





LLM inference is the process of generating output from trained large language models. It is the cornerstone of the human-friendly and conversational outputs that make LLMs so powerful and has driven a surge in LLM usage across consumer and enterprise applications.
Of course, as LLMs increase in popularity, it has become more critical to control costs, reduce latency, and optimize throughput. While organizations that use cloud-based LLMs like OpenAI and Claude don’t need to optimize inference, teams that deploy LLMs like LLAMA, Gemma, Deepseek, or Mistral should experiment with several optimization techniques to achieve the best latency and throughput.
This article, part of our blog series on AI application development best practices, will explain LLM inference optimization in detail, including practical approaches for experimentation and measurement.
Summary of key LLM inference optimization concepts
The table below summarizes essential LLM inference optimization concepts that this article will explore.
Concept | Description |
|---|---|
Model parallelization techniques | Pipeline parallelism, tensor parallelism, and sequence parallelism help increase the throughput of LLM inference |
Optimizing attention mechanisms | Multi-query attention and grouped query attention can help in reducing the memory required by GPUs |
Quantized models | Quantization reduces model weight precision and activations, reducing the memory footprint. |
Sparse models | Sparse models replace weight parameters close to zero with zero to reduce memory requirements at the cost of accuracy. |
Model serving optimizations | In-flight batching and speculative decoding are serving optimizations that can help reduce latency. |
Model serving frameworks | Model serving frameworks like vLLM, NVIDIA Triton, and TGI come with built-in optimizations that can be configured while serving LLMs |
Capturing LLM inference metrics | Metrics like time for the first token and output tokens per second help assess the latency of your LLM deployment. |
AI application release management platforms | Such platforms featuring guarded releases can automate measuring the inference metrics across different model versions, configurations, and experiments. |
Understanding LLM Inference
An LLM is a transformer-based neural network with billions of trained parameters. During inference, LLMs take in an input sequence of tokens known as prompts to generate an output. The output can be the completion of the input, answers to questions in the input, or even code based on an LLM prompt.
Under the hood, LLMs combine deep neural networks with attention mechanisms (core components that allow a model to selectively focus on different parts of the input text when generating output) to understand the importance of various parts of the prompt and generate output accordingly.
A simplified version of the LLM inference process is as follows:
- Tokenize the input
- Compute the intermediate states called keys and values through matrix multiplications involving the weight parameters of LLM and the input tokens' embeddings.
- Use the attention mechanism to generate a score for each token using the keys and values. The attention score represents the relevance of each token to other tokens. This phase also involves matrix multiplications.
- Predict the next token through another set of matrix multiplications based on the attention output and intermediate states.
- Use the input, predicted tokens, and intermediate keys and values as the input for the next token generation.
- Repeat till a stopping criterion is reached. The two standard stopping criteria are a maximum number of tokens or a termination token.
