





Gremlin recently published the first 2021 State of Chaos Engineering Report, surveying over 400 technologists from a range of company sizes and industries, primarily in software and services, about their processes around incidents and software deploys.
The report’s results revealed some interesting data points regarding the use of feature management as it pertains to high-performing teams.
In this post, we’ll explore how a feature management strategy is a cornerstone of safer deploys.
Things break, but the impact can be minimized
Failures will happen, that is a given. Finding ways to reduce the frequency of incidents is desired. The report found the most common causes of incidents were bad code pushes and dependency issues, as a bad push from one team can cause service outages for another.
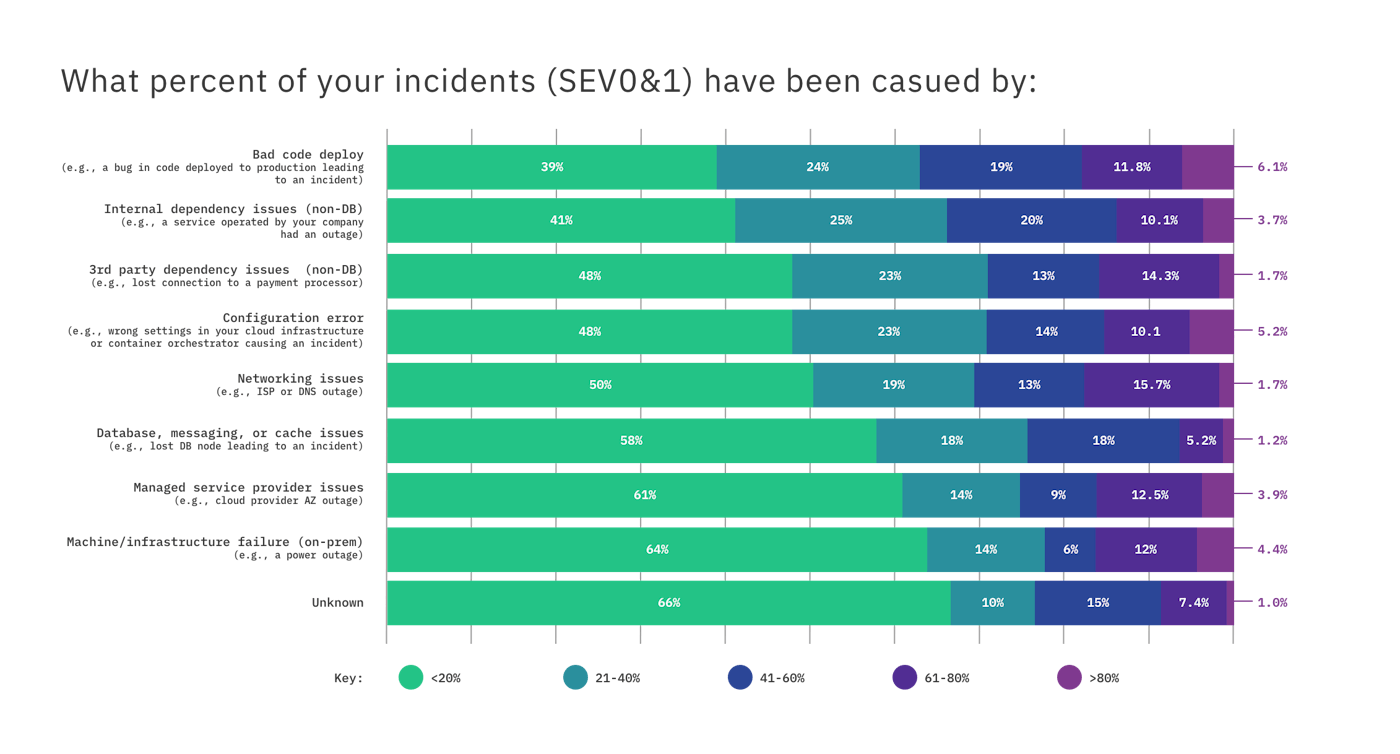
Factors causing SEV0&1 incidents including bad code deploys and dependency issues. All charts courtesy of Gremlin’s 2021 State of Chaos Engineering Report.
