





This is a guest blog post from our customer Knock, which provides a set of simple APIs and a dashboard for teams to introduce thoughtful notifications into their products, without having to build and maintain a notification system in-house.
At Knock, we use LaunchDarkly to power feature flags. Feature flags are powerful because they enable us to control, at run time, the behavior of different parts of the system. Most of the time, this means controlling access to features on our frontend, or controlling the rollout of new features across our frontend and backend stacks. However, we recently adopted a circuit breaker pattern built around feature flags. This pattern helps our services be more reliable when things fail.
The problem
Like many applications, our infrastructure relies on queues to decouple various components. We have found that sometimes our Broadway consumers for AWS Kinesis fail in ways that do not gracefully recover when they crash. For example, each Kinesis shard has its own supervision tree managed by the Kinesis Broadway consumer. We found that if a shard experienced a crash-inducing error, the shard would not restart and the crash would not cascade up to the Broadway producer. While we have worked on contributing to this consumer library, we decided that it would be important to have runtime control over stopping and starting consumers to respond to such failures just in case.
Likewise, we value having many options for tuning our service at runtime so that we can always serve critical requests - even if that means temporarily degrading less critical parts of our application. Temporarily stopping queue consumption is one such strategy.
We knew that we needed a way, at runtime, to start and stop these queue consumers. Although we could have reached for other configuration management tools like Hashicorp Consul or AWS AppConfig, we already use LaunchDarkly at Knock to control the runtime behavior of our frontend and backend applications. LaunchDarkly feature flags seemed like a great way to control this starting and stopping process without adding new dependencies or complexity to our stack.
The solution
We built an Elixir supervisor called Circuit Breaker that takes inspiration from the typical circuit breaker pattern and applies it to supervision trees (but, to be clear, our circuit breaker is not the same thing as the typical circuit breaker pattern you may be used to.)
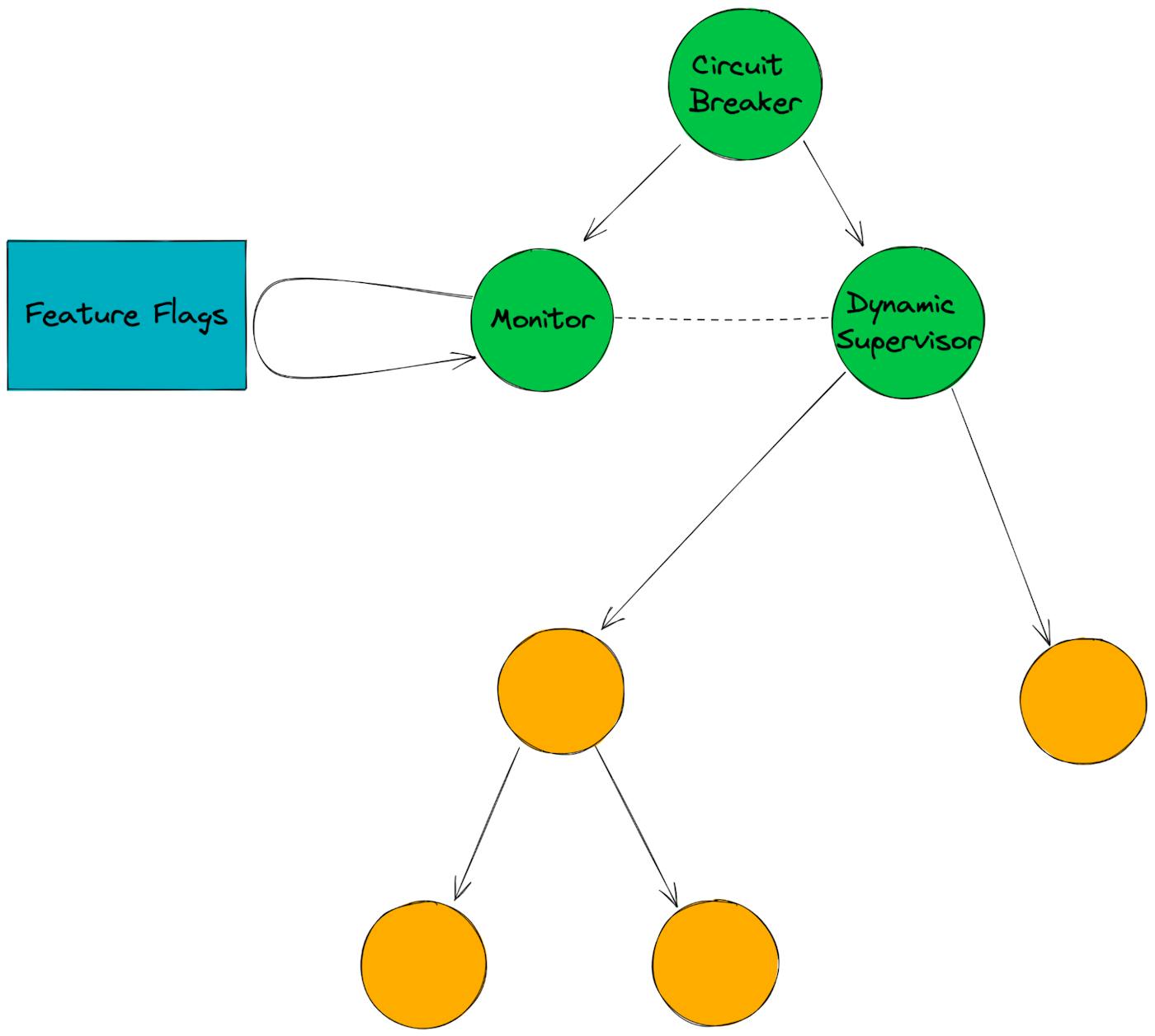
Our circuit breaker responds to two signals:
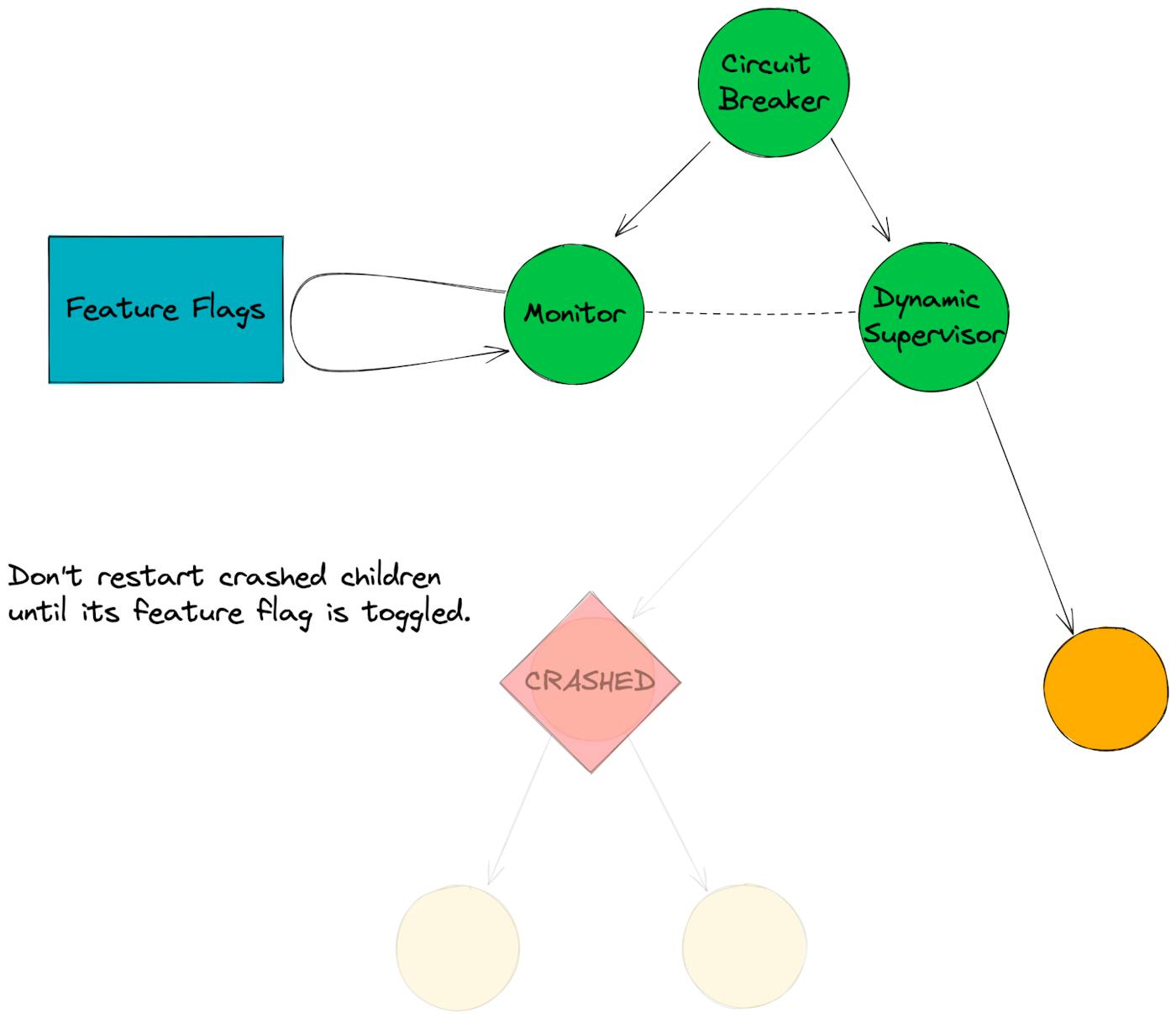
1. If a child process is crashing, let it crash, don’t bring it back up, and notify our team using our observability tools.
