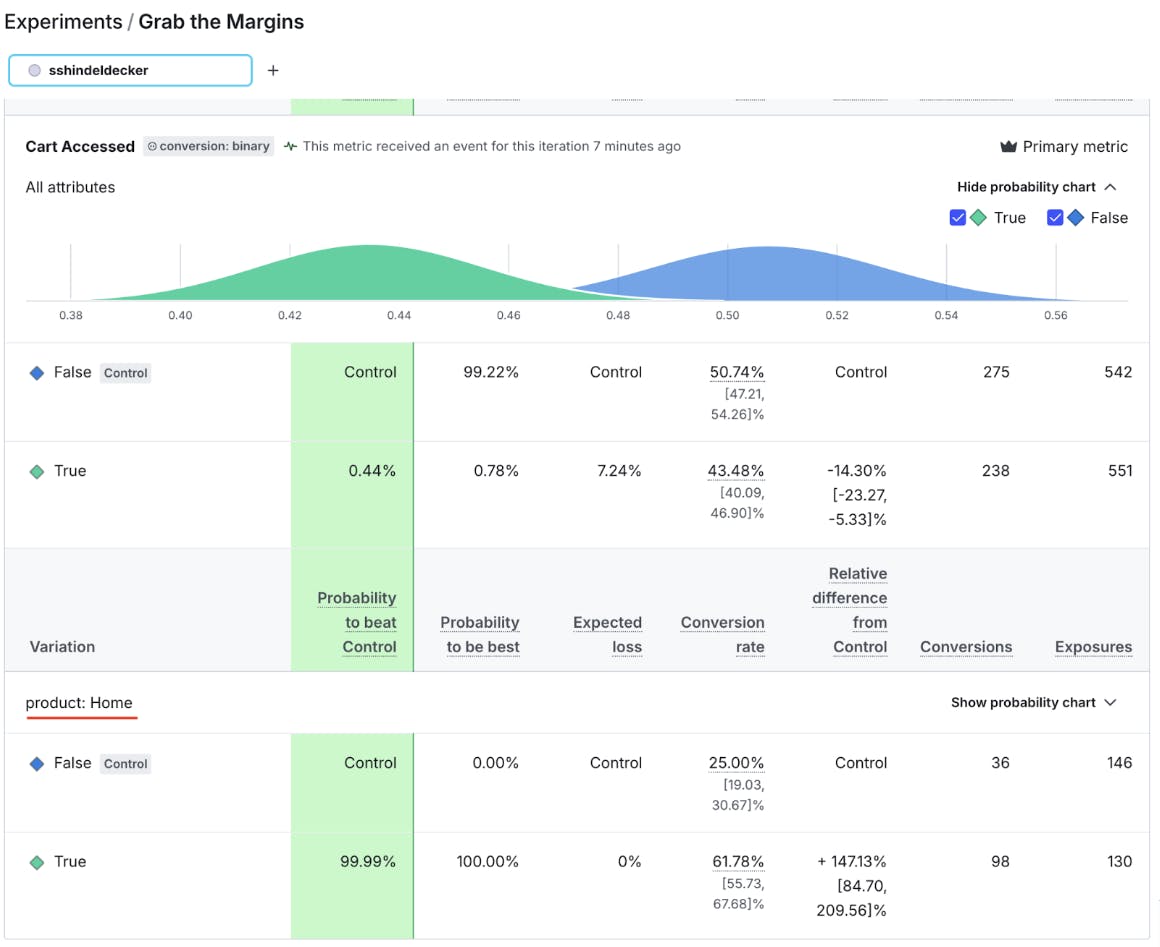
Our Home product really loves our new feature don’t they? That means that while we’re experimenting, every time our Home product customers land on Control, it’s a less-than-ideal outcome. If only we could serve True to our Home product customers, and maybe keep the rest of folks running through an experiment to see if we can find any other margins!
That’s where Targeting Rules can help. Remember, they fire before the experiment. That means that I can, very easily, add a new targeting rule to my flag:
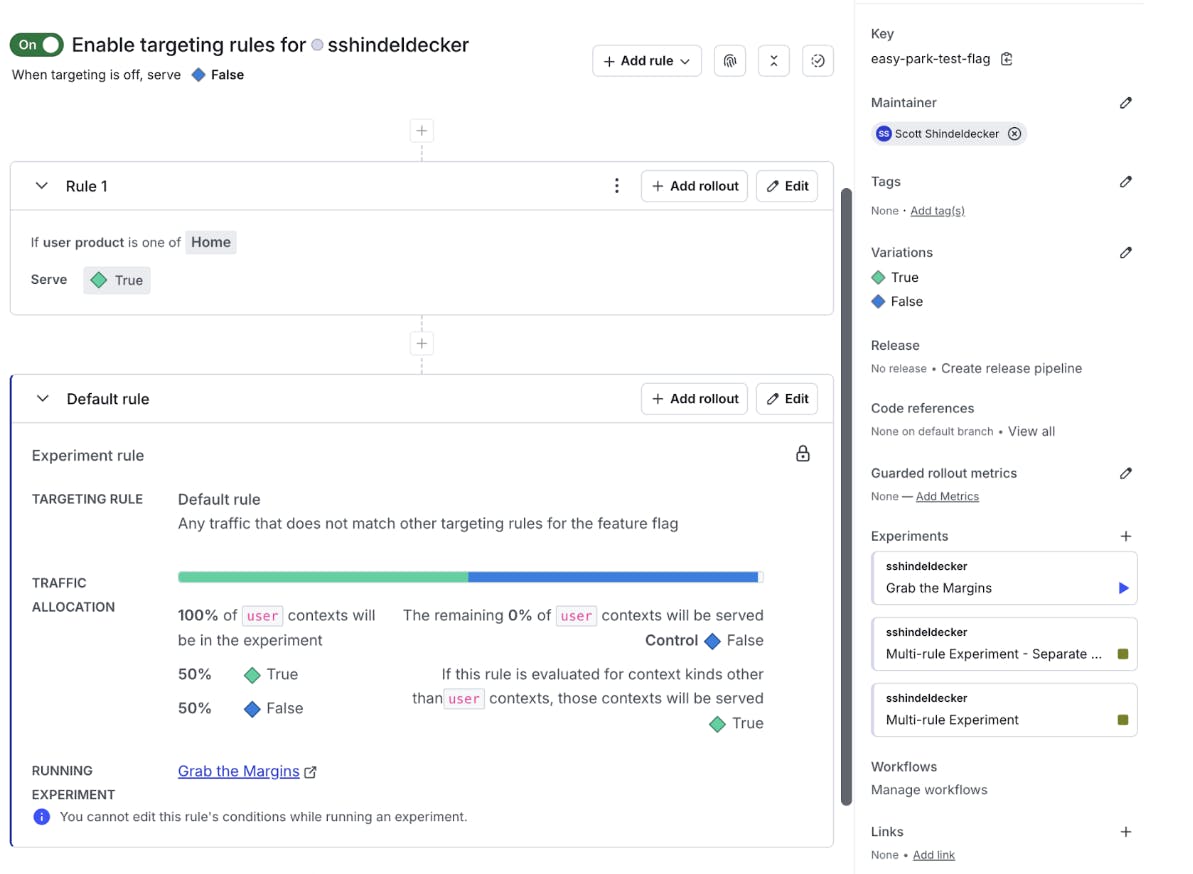
And now we’re taking advantage of all of those sweet gains that our Home product customers are bringing in, and we’re going to keep learning from our experiment with everyone else!
This can be a way to super charge your learnings, and get as much out of your experimentation program as you can.
Like what you read?
Get a demo