Most developers love feature branching because it makes the development process more flexible. It enables us to update a bug fix or work on a new feature independently from the main branch. But, now and then, feature branches might cause headaches or even failed releases.
Following best practices, and knowing what to avoid, helps enable more efficient feature branching. Let’s explore what feature branching is, and why developers create feature branches. Then, we’ll share our experience of what works—and what doesn’t—to help you successfully implement feature branching in your DevOps processes.
What’s branching and why do it?
Okay, so distributed source control systems, like Git, enable developers to work independently from development teams. This independence is thanks to branching. When developers continuously update code in a centralized repository, it often results in conflicts and break-the-code situations. Branching helps reduce these issues.
Each developer can work on a specific branch, validate the code using a pull request, and merge the code into other branches or the main branch (trunk) only after approval. This makes it so the main branch will always be healthy and up-to-date with high-quality code.
Two typical use cases for branching are feature branching and bug branching. Starting from the main branch, a developer writes a piece of code to introduce a new feature, or they develop a snippet of code to fix a bug. After this developer tests their code, they trigger a merge operation. This integrates the new element into the main branch (or fixes the bug).
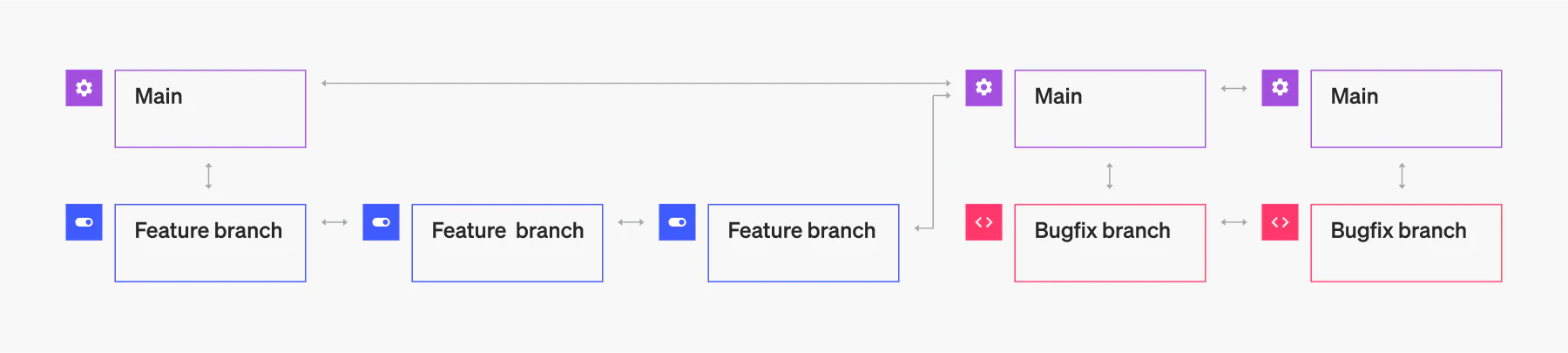
Creating feature branches helps review changes, enables faster code update approvals, and keeps your main branch solid and high quality. Once a merge happens, the new version can be a starting point for the next feature or bug-fix branch. Developers control the merge operation itself using pull requests, which dramatically improves code quality. This is because multiple developers review the code before it goes live. DevOps practices like peer review, approvals, and branch policies are the technical bits making this possible.
If a feature isn’t accepted, or if it doesn’t need to move into a production state yet, we just keep it where it is and don’t merge it into the main branch.
One catch here, though, is that feature branches have the risk of turning into longer-living branches—branches that sometimes stay there forever. Feature flags come in handy for mediating this issue. We’ll touch on that later.
The Don'ts: Practices to Avoid
There are some practices to avoid when integrating feature branching into our development lifecycle. We’ll start with the don’ts before highlighting the dos.
Failing to communicate and introducing merge conflicts
One major pitfall in feature branching is a lack of communication across teams. Collaboration is vital in any DevOps methodology. And while we might assume it’s easy to integrate, it’s not. If developers don’t clearly, frequently, and effectively communicate with each other about the features they’re working on, it can cause merge conflicts. These conflicts are sometimes described as "merge bombs" if there are several occurring at once, like at the end of a sprint.
In addition to the time lost trying to fix the conflict, the team can also face code loss because of removed snippets. Plus, conflicts can also introduce new issues, which someone must handle in yet another feature branch.