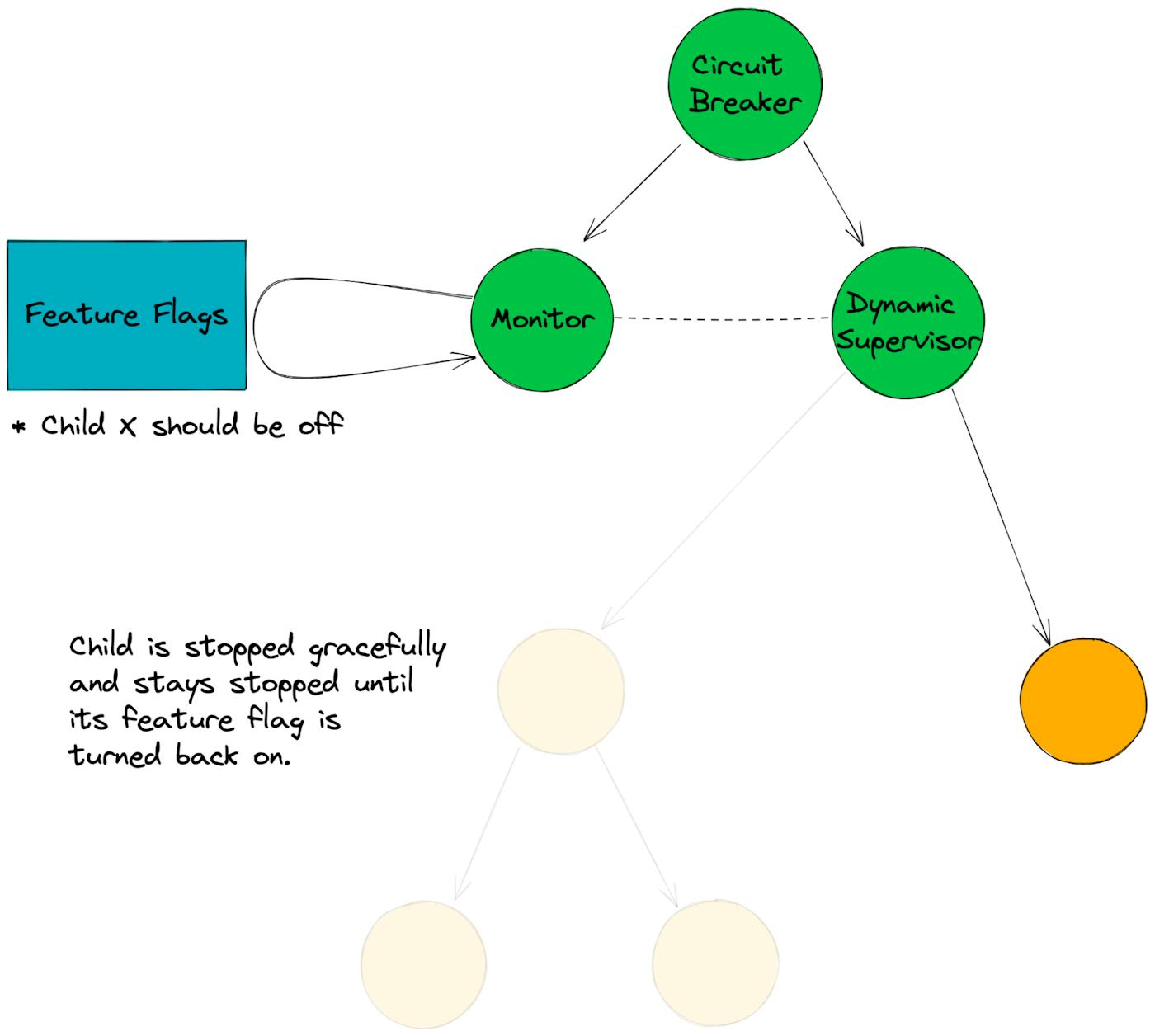
2. If a feature flag is toggled on or off, start or stop a corresponding child process accordingly.
Every second, the Circuit Breaker checks the current state of our feature flags and starts/stops the corresponding child processes.
- If a process has crashed and its flag is on, we don’t restore the process.
- If a process is on but its flag is off, we gracefully shut it down.