It’s bad when your code breaks. When a bad code push causes a service outage for another team, that’s worse. Not knowing all the dependencies within the code can result in a seemingly innocent code push causing an outage for another team. This is why you need to test in production with feature flags because you can reduce bad code pushes from impacting your user experience.
Feature flags enable you to test in production and determine if a dependency you weren’t aware of may impact the application in production. By deploying code behind a feature flag, you can test it with a small group of internal users to ensure there are no adverse reactions. And if something does break, you have minimized the impact, and won’t have to roll back the deployment.
Put the right processes in place
We’ve established you can’t stop all incidents. You can, however, be prepared and get notified as soon as things break. The Gremlin report found top-performing organizations had availability of 99.99% and a mean-time to resolve (MTTR) of less than an hour. A variety of tooling and processes were used to achieve this; two being circuit breakers and select rollouts.
In fact, 32% of those respondents that reported 99.99% availability also take advantage of circuit breakers, and the ability to quickly disable a feature if problems occur after a code deploy.
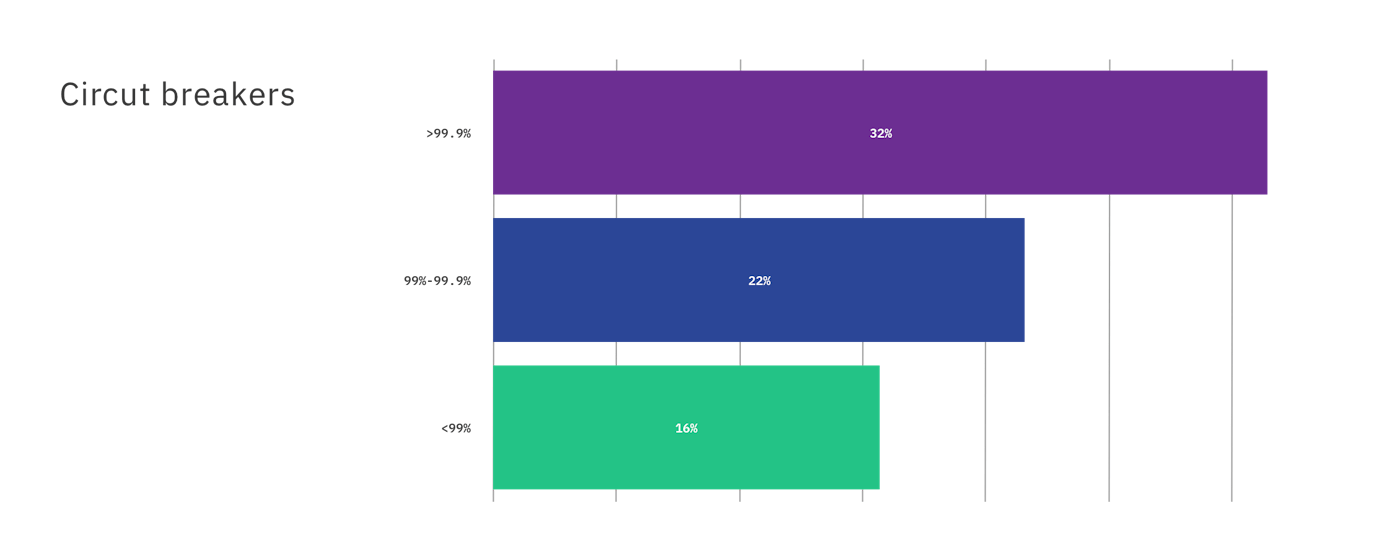
Percentage of organizations utilizing circuit breakers.
Even more organizations are selectively rolling out features through blue/green deployments, canary launches, or feature flags.
