





There are many different ways to run a business experiment, and many tools on the market (with more emerging each month). So what makes the LaunchDarkly experimentation tool stand out among others on the market?
Well, there are a few reasons that I love LaunchDarkly for experimentation, but one of the biggest is that it is so powerful. Over and over, when we work with customers, we find that all experiments come through engineering before they are released. Sure, there are tools that suggest a different approach, and I’ll go into some pitfalls of those tools in a bit. But first, let’s talk about experimentation as a method of release measurement.
Measure your releases
There are many different ways to define “business experimentation,” covering the gamut of testing and learning patterns used in modern companies to measure the true business impact of the changes we make.
When talking with business partners about the concept of experimentation, I encourage focusing on “measurement.” An experiment is a way to attribute a customer’s behavioral changes to the features we release to the market. In other words: when we release something to the market, we want to understand its impact; to measure it.
This concept resonates with business leaders because they’re already measuring (or attempting to measure) things that they release. In most cases, they do this by taking a before/after measurement and trying to correlate outcomes. Only rarely do we roll out something new with no interest in understanding its impact on our customers. There are things we absolutely must release, measurement notwithstanding. That said, I have heard a lot of features being called “table stakes” as a way of saying that they’ll be released no matter what. But most of those features were not–IMHO–table stakes.
LaunchDarkly has always invested in giving engineers the control plane for releasing software safely. Its feature flag capabilities allow the separation of deployment (when the code is live on the production server) and release (when customers interact with the code). Engineers have been using LaunchDarkly to release software using top-of-the-line targeting for over 10 years.
Since LaunchDarkly exists right in your control plane— enabling you to control which features a customer can interact with—it’s the perfect place to build experiments for the features you’re releasing.
With only a few simple steps, any feature released using a LaunchDarkly feature flag can be attached to an experiment that measures its impact. This means that any feature release can easily become an experiment! And when your experiment concludes, your product team simply ships the best variation, without extra code or deploys.
Experiments always go through engineering
Of course, there are tools in the marketplace that handle experimentation differently than LaunchDarkly.
Different tools push developers into different patterns to enable an experiment. Some tools give the illusion of being able to bypass the engineering process, letting you access a user’s browser and inject new code that changes the look and feel of a site without making changes to the underlying page code on the server.
These tools often have some sort of WYSIWYG editor that allows non-technical users to make simple modifications to a client-side web application (experiments that are more complicated often require coding). This means that the use of these tools can create a pattern wherein non-technical resources often write code that does not go through the standard development test and release process. In fact, in some cases, I’ve seen teams who are managing work on the server version of the site not communicating with the team working on the experiments.
You now have untested (or undertested) code being shown to live customers, which can have consequences bigger than just slow or clunky code.
I’ve seen instances where the marketing team rolled out an experiment that changed a feature that was also being changed by the engineering team—without either team realizing they were conflicting with the other. The server-side team’s code was not being executed because marketing had overwritten it!
Sure, good release documentation can help to prevent these situations, but these user-error circumstances can be very hard to diagnose.
This doesn’t even begin to address the multitude of homegrown experimentation products built by extremely smart teams who want to start running experiments. These tools can be great; I used to work with one myself! The issue here is usually an inability to scale. As more use cases arise, these very smart teams realize they’re spending all their time simply maintaining their tool rather than improving it to enable better experiments.
Now that we’ve run an experiment on injected javascript code, if we find a variation that works well and want to release it to all users… well, now we have to write an engineering story to implement the functionality correctly into the server code. The engineering story likely won’t look anything like what marketing did to make the test work. This almost always causes severe delays after you’ve identified a winning variation. The engineering team normally plans out their work for months ahead—and now this new feature needs to be prioritized, coded, tested, and released.