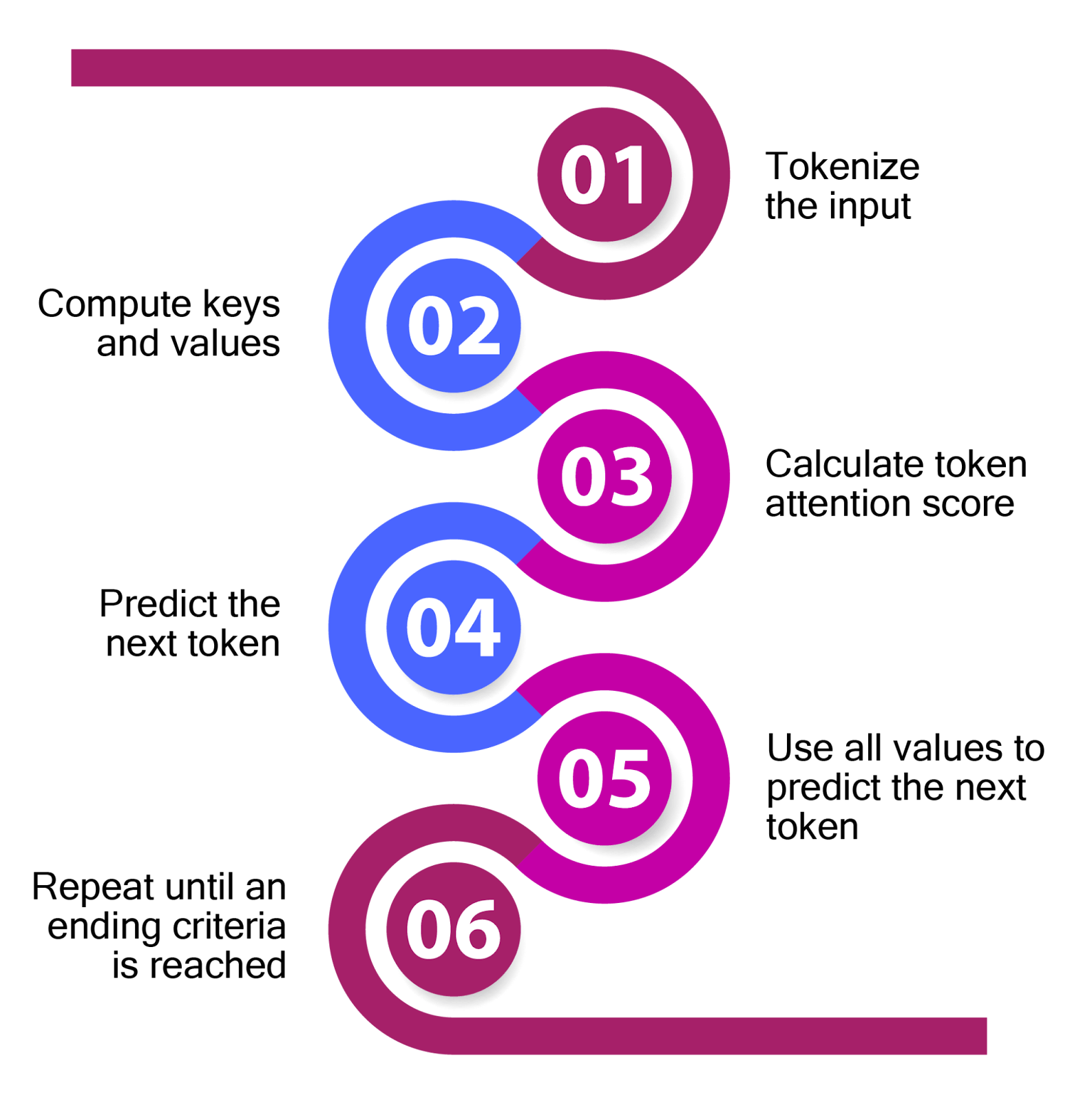
While this is an oversimplified version of the LLM inference process, we can pinpoint where bottlenecks may occur. First, the process involves many matrix multiplications. Second, LLM inference requires memory to hold the model's weight parameters and intermediate keys and values generated for past tokens until the current token.
While serving an LLM, GPUs provide the processing power for matrix multiplications. The GPU VRAM provides the memory required for holding the input tokens, intermediate keys, and values. Optimizing LLM inference requires using GPU processing power and memory more efficiently to improve throughput and latency.
Inference frameworks like vLLM, Triton, and TGI help enable LLM inference optimization by sharing the processing and memory loads between several GPUs. They also help optimize inference within a single GPU through techniques like batching and speculative execution. Speculative execution involves executing matrix multiplication before definitively knowing that it is needed to improve concurrency and performance.
Techniques for LLM inference optimization
There are four broad categories of LLM inference optimization:
- Model parallelization
- Attention optimization
- Model optimization
- Model serving
We’ll look at each in the following sections.
Model parallelization techniques for LLM inference optimization
Executing model inferences through several GPUs can help improve inference throughput and latency. This technique uses several smaller GPUs. Multiple GPUs are cheaper than a single large GPU with combined VRAM and processing power. The sections below explain three kinds of model parallelization.
