

.webp)



If you're running on AWS, chances are that Lambda, AWS's function-as-a-service offering, plays an important role in your application. That's true whether they form the basis of a microservices architecture or they just run arbitrary compute tasks required for your application to function properly. The good news is that you can bring the benefits of feature flags and feature management to your release processes in Lambda using LaunchDarkly.
Feature management isn't just about visible features that users' can interact with. It is also about the backend code that makes your application function. Being able to add kill switches, feature toggles, and more to Lambda functions becomes critical as your team adopts feature flags. While LaunchDarkly works out-of-the-box in Lambda, there are some special considerations you need to know about when working in a serverless environment.
This article will cover how to get LaunchDarkly set up in Lambda, and show you how to handle those aspects that are unique to serverless.
LaunchDarkly in Lambda
The good news is that integrating LaunchDarkly into Lambda functions is pretty straightforward. You'll need to install and configure the relevant SDK for your language. Here's one way to do this using the LaunchDarkly Server-Side SDK for Node.js:
1. Create a new Lambda from scratch using the Node.js 16x runtime in AWS.
2. Pull the function code down locally (for example by clicking the "Actions" drop down and choosing "Export").
3. Within the project files locally, install the Node SDK via npm install launchdarkly-node-server-sdk.
4. Require and configure the SDK. This can occur outside of the handler so that the SDK is not reinitialized every time the function is run:
const LaunchDarkly = require('launchdarkly-node-server-sdk')
const client = LaunchDarkly.init(process.env.LAUNCHDARKLY_SDK_KEY)5. Wait for the client to initialize and then start getting flag values. This must occur within the handler. Note that the below example just passes a "anonymous" as a key, but you can, of course, pass more detailed targeting information.
await client.waitForInitialization();
const flagValue = await client.variation("my-flag", { key: "anonymous" }, false);6. Re-upload the updated function, for example by zipping it up and choosing the "Upload from" and then ".zip file" option in the AWS Lambda console.
7. Set the LAUNCHDARKLY_SDK_KEY environment variable by going to the "Configuration" tab and choosing "Environment variables". You can obtain your key within the LaunchDarkly flag dashboard by clicking Command/Ctrl + K and then choosing "Copy SDK key for the current environment" and finally "Server-side key".
8. Test your function.
You should now be able to retrieve flag data within your function and alter the logic of the function accordingly.
Using a Lambda Layer
You can repeat the above process for every Lambda you've deployed that needs to use LaunchDarkly, but there's an easier way to ensure that all your Lambda functions have quick and easy access to LaunchDarkly, and that's by creating a Lambda Layer. The process of doing so is very similar to the above.
Here's how to do it for the Node.js runtime:
- Create a local folder and, within that folder, create a
nodejssubdirectory. If you are using a different language runtime, you can find the relevant location for dependencies here. - Within the
nodejsdirectory, runnpm install launchdarkly-node-server-sdk. - Compress the contents of your layer directory (i.e. the nodejs directory) but not the containing directory. For example, if the path to the project and
nodejsfolder is/layer/nodejs, ensure your zip does not contain the outer/layerdirectory. - Go to the Layers page within the AWS Lambda console and click "Create layer".
- Give the layer a name. For example,
launchdarkly-node-sdkand choose Node 16.x as the supported runtime. Finally, upload the zip file containing your layer.