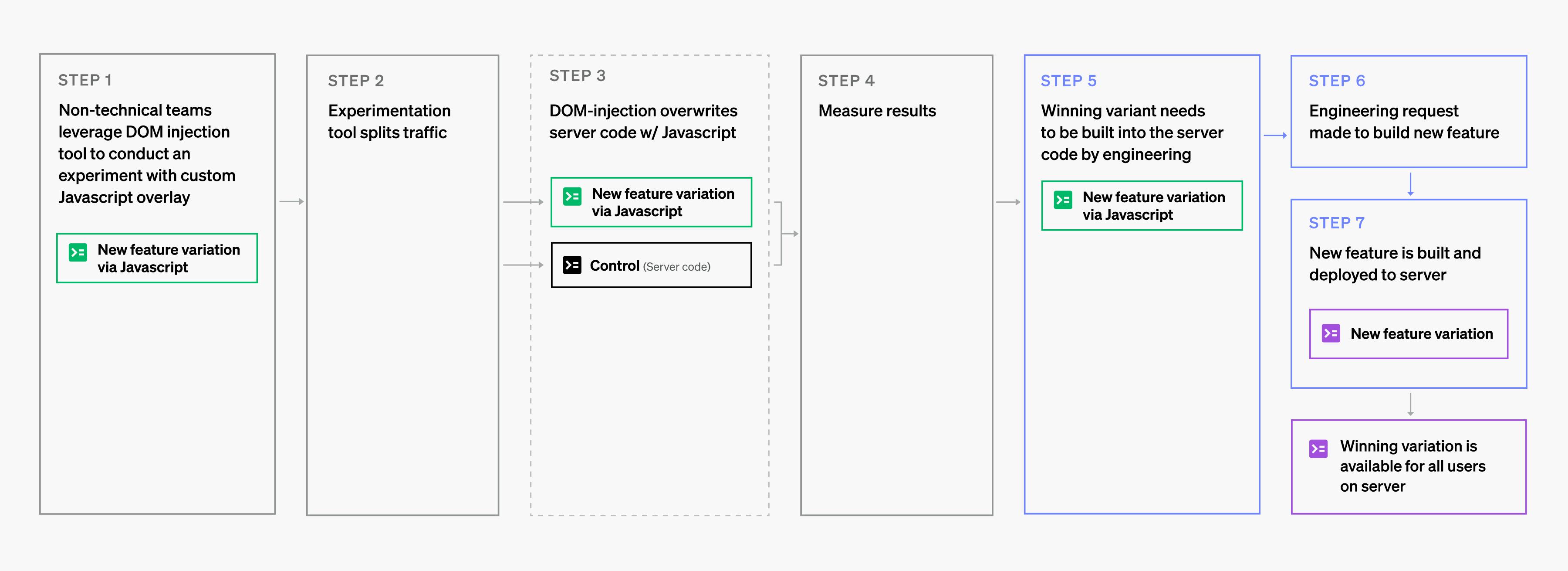
What happens during those days/weeks/months that pass between the day you find the best variation and the day you can correctly route all of your traffic to that variation? You lose money. Why?
After you’ve learned that one variation of an experiment works better than the other, every customer who is served the “losing” variation is at a higher risk of having a less positive outcome.
Let’s pretend we’ve run our experiment, and we know that customers prefer Variation A to Variation B. As long as the experiment keeps running, every customer served Variation B after we’ve learned which variation works best is a customer who is less likely to… do whatever it is we hope they do (convert, purchase, sign up, etc.).
Each of these are potential losses that could be potential wins, if we could easily change our application to take advantage of our learning. And that is where LaunchDarkly shines.
Choosing a winning variation in LaunchDarkly is as easy as routing all of your users to interact with the winning variation. And this is done instantly once the change has been made in LaunchDarkly. Changing the audience allocation to 100% for Variation A now means that no users will be served the less impactful variation!
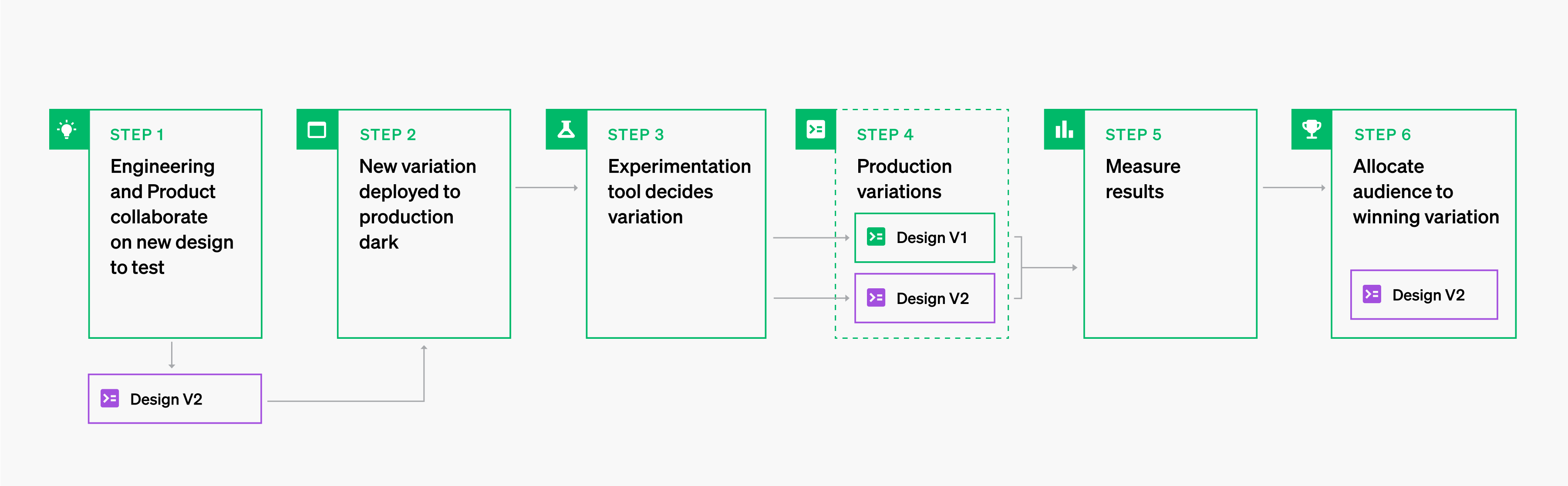
We also know that this code is good code. It has been engineered appropriately to work with our development best practices, rigorously tested, and does not need any further code deployments to start to capitalize on the margins we find in our experiment.