Pipeline parallelism
Pipeline parallelism divides the model vertically into several chunks. In other words, it divides a deep learning network across its vertical layers, and each subset of layers is stored in a separate GPU. The following diagram shows this concept in action.
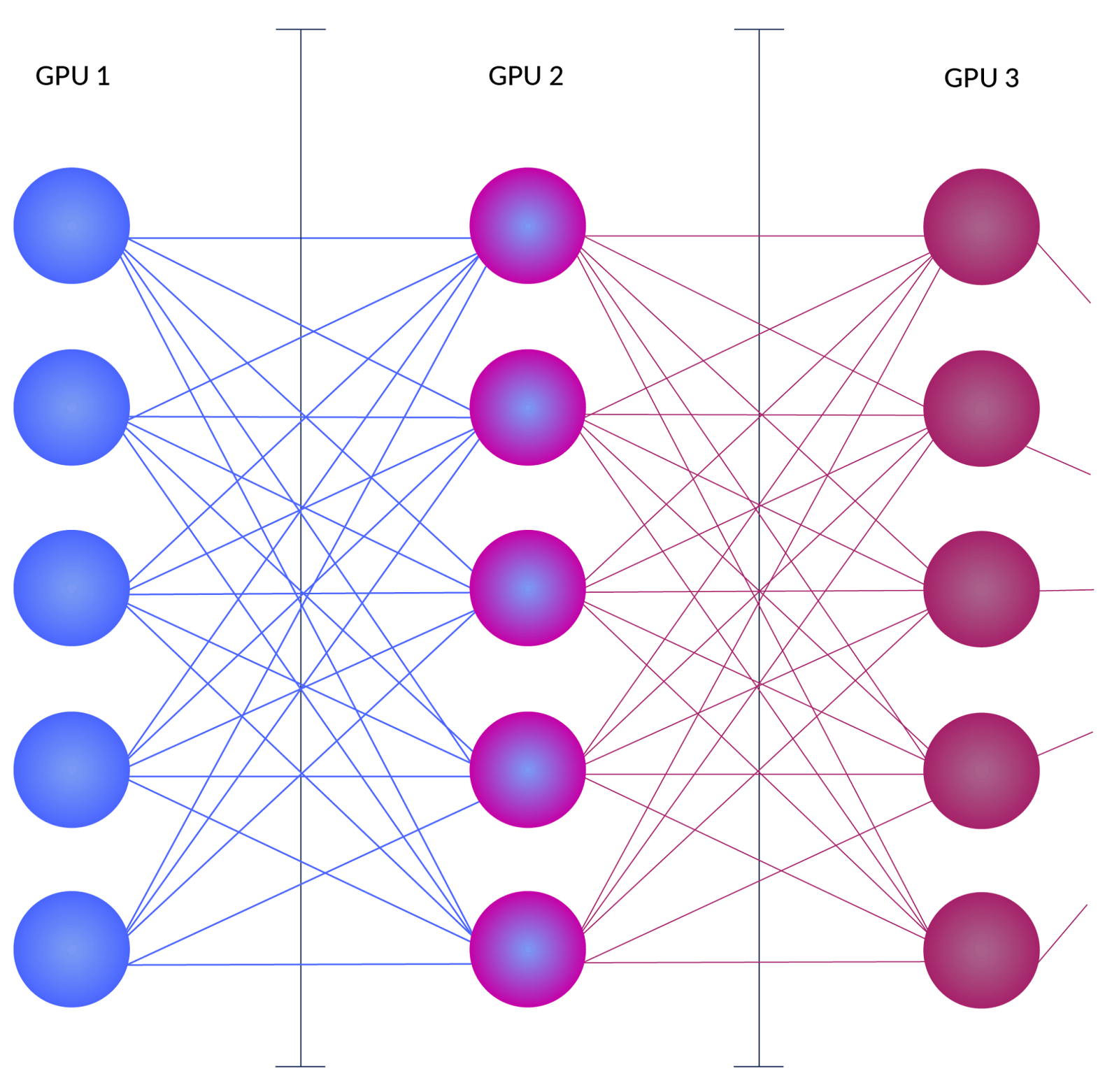
The advantage of pipeline parallelism is that the memory required by individual GPUs is smaller. The disadvantage is that since most computations are sequential, GPUs may wait idle until the output from the previous GPU arrives.