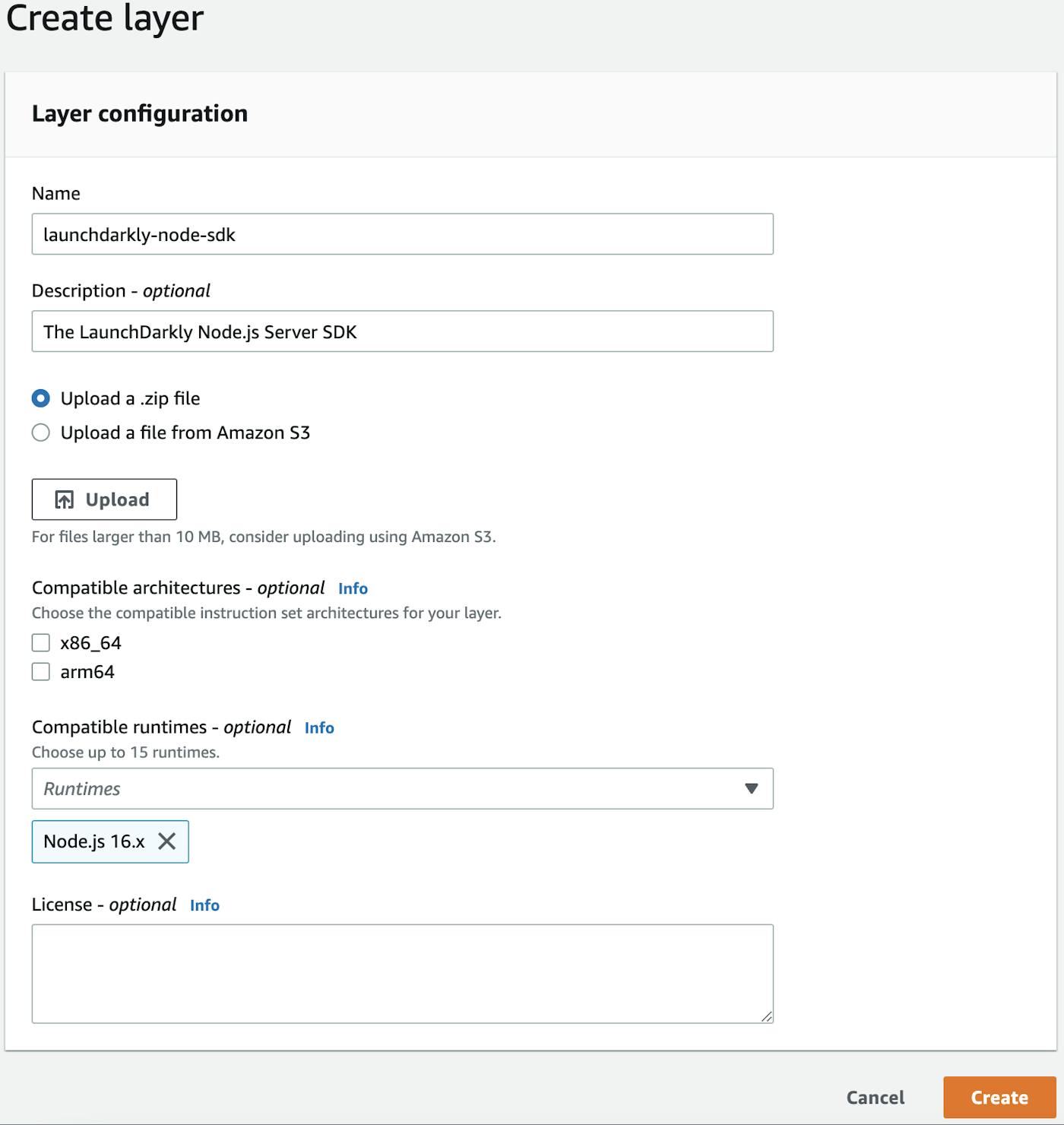
Now that you have the layer set up, it's relatively easy to use in any Lambda function that requires the LaunchDarkly SDK.
- In the AWS Lambda console, open the function that you want to add the layer to and scoll down to the Layers section at the bottom of the page. Choose "Add a layer".
- Select the "Custom layers" option and then, from the dropdown, choose your "launchdarkly-node-sdk" layer. Click "Add".
That's it! Now your Lambda can use the SDK without needing to manually install it or upload the npm_modules directory (if this is the only npm dependency you have, even the package.json and package-lock.json are no longer needed). However, the code within your Lambda to initialize the SDK and get flag values will remain the same and you'll still need to set the SDK key as an environment variable.