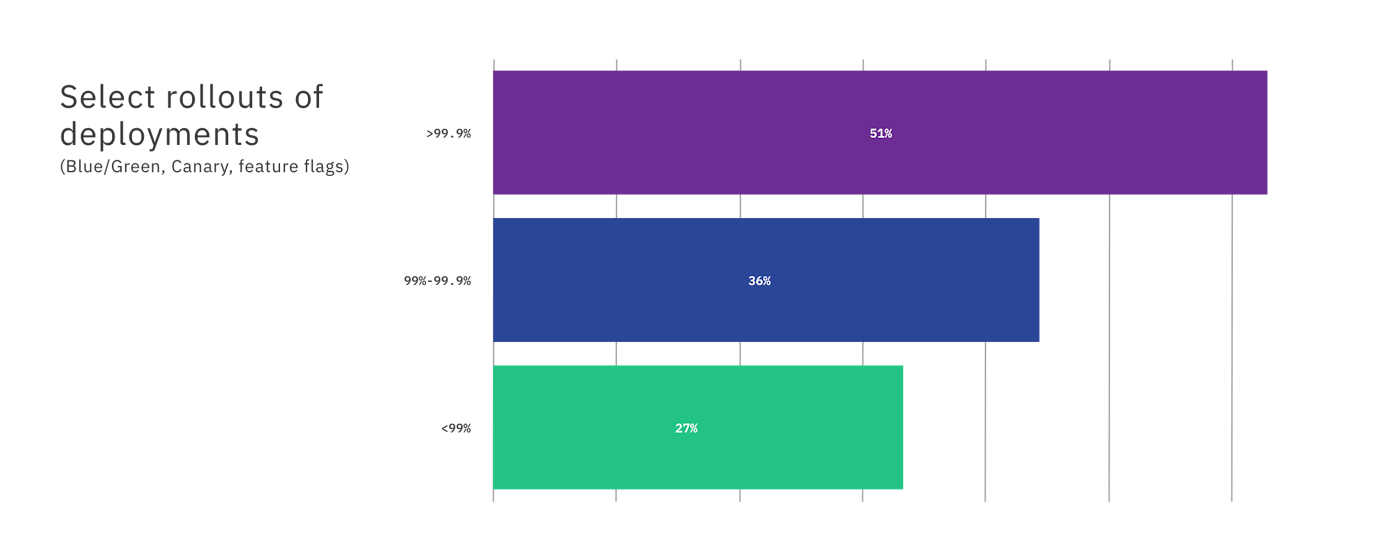
Percentage of companies using blue/green deployment, canary launches, or feature flags.
Monitor for anomalies
Given that things break, you want to know as soon as possible that something is amiss. This is where monitoring comes in. All the respondents to the survey indicated they were monitoring availability. Where things varied was in which metrics were monitored and how availability was monitored (real user monitoring, synthetic checks, or server-side responses).
Monitoring is a key element of a feature management strategy. When you deploy a feature behind a flag, you want to track relevant monitoring data to know how it performs. Synthetic checks and server-side responses are most useful in cases where a feature has been deployed to a small number of users. Relying on data from a handful of internal users may not reveal anomalies. You’ll need to run synthetic checks to have confidence in the feature before increasing the percentage of users with access.
Real user monitoring (RUM) and server-side responses become more relevant to look at when you have larger numbers of users accessing a feature. In that case, if you want to know the impact a feature has on the end-user before making a final design decision, run an experiment and collect metrics via RUM. Either way, it’s important to have a variety of ways to monitor to collect the right information for the right stage of the feature.
We suggest if you’re already using feature flags for circuit breakers, kick things up a notch and set up a trigger to disable a feature if performance thresholds are passed. You’re monitoring for error rates, latency, successful requests, and total uptime. If these drop below acceptable levels, your monitoring tools can automatically send a request to LaunchDarkly to disable a feature.
If you’re interested in learning more about how LaunchDarkly can improve your deployments, sign up for a demo.
Like what you read?
Get a demo