LLM inference frameworks provide configuration options to enable pipeline parallelism while deploying an LLM. For example, vLLM provides a startup option called ‘--pipeline-parallel-size’ to enable this functionality. You should specify the number of GPUs in your cluster to ensure that vLLM takes advantage of all available GPUs for pipeline parallelism. You can read more about it here.
Tensor parallelism
Tensor parallelism splits the neural network horizontally into several blocks. Each block is served through an independent GPU. This approach is especially beneficial in attention mechanisms, since several strategies can be used to independently manage the attention score generation and execute it in parallel.
Attention enhancements like multi-query attention and grouped query attention are good candidates for parallel execution. The diagram below shows this LLM inference optimization concept in action from the perspective of a simple neural network.
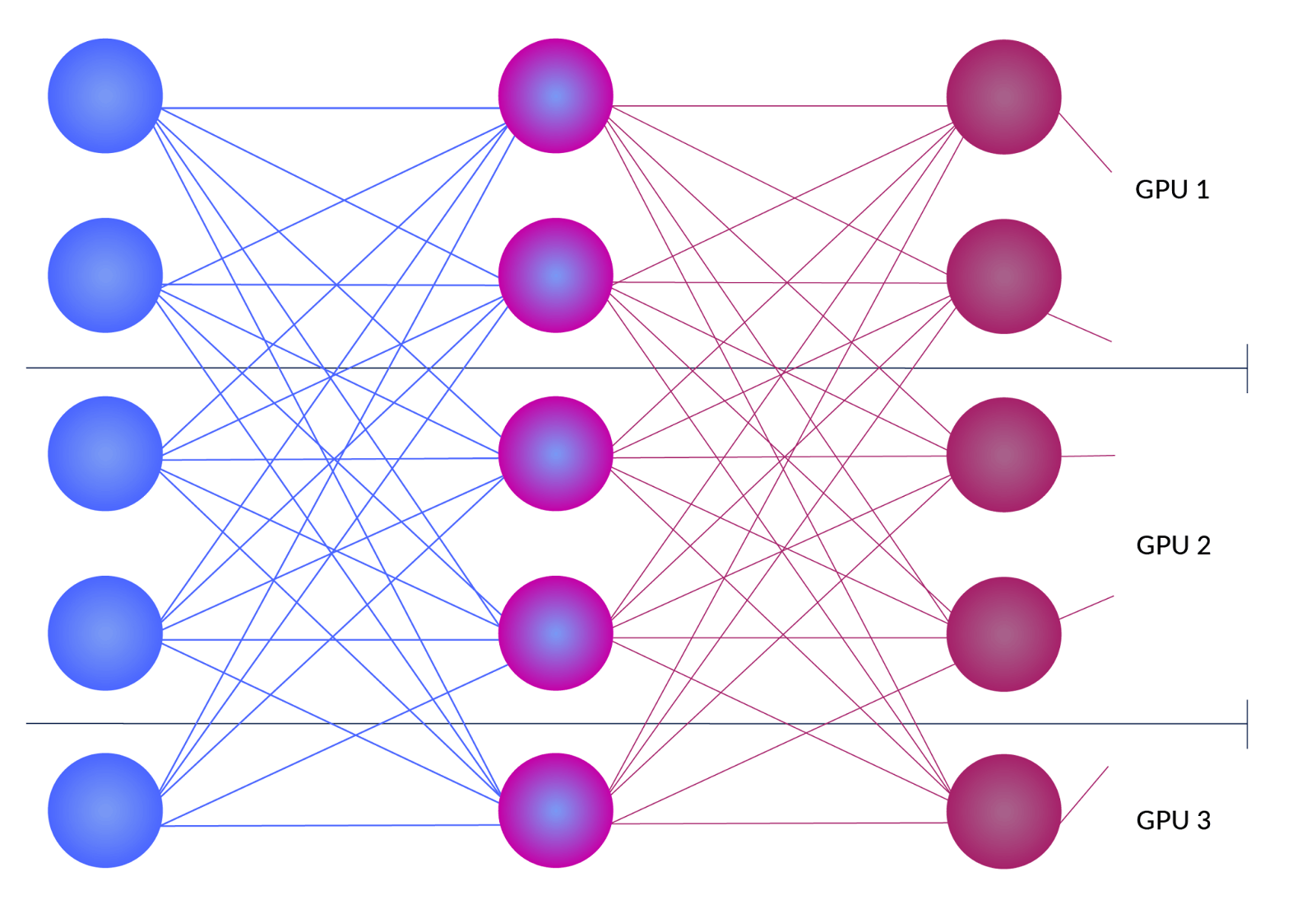
Similarly to the previous example, vLLM provides a startup option called ‘--tensor-parallel-size’ to enable this functionality. You can read more about it here.
Sequence Parallelism
Tensor parallelism works only in the case of independently manageable blocks like attention. In a transformer-based network, several other operations need to be executed to form the output. Operations like LayerNorm and Dropout can not be parallelized through tensor parallelism. Instead, the input sequence is divided into multiple manageable blocks and fed independently to the operations in multiple GPUs.
Sequence parallelism is a relatively new concept and is still not supported by all inference frameworks. For example, vLLM supports pipeline and tensor parallelism, but does not support sequence parallelism. Microsoft’s Deepseed inference library supports sequence parallelism through its configuration parameter ‘--ds-sequence-parallel-size’, which takes in the number of sequence groups as the value. You can read more about it here.
Attention optimization techniques for LLM inference optimization
Attention optimizations involve enhancements to the original attention mechanism by executing multiplications in parallel through various strategies. To better appreciate attention optimization techniques, let's first understand the original attention mechanism.