Caching data in a data store
Behind the scenes LaunchDarkly does a lot of things to make retrieving flag values incredibly fast, including delivering flags from the edge, caching flag data locally and streaming updates. This means that getting the SDK client initialized and retrieving flag data takes under 25 milliseconds.
However, using a data store can help speed up the process by allowing you to get the latest flag data without ever needing to make an external call outside AWS. For example, LaunchDarkly's SDKs make it simple to configure DynamoDB as a data store.
First, you'll need to add the DynamoDB extension for the language you are building your Lambda in. For Node.js, that would mean installing the add-on via npm (npm install launchdarkly-node-server-sdk-dynamodb) or adding it to your Lambda Layer and then requiring it as shown below.
const LaunchDarkly = require("launchdarkly-node-server-sdk");
// The SDK add-on for DynamoDB support
const {
DynamoDBFeatureStore,
} = require("launchdarkly-node-server-sdk-dynamodb");Next, you'll need to create an instance of a store object that can be passed as a configuration option to LaunchDarkly. You'll need the DynamoDB table name, which can be passed as a string or set as an environment variable. You can also specify the caching behavior for the data store if needed.
Within our configuration options, we'll want to specify useLdd as true. This will launch the client in daemon mode. What this means is that the client will use DynamoDB as the source of truth for flag data without calling LaunchDarkly.
const store = DynamoDBFeatureStore(process.env.DYNAMODB_TABLE);
// useLdd launches the client in daemon mode where flag values come
// from the data store (i.e. dynamodb)
const options = {
featureStore: store,
useLdd: true,
};
const client = LaunchDarkly.init(process.env.LAUNCHDARKLY_SDK_KEY, options);From this point on, you can get flag values as normal, but the LaunchDarkly client will only go to DynamoDB. You may be wondering, how do I get the latest flag data into DynamoDB? By default, the SDK client will cache all of the values as soon as it is initialized with a configured data store, but if you're in daemon mode that won't happen.
One solution is to create a separate function that will only initialize the data store and the SDK client (not in daemon mode), allowing it to automatically synchronize flag data. This function can then be called whenever a flag is changed via LaunchDarkly's webhook integration. You can see that solution discussed in detail in our guide on using LaunchDarkly in serverless environments.
This works, but there's a potentially better solution depending on your needs in our Relay Proxy. So let's explore that next.
Using the Relay Proxy in AWS
While it is definitely not a requirement, there are some great use cases for LaunchDarkly's Relay Proxy, a number of which apply to working in a serverless environment like AWS.
- You need to reduce your app's outbound connections because you have thousands or tens of thousands of servers all connecting to LaunchDarkly and those connections are overwhelming your network. In a serverless context, this can potentially incur an increase in your overall costs.
- You want to keep user data private, so your SDKs evaluate against your Relay Proxy so your private data never leaves your network.
- You want to facilitate faster connections with SDKs which run more closely to your Relay Proxy. This can be extremely useful in serverless. In AWS, the Relay Proxy exists within the same environment as our Lambda, DynamoDB or any other AWS resources our application uses.
- And of course, you want to increase startup speed in your serverless functions!
While the benefits are substantial, setting up the Relay Proxy can be somewhat intimidating as it's highly customizable adapting to a variety of data caching options, logging levels, and taking into account the helpful guidelines.
To assuage that intimidation, we're providing a completely serverless deployment that enables you to run the Relay Proxy in your AWS account. The setup script aims to be easy to read, easy to change to suit your needs, or to use as is.
Using the AWS CDK, we create an ECS Fargate Cluster with sufficient compute and memory resources to serve whatever scale you need to meet for your proxy. Backing this cluster is a DynamoDB table with single digit millisecond latency, set to scale to your workload rather than provision a fixed capacity making it suitable for virtually any scale.
To create the AWS ECS Fargate Cluster, we use a higher order AWS CDK Construct, Application Load Balanced Fargate Service, which takes care of most of the heavy lifting in configuring ECS and allows for a variety of configuration options, although it's been specced to match the resource needs of the Relay Proxy Guidelines and uses the built in defaults of the Relay Proxy to simplify configuration.