Experimentation is a team sport
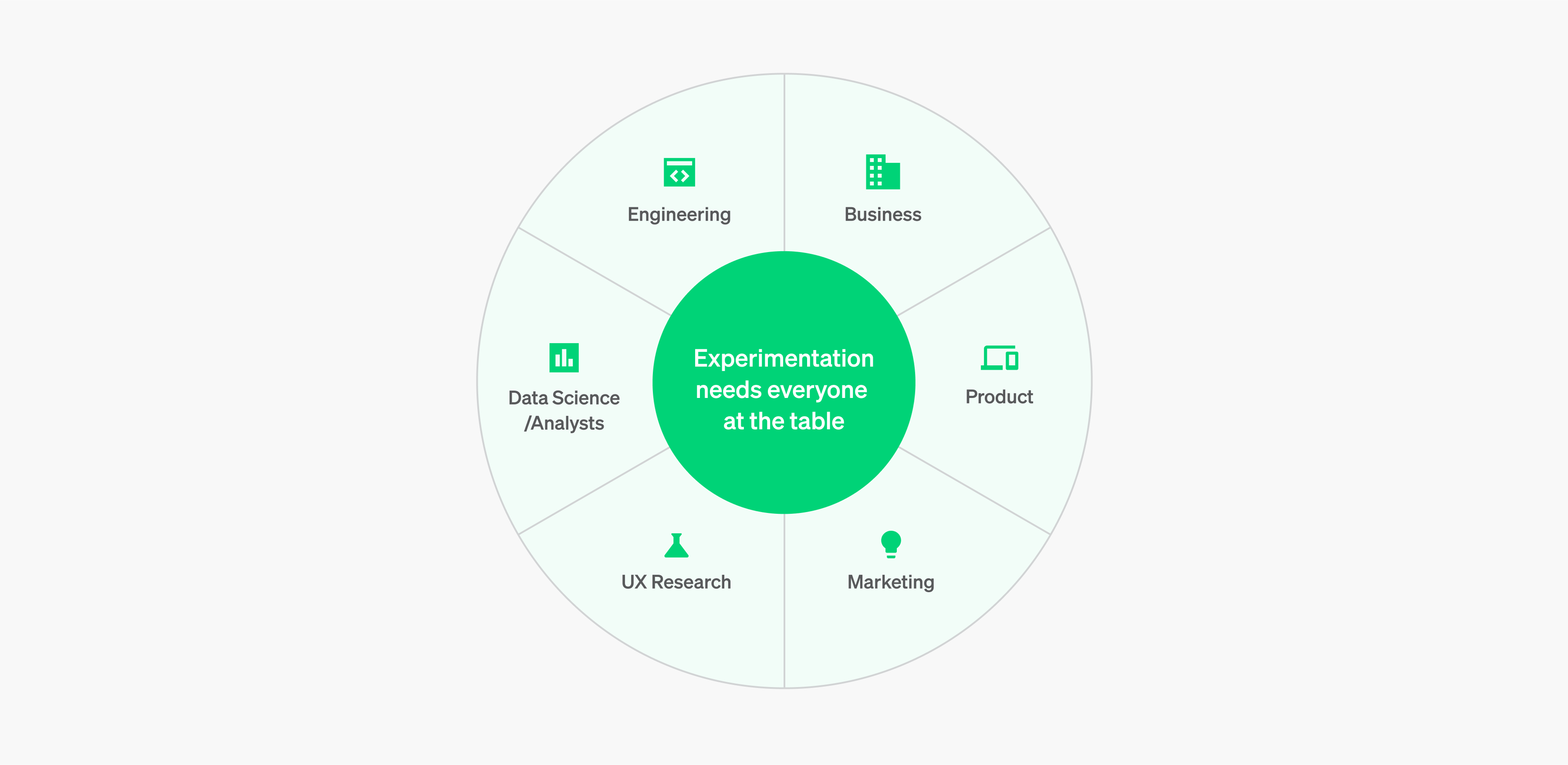
When you start to think about measurement as part of your release cycle, another powerful element is at play. This element can be slightly different depending on the organizational structure but always remains true no matter the org chart.
Experiments live and breathe where teams collaborate together. Experiments wither and die when done in a silo.