Attention is a technique for representing how each word in an input sequence relates to every other word. This concept is essential in sequence-to-sequence transformations because some words in a sequence may be more important than others when generating the output.
Consider the question, ‘Who is the president of the USA?’. Before generating the output, the LLM must understand how each word is connected to every other word in the sentence.
A naive thought would be that every other word is most related to the next word in the sequence. But this is not always true. For example, consider the sentence: ‘The lady in white is the queen’. Here, the words ‘lady’ and ‘queen’ have a far stronger connection than other words next to ‘lady’.
Attention solves this problem by calculating the degree of connection between all word pairs. Let’s break this down by unpacking three standard attention-related terms:
- Query- A token currently being evaluated
- Key- A token that a model compares a query with
- Value- Mathematical representation of the relationship between a token and query
These three components are the building blocks of a self-attention mechanism. While calculating attention scores, LLMs compare a query with a key. The model then creates a value to represent the connection between them mathematically.
Modern LLMs employ a more advanced version of self-attention, known as multi-head attention. In multi-head attention, attention scores are calculated for several query, key, and value projections multiple times, allowing the LLM to understand the connections between token pairs from multiple angles. The following section details two methods of optimizing attention during inference.
- Multi-query attention: This technique limits the projections of query, key, and value involved in multi-head attention to only queries. Keys and values are shared among the projections of the query, thereby reducing memory requirements at the cost of some accuracy.
- Grouped-query attention: Instead of using a single project for key and value, this technique groups the query projections and generates projections for keys and values corresponding to each group. Within each group, it behaves exactly like multi-query attention. This recovers some accuracy drop compared to multi-query attention at the cost of increased memory usage.