The source code for this deployment is available on GitHub. The core of the project is the 89 lines of code that define the stack. The rest is configuration around the CDK and setting environment variables to define the region, SDK keys and whether you also want to serve client side SDKs (for example, if you want to use the Relay Proxy for retrieving flag data on the front-end of your application that is also deployed to AWS).
Here are the steps to set this up:
1. Clone the GitHub repository, change directory into the project and install the project dependencies:
git clone https://github.com/halex5000/launchdarkly-relay-proxy-aws-serverless-cdk
cd launchdarkly-relay-proxy-aws-serverless-cdk
npm install2. Copy the example environment file and then edit it with your own environment variables including your LaunchDarkly SDK keys:
cp .env.example .env3. Install the AWS CLI if you don't already have it.
4. Set up your account and region to use the AWS CDK, making sure to replace the account number and region placeholders below with your own details:
npm run cdk bootstrap aws://{ACCOUNT-NUMBER}/{REGION}5. Finally, deploy the stack to AWS:
npm run cdk deployThe deployment should take about two minutes to run and it will deploy to the account and region that you configured using the credentials from your CLI. During the process, you'll be prompted to approve new roles and permissions created by this stack.
If you prefer to use CloudFormation, you can easily convert this CDK project to a cloud formation template (CFT) with the following command after completing steps one and two above:
npm run cdk synth > cloud-formation-template.yamlThis will generate a CloudFormation template and save it locally in your machine.
Once the Relay Proxy is set up, it will automatically keep flag values in sync with the DynamoDB table that the configuration creates. This means that you can use configure the LaunchDarkly SDK in your Lambda functions to use the DynamoDB table as a data store and run in daemon mode. As discussed in the prior section, daemon mode allows the SDK to retrieve values exclusively from the configured data store rather than calling LaunchDarkly. This can speed up the startup of the SDK client as well as allow for even faster flag evaluations.
Handling LaunchDarkly analytics events
LaunchDarkly's dashboard provides a lot of detail on flag usage, users and even experimentation results. Much of this data is passed to LaunchDarkly via analytics events. In order to save on performance and network requests, the LaunchDarkly SDKs will buffer these events, sending them on a configurable interval.
One of the potential complications of running LaunchDarkly within Lambda, or really in any serverless context, is that the Lambda may shut down before all pending analytics events have been sent. There are a couple of solutions for this.
Flushing events
One solution is to manually flush analytics events on every invocation of the Lambda. You can see that is just a one line addition to our handler code below.
exports.handler = async (event) => {
await client.waitForInitialization();
const apiVersion = await client.variation("my-flag", {key: "anonymous"}, "");
// flush the analytics events
await client.flush();
const response = {
statusCode: 200,
body: JSON.stringify("Hello world"),
};
return response;
};While this will work, it has also effectively eliminated the buffer entirely since all events will be flushed on every invocation, making a call to LaunchDarkly's servers in the process. This may not be the ideal solution for you, but thankfully there's another option.
Closing the client
In most cases, when the client closes, it automatically sends any pending analytics events to LaunchDarkly (note that this isn't the at the moment case in the Node SDK and a flush is still required). You can handle this using a graceful shutdown in Lambda as described here. This requires that you add an extension to your Lambda. You can use the CloudWatch Lambda Insight extension as it is built in. Here are the steps:
1. Open your Lambda function and go to the Layers section at the bottom of the page and choose "Add a layer".
2. Leave the "AWS layers" option selected and in the dropdown select "LambdaInsightsExtension" under the "AWS provided" heading and then click "Add".