Failing to check and track changes
You may be familiar with code smell—a source code characteristic that may indicate a deeper problem. You might also be aware of technical debt, which involves implementing an easy solution that we can use now, but that will ultimately create more work later. Both code smell and technical debt are considerable risks in any development cycle. This is because nobody checks code after launch, leaving bugs, issues, security vulnerabilities, and unused features behind.
Teams may deploy many new feature branches to fix these new problems—assuming that will actually repair the main problem. But often it doesn’t, and as a result, commit messages will keep piling up. It then becomes increasingly challenging to understand the changes, determine what was changed, and figure out where to find them.
Letting branches pile up
When the number of feature branches grows, it slows our overall release mechanism. This is because we can only run a new release when we successfully complete a feature branch merge. However, this also leads to new challenges, as the number of bug-fix branches grows with the same velocity.
While we initially introduced feature branches to help us, it’s easy to see that they’re ultimately harming us. Tools like GitFlow try to help here, but in the end, complexity remains—a signal that we should have handled our feature branching differently.
The Do's: Best Practices
Although feature branching may have some pitfalls, as we’ve discussed above, some best practices can help make it a successful part of our DevOps practices.
Limit branch lifetime
We should ensure our feature branches are short-lived by giving them a limited lifetime. The more frequent merge operations happen, the fewer merge conflicts we have to battle afterward.
We should always try to publish only finalized, production-ready code without bugs. With that said… we also shouldn’t be afraid of publishing code that may have bugs. We can put feature flags in place that enable us to keep a feature branch update in an off-state. Doing this ensures that nothing will happen that could break our application. Then, when it’s ready, we can toggle it on.
Limiting the number of branches like this helps reduce the code’s complexity.
Ensure communication
Recalling the don’ts list, lack of communication is a significant feature branching pitfall. A culture of continuous collaboration, sharing feedback, and taking the necessary steps to expedite the peer review process all help ensure our feature branching success.
With this communication in place, teams are less likely to overlap their features and introduce code conflicts.
Manage the scope
We need to be careful to manage the scope of feature branches. Every minor code change doesn’t need its own feature branch. When it’s time to create a new feature branch, its purpose should be immediately evident and represent a substantial modification or addition to the code.
Limiting the number of branches helps reduce the code’s complexity.
Adopt a naming convention
It’s helpful to adopt a naming convention when creating and managing feature branches. Developers often observe some best practices for naming Git branches. Typically, they rely on three primary Git branches:
- Development: The primary development branch is isolated from the main production branch to allow developers to work freely.
- Master: This is the repository’s primary default branch. Developers can only merge code here, once thorough review and testing are completed.
- Quality Assurance (QA): Testing code changes and ensures changes are ready to make their way to the production environment.
In addition to these three primary branches, developers also often incorporate temporary branches representing their efforts to fix problems or make changes. These are the short-lived branches that are necessary for feature branching. These temporary branches only exist until someone merges them into a regular branch. They include:
- A bug-fix branch
- A feature branch
- An experimental branch
Sticking to these naming conventions helps teams keep track of the various branches.
Use feature flags
Maybe you saw this one coming, but there’s one final best practice that shouldn’t be overlooked: Introducing feature flags (or feature toggles) as part of our development lifecycle management. Combining feature branching and feature flags enables DevOps teams to work faster. They can separate the feature code development work from the actual feature releases.
When teams integrate the feature code into the application source code (out of the merge operation to the main branch), the application may not use the feature immediately. It might be up to the backend teams to unlock the feature—typically using feature flag orchestration—or the application’s end-user may enable a specific feature or leave it turned off.
When development teams use a centralized orchestration solution, they can define feature flags and their corresponding mode, on or off. Next, developers integrate the necessary software development kit (SDK) or packages into their application source code and apply them like an if-then-else statement.
Using LaunchDarkly’s feature flags, the piece of code inside a feature branch contains not much more than the reference to the orchestrator and feature flag itself. It reads out the flag’s state. That way, DevOps can turn on (and off) individual features and code snippets within branches without changing the code itself.
Conclusion
Branching is a prevalent mechanism in modern software development, thanks to distributed source control solutions such as Git. Developers often use branching for feature branches, bug-fix branches, or pre-release branches.
While feature branching helps developer teams move forward, it does have some pitfalls. Keeping in mind what not to do and some of the best practices we discussed here should help you get started fast.
LaunchDarkly’s feature flags can help optimize your feature branching. Our feature flag management solution helps reduce your need for additional branches while ensuring stable, ready-to-release code with faster development cycles. Check out one of our demos to see how feature flags can help you take control of your code updates.