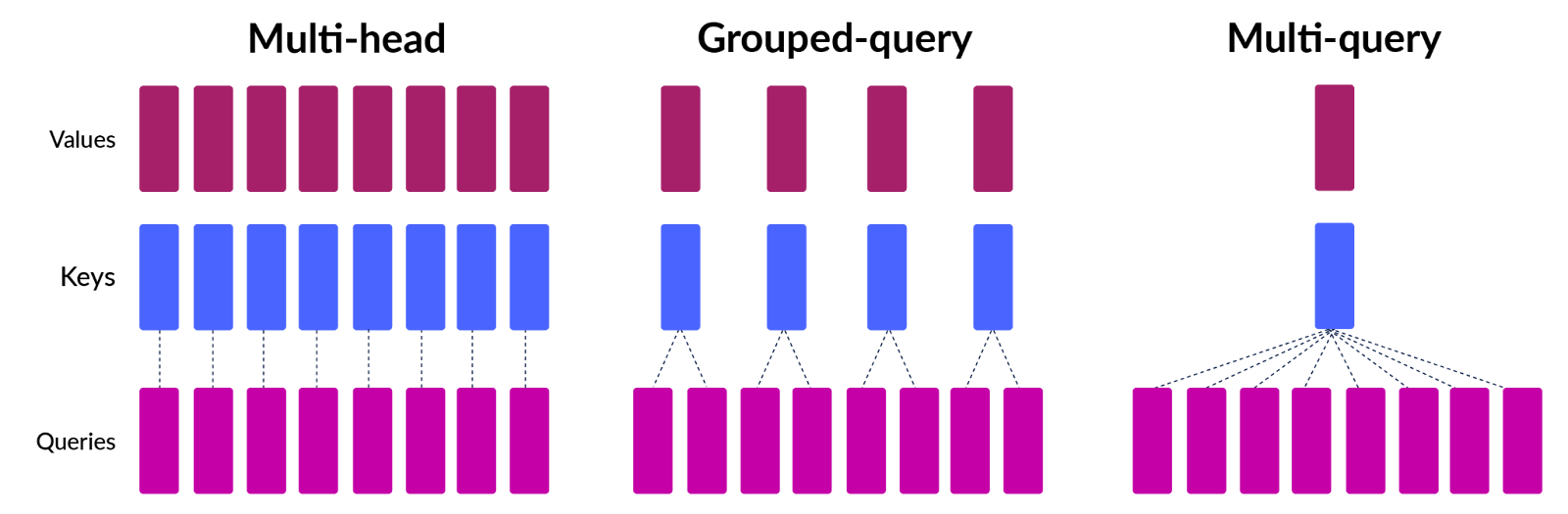
Since attention optimization techniques are closely coupled with the model definition, they must be defined during the training phase. Therefore, LLM users do not need to take any explicit action to enable these optimizations in the inference framework. If a framework supports a model trained using these techniques, the optimization will be automatically applied during inference.
Model optimization techniques for LLM inference optimization
Model optimization techniques aim to reduce the memory footprint of LLMs by compromising on some accuracy. The sections below explain model quantization and sparse models, which are two of the most common model optimization techniques.
Model Quantization
Quantized models use model weights that are less precise to reduce the memory footprint of LLMs. When LLMs use billions of weight parameters, even reducing a single bit of precision can significantly reduce memory requirements.
Most modern models are trained with 32 or 16-bit precision. At the cost of reducing some accuracy, one can use an 8-bit or 4-bit precision model for inference. The difference in output has proven negligible when using reduced precision models. Quantization is not an inference framework configuration. One needs to download a quantized version of the specific model or generate a quantized version using available open-source utilities.
Sparse Models
Creating a sparse model involves exploring the weight parameters of the LLMs to identify values closer to zero and then replacing them with zero. This helps to shrink the model and represent it in a condensed form. GPUs can take advantage of these sparse models to accelerate processing. Developers can utilize sparse versions of popular LLMs, such as LLAMA3, to optimize inference.