- If a process is off (but not crashed) and its flag is on, then we start it back up again.
This approach gives us a lot of flexibility in dealing with failures and extra load in our system. By turning off consumers strategically, we can intentionally degrade our service in order to maintain uptime on more critical parts of our infrastructure. Once traffic spikes have passed, we can resume consumption and fully restore service. Having options like these is part of a “defense in depth” strategy for scaling. Instead of relying 100% on queues, autoscaling, or the Elixir supervision tree, we can also intervene in the system at runtime without fiddling with lower levels of infrastructure (e.g. Kubernetes or environment variables).
Typically in an Elixir application, if a supervisor is crashing repeatedly, such crashes can eventually cascade up and cause the entire application to restart. By trapping the crashes within the circuit breaker, we have a way to ensure that such crashes cannot cascade up to the root of the application - and we have a way to start up the crashing supervisor again on the terms we want to work with.
How it works
- There is a top-level supervisor
CircuitBreakerthat we start in our application supervisor with a list of children to monitor. This list includes the subsequent child specs and the feature flag to watch for each child.
# How we start the Circuit Breaker, including the list of child specs
# and their corresponding feature flags to watch
defmodule MyApp.Application do
@moduledoc false
use Application
def start(_type, _args) do
children = [
# ...
{
CircuitBreaker,
children: [
%{
id: SomeService.Supervisor,
start: {SomeService.Supervisor, :start_link, [[]]},
restart: :temporary,
ld_key: "some-feature-flag-on-launch-darkly"
},
%{
id: AnotherService.Supervisor,
start: {AnotherService.Supervisor, :start_link, [[]]},
restart: :temporary,
ld_key: "a-different-feature-flag"
}
]
}
# ...
]
opts = [strategy: :one_for_one, name: MyApp.Supervisor]
Supervisor.start_link(children, opts)
end
enddefmodule CircuitBreaker do
@moduledoc """
Supervisor for starting/stopping/restarting supervisors using feature flags.
If a child completly shuts down, it remains shut down until the entire
application restarts, or the LaunchDarkly flag is cycled.
"""
use Supervisor
def start_link(init_arg) do
Supervisor.start_link(__MODULE__, init_arg, name: __MODULE__)
end
@impl true
def init(init_arg) do
monitored_children = Keyword.get(init_arg, :children, [])
children = [
{DynamicSupervisor, name: __MODULE__.DynamicSupervisor, strategy: :one_for_one},
{__MODULE__.Monitor, children: monitored_children}
]
Supervisor.init(children, strategy: :one_for_one)
end
def add_child(spec) do
GenServer.call(__MODULE__.Monitor, {:add_child, spec})
end
defdelegate pid_for_spec(spec), to: __MODULE__.Monitor
defdelegate spec_to_id(spec), to: __MODULE__.Monitor
end2. The CircuitBreaker supervisor has two children:
- A Dynamic Supervisor
CircuitBreaker.Monitor, which is given the list of child specs.
3. The monitor loops through the list of child specs and checks the feature flags for each of them. Based on that, it adds the child specs to the supervisor and monitors them, trapping exits.
4. If a process crashes, the Monitor tracks that signal and marks that child as crashed. We clear the crashed state when we see that the feature flag has been turned off.
5. If the Monitor sees a flag off but a child is running, it tells the dynamic supervisor to terminate the child process.
6. If the Monitor sees a flag as on, but the child is not running (and not crashed), then it starts the process under the dynamic supervisor.
A basic implementation (along with instructions for integration into your own projects) is available in this GitHub gist. Internally, our implementation includes support for Telemetry and additional logging & observability.
Monitoring Failures
We use the Elixir/Erlang Telemetry module extensively at Knock to monitor runtime performance. Each time the Monitor checks the flag status for each process, it reports how many child processes are running, how many are off, and how many are in a crashed state. As processes crash, it also emits log messages capturing the crash (without the crash cascading up to the parent supervisor). When we see increases in the crash metric or those log messages, we get a notification in Slack so that we can intervene as appropriate.
Future development
From here, there are a few improvements we can make to our implementation:
- We are still making improvements to our Kinesis consumer library so that shard-level failures are handled correctly without manually toggling feature flags. Even so, being able to manually control consumers at runtime gives us more options when dealing with incidents.
- Abstracting our dependency on LaunchDarkly so we can swap out different feature flag implementations.
- Release what we’ve built as open source. Today’s blog post is a step towards releasing a fully built, plug-and-play library. With some time and attention, this tool could be generalized so anyone could drop it into their project for controlling the starting/stopping of supervision trees at runtime.
Read more customer stories or discover more tips and tricks.
Like what you read?
Get a demo