Now that the extension is added, we can listen for the SIGTERM event that indicates that the Lambda is being shut down and run code at this time as shown below.
const LaunchDarkly = require("launchdarkly-node-server-sdk");
const client = LaunchDarkly.init(process.env.LAUNCHDARKLY_SDK_KEY);
exports.handler = async (event) => {
let response = {
statusCode: 200,
};
await client.waitForInitialization();
const flagValue = await client.variation("my-flag", { key: "anonymous" });
response.body = JSON.stringify(flagValue);
return response;
};
process.on('SIGTERM', async () => {
console.info('[runtime] SIGTERM received');
console.info('[runtime] cleaning up');
// flush is currently required for the Node SDK
await client.flush()
client.close();
console.info('LaunchDarkly connection closed');
console.info('[runtime] exiting');
process.exit(0)
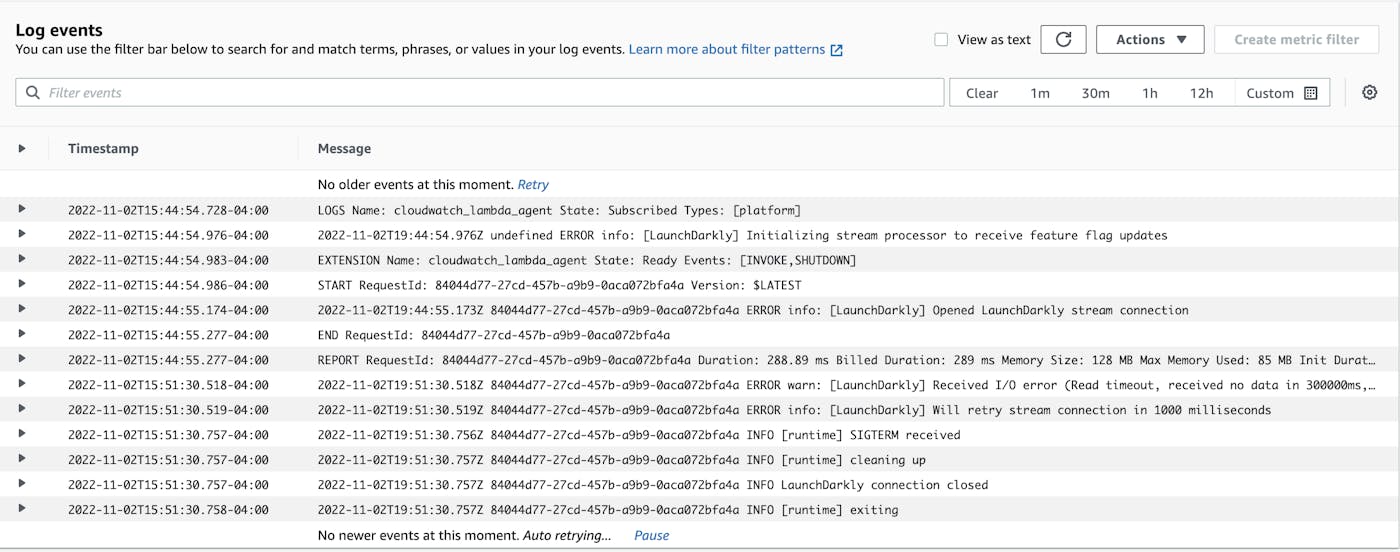
});If you'd like to see this process run, go to the "Monitor" tab in the AWS Lambda console and choose "View logs in CloudWatch." You can view the logs for a recent run of your function and see that the cleanup script was triggered (in our tests, this happened approximately six minutes after the last call of the function) as you can see with the "LaunchDarkly connection closed" log message below.
Conclusion
Hopefully this article has provided you with all of the tools you'll need to begin adding LaunchDarkly feature flags into your Lambda. However, we do have a number of additional resources that may be useful to you in your further development:
- Using LaunchDarkly in serverless environments – This guide covers high-level considerations for serverless environments and walks through creating a function to synchronize flag data into DynamoDB.
- Using LaunchDarkly in AWS Lambda – This guide covers similar ground to the above but in a more step-by-step tutorial format if you'd like to follow along.
- DynamoDB – This is the documentation page for integrating DynamoDB into LaunchDarkly's SDKs that includes code samples for all supported language SDKs.
Like what you read?
Get a demo