Model serving techniques for LLM inference optimization
The sections above used techniques that split the models across multiple GPUs or reduce the model's footprint. Another way to optimize LLM inference is to bring some parallelism into the input sequence. The following section outlines methods that improve overall throughput by aggregating input sequence processing.
Inflight batching
Batching requests in LLM is challenging due to the difference in the length of input and output across runs. Some input sequences in a batch may finish faster than others and then have to wait for the batch to finish.
In-flight batching solves this problem by immediately evicting the completed sequence from the batch and filling it with another sequence. Inference frameworks like vLLM support in-flight batching by default. When using frameworks like Triton, one needs to configure both the framework and the batch size separately in the model definition.
Speculative Decoding
LLM inference uses an auto-regressive iteration to generate tokens. This means every token before the current token is required to generate the next token. Due to this dependency, there is very little that can be done to parallelize the generation process. Speculative decoding utilizes smaller, less accurate models to generate possible outputs before the actual LLM output, enabling parallelism. One can execute the mathematical operations on the speculated output and then accept or reject them based on what the actual LLM generates. This helps reduce the time lost in computation after the token is generated. Frameworks like vLLM and Triton let one configure separate speculative models for this generation.
While serving frameworks optimize the core compute path, runtime control platforms like LaunchDarkly allow teams to safely manage and toggle different models, decoding strategies, or prompt configurations in production. This makes it possible to compare configurations across real traffic without redeploying or introducing risk — a key capability when optimizing AI applications iteratively.
🚦 Why Runtime Control Matters for AI Ops
Most LLM optimization happens at the model or infra layer — but the real challenge starts when AI hits production.
Runtime control lets you:
- Toggle between models, prompts, or decoding strategies
- Experiment safely without redeploying
- Roll back underperforming configs instantly
- Track latency, cost, and user metrics in real time
Tools like LaunchDarkly make this control layer practical. You don’t just tune the model — you control the experience.
Measuring LLM inference performance
Optimizing LLM inference involves trying the techniques discussed here with various inference frameworks and then comparing them to select the best one for your use case. This selection process includes running experiments in staging or production environments under real user traffic or using LLM testing techniques based on a synthetically generated test data suite.
It is important to quantify the performance of your LLM deployment and monitor it while you make changes. The following metrics capture the performance of LLM inference in terms of latency.
- Time for first token (TFFT): Represents the time the LLM takes to output the first token after it receives the prompt.
- Time per output token (TPO): Captures the average time per output token for each user interacting with the system. Having this value slightly higher than a person can read will give the impression that the LLM is fast.
One can define the latency of an AI model deployment using the following formula.
Latency = TFFT + TPOT x ( Number of generated tokens )
Capturing and continuously monitoring the metrics of LLM inference is very important for managing LLM deployments. LLM models are evolving quickly, requiring updates to AI applications to capitalize on the value of the latest versions. Charting measurement values over time goes a long way in understanding LLM-based application efficiency through the configuration, model changes, and creation of an audit log.
LaunchDarkly enables this in practice by connecting config variations (such as prompt templates or model versions) with real-time metric collection. Teams can monitor changes in token-level latency, cost per run, or user experience. They can also automatically roll back underperforming variants based on predefined performance thresholds. You can find a complete list of inference metrics supported by LaunchDarkly here.

Closing thoughts
LLM inference is a complex process involving numerous matrix multiplications and intermediate state reads and writes to memory. One way to optimize LLM inference is to share the processing workload and memory workload among several GPUs using pipeline, tensor, and sequence parallelism. Other methods include attention and model optimization techniques, as well as aggregating input sequence processing through techniques such as speculative decoding.
With several strategies to explore and the changing nature of LLMs, optimizing inference can be a herculean task that involves many experiments. LaunchDarkly is built to support exactly this kind of iteration. With runtime configuration control, built-in experimentation, and AI-specific metrics tracking, teams can safely test, monitor, and evolve their AI applications without slowing down or risking production stability. You can read more about LaunchDarkly AI configs here.