Thinking about the components of a good experiment:
- Aligns to a business problem that has a real impact
- Solves a customer need in an effective manner
- The feature functions as expected (broken code = broken experiment)
- Data can be captured to understand the impact of the feature
- Decisions on product direction can be made based on the results
It’s rare that a single team (or department) can most effectively represent all of the responsibilities in the list above. There might not be 6+ different organizations at the table when you sit down to run your next experiment. But you need someone knowledgeable about these different aspects of the product in order to implement an effective experiment.
This is another place where LaunchDarkly shines. For over 10 years, engineers have loved using our platform for targeted releases, dark deployments, and progressive rollouts. Features being developed to be released to your customers can be managed simply using LaunchDarkly.
Engineering teams have always loved using LaunchDarkly, but with our experimentation product, business and product teams are also discovering its benefits. The features that engineering builds and releases with LaunchDarkly are the same features that will be experimented on. This helps to ensure that product and engineering can collaborate and speak the same language.
Engineers can see the business value of the functionality that they have worked hard to release, product and business teams have a direct line of sight into feature functionality and impact, and leadership can start to get laser-focused on prioritizing the kinds of features that delight customers.
Experiments are a part of the release process
Software delivery is the driving force for most business experimentation. In any digital experiment, something needs to be done to vary something about the user experience. That could mean adding brand new functionality or making improvements to our existing products. We’re going to make that variation in our code, and we’re going to eventually turn that code on.
The feature flagging functionality in LaunchDarkly has been well documented. We offer the best feature management platform in the industry.
Tying your business experimentation to the release of the software that delivers it means you have a direct signal between the change that was made and the change to your business metrics.
When you manage your features with LaunchDarkly feature flags, you tie your business metrics directly to the change that impacted the customer. With LaunchDarkly Feature Management and Experimentation consolidated into a single platform, your analytics are cleanly tied to your release.
When tooling is scattered across different platforms, so much time is spent trying to make sense of nuanced differences between your tools. How much time is spent trying to reconcile X records in one system to Y records in another when the difference is actually based on how different systems count things slightly differently? WAY too much time.
A robust modern software release might look something like this:
- We’re ready to ship an update to a search engine on our website. We have a hypothesis that our existing search engine is not accurate enough and want to release a new version that we believe will be more accurate; we think that customers will make more purchases with us when they can find the items they’re searching for.
- Development has been completed, testing has been completed, and we are confident the code works.
- Targeted release in production to our dev_team uncovers a bug. Thankfully this will not impact our customers, so we can leave the flag on while we pinpoint the error, a hardcoded non-prod environment variable, which we fix.
- Development has been completed, testing has been completed, and we are confident the code works.
- Targeted release in production to our dev_team looks good!
- Guarded release to our beta_users monitoring for search latency and errors. LaunchDarkly will progressively roll out the feature while monitoring for regressions in our key operational metrics. This goes well and we achieve full release to our beta_user audience.
- We want to run an experiment to measure which search engine drives more purchases. To be safe, we plan to run a guarded release, progressing to a full audience over the span of a day to validate that there are no issues at full load.
- Once we’re confident that our code works well operationally, we can set up and run our experiment, giving 50% of our users the previous search and 50% of our users the new search. We have instrumented key metrics and observe that our new search does indeed drive more purchases! We also noticed that there were some areas where our new engine could have even more impact by looking at demographic attributes. This forms a new hypothesis that we’re going to test next!
- Rinse and repeat.
All of this is so easy to do from within LaunchDarkly.
Measure every release–experiment anywhere
A few of my former colleagues probably got sick of hearing me say:
“I might decide I don't need to experiment on every feature we release, but we should be able to experiment on any feature we release.”
I share a similar version of that nearly every time I talk to a customer or potential customer of LaunchDarkly:

This is why I fell so hard and fast for our approach to experimentation. It was what resonated with me as a potential customer, and what made me realize the progress we could achieve if we brought LaunchDarkly in as a tool. And as they say, the rest is history. Here I am!
But don’t just take my word for it:
"LaunchDarkly has been transformative for our team, enabling us to deprecate older tools and adopt a more flexible approach to feature flagging and A/B testing. This has helped us streamline workflows, reduce development resources, and focus on initiatives that truly impact our customers."
– Rema Morgan-Aluko, SVP Technology, Savage X Fenty
When product teams can get actionable insights on any release, businesses can focus on prioritizing the most impactful work, and engineers get to deliver features that they can see (and measure) adding value. This is a beautiful thing. It’s the efficient software development cycle we all dream about: where we’re building the things customers love, we’re aligned across the organization on the problems and possibilities, and we can bring everyone to the table to build the best… whatever it is you build!
Want to learn more about LaunchDarkly Experimentation? Sign up to get a personalized demo!
Like what you read?
Get a demo