Maximizing Our Machines: Worker Pools At LaunchDarkly
Maximizing Our Machines: Worker Pools At LaunchDarkly
Published August 4, 2022

Setting the scene
It’s Monday. We’re starting to get reports from customers that they aren’t receiving new sessions. Just the week before, we brought on a new customer who produced more traffic than any other customer combined and we’re finally starting to see the consequences. This overloaded our systems so the amount of data that we were processing wasn’t keeping up with the queue.
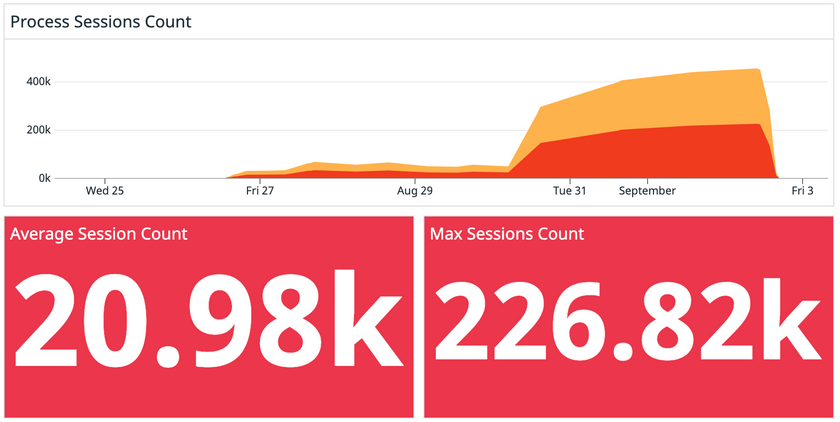
We needed to fix this, and fast. Customers weren’t getting value from our product.
A ray of hope
We noticed we weren’t using the resources in our servers to their fullest extent, so we decided to parallelize tasks at a larger scale than we’ve ever done.
We couldn’t just spawn rogue goroutines because that could go out of control, simultaneously making this code hard to track and overloading the resources in our machines. So, we needed a way to control the goroutines. We figured the easiest way to do this was with a worker pool.
In my search for a good worker pool package, I found https://github.com/gammazero/workerpool. It’s was clearly simple to use, well tested, and had most of the features we wanted, so we went with it. Using this package was as simple as adding the following code to our project:
The Comeback
Once we added a worker pool to our backend, we noticed an immediate difference. With a worker pool of 40 goroutines, we were comfortable in our memory usage while quickly catching up with the queue of sessions. What was building up over the course of ~4 days quickly was processed in a matter of hours.
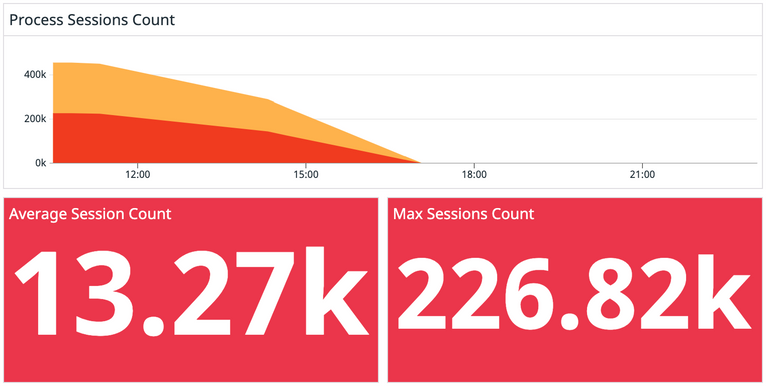
The Moral of the Story
Navigating this incident brought us a few key learnings:
- Take advantage of the resources in your machine. If your processes are running comfortably within the bounds of your machine, make changes to parallelize so your system won’t be debilitated when you bring on a new, large customer.
- Instrument proper alerting that makes sense for your systems. If we had alerts set up for this type of overload, we would have been able to notice the lag over the weekend and push a fix before customers could realize our systems were behind.
- When onboarding large customers, have a follow-up workflow to make sure everything is running as it should post-onboarding.