

Reliability of a service is a combination of availability and correctness. At LaunchDarkly, reliability is our number one priority. Over 40 billion feature flags are evaluated on the LaunchDarkly platform every single day, and our customers count on us to deliver. Learn how we did it.
When evaluating a service like LaunchDarkly, you may have questions about how that service will behave under worst-case scenarios. At LaunchDarkly, this is something we have thought about—failure and worst-case possibilities. Over the last four years, we’ve worked hard to create a service that’s incredibly robust against different kinds of failures. We’ve built LaunchDarkly to ensure that your app stays healthy, even if there are multiple failures at the same time.
LaunchDarkly SDKs: Streaming and Control
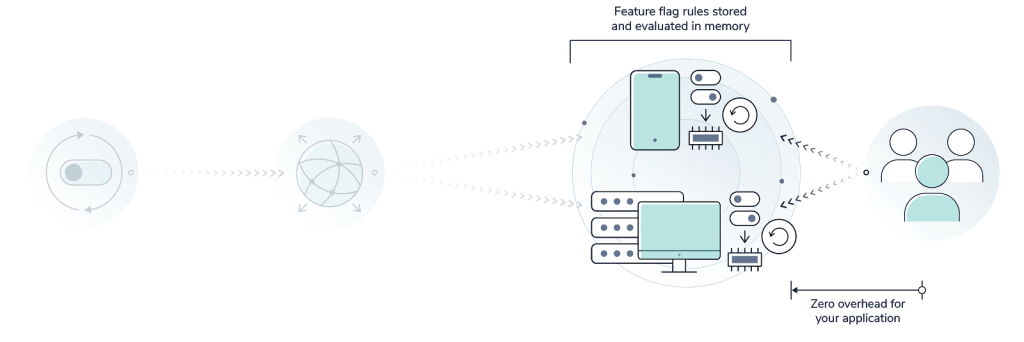
Getting started with LaunchDarkly is easy. All you have to do is create an account and add the appropriate SDKs to your server-side and client-side applications. Once the SDKs are incorporated into your product, the LaunchDarkly SDKs will fetch all the feature flags and evaluation rules automatically whenever the application starts (how updates are handled is covered below). This data remains cached locally, in your application.
There is no performance overhead when using our robust feature management service. Flags and rules are stored in the LaunchDarkly core service, which is deployed across multiple AWS availability zones. Flags and rules are also cached and updated across Fastly’s worldwide CDN every time you make a change. Because flags and evaluation rules are cached locally, your application actually evaluates all requests without having to connect to the LaunchDarkly service.
In the case your application cannot contact LaunchDarkly (whether due to a misconfiguration, a Fastly outage, or even an AWS outage) your application will continue to perform exactly as your users expect using the locally cached values. For another level of safety, every LaunchDarkly flag is also configured in your code with a default value that can serve as a fallback in the unlikely event that the SDK is not able to initialize.
LaunchDarkly uses streaming connections to proactively push out changes to flag or evaluation rules to all connected LaunchDarkly SDKs. Push-based delivery is critical for environments that are built with microservice architectures, globally distributed resources, or are using operational flags like kill switches (turn features, or code, off during roll-out), circuit-breakers (long-term flags that can be turn-off features, or code, to protect your service) or rate-limit valves (long-term controls to adjust limits).
Distributing these updates to services needs to be reliable and fast. If you discover that you have accidentally released some buggy code into your application, you can use a LaunchDarkly flag as a kill switch to turn off that buggy code. LaunchDarkly’s streaming architecture ensures that the kill signal will make it to your application, no matter where in the world the application is running, nearly instantly. As we say, a slow kill switch isn’t a kill switch at all.
The LD-Relay
For those customers that have the need for another layer of redundancy on top of the four layers provided by our core service (multiple AWS availability zones, the Fastly CDN, local caching, and default values), we also offer the LaunchDarkly relay proxy (formally known as LD-relay). LD-relay is a small application in a Docker container that can be deployed in your own environment, either in the cloud of your choice or on premise in your datacenter(s).
We also provide an optional Redis cache within the LD-relay that can be used to store flag evaluation rules. If you’ve configured the LD-relay, new LaunchDarkly SDKs inside your application will pull the required flag and evaluation rules from the Redis cache, which allows network calls to stay within a localized network segment.
In this case, LD-relay is yet another layer of redundancy in the case of an outage of both Fastly and AWS. This is useful in supporting the case where flags are required to function even when the majority of the internet is not available.
With the LD-relay service you are increasing the redundancy, reducing initialization time, decreasing external network traffic for you server application. You can learn more about the LD-relay here.
Why Streaming
Operations teams need to think about not only availability, but also correctness. As mentioned above, correctness is critical for services constructed from microservices and/or services that are distributed across multiple availability zones, data centers, or even distributed globally. When incorporating a third-party service into an application, the best engineering and operations teams consider and model all the possible failure modes. After all, a distributed system can only be as fault-tolerant as the least stable service component in the system.

As we first started work on LaunchDarkly in 2014, we started with a polling architecture. The original rationale behind architecting LaunchDarkly to use a polling architecture was to provide a lightweight way to have endpoints (applications or services) check for themselves to make sure all flags and evaluation rules were up to date. However, as we started scaling LaunchDarkly, we quickly realized that polling for changes was not sufficient to deliver the performance and reliability our customers demanded.
When operating a distributed application, either a system of microservices or a geographically distributed system, it’s important that all instances are configured with the same set of rules. Consider the kill switch example above—if you need to turn something off for safety, you need to turn it off everywhere, right now.
And when using feature flags to manage your application, you need changes to propagate to each of your services as quickly as possible. You need to deliver changes to all of your services in milliseconds, not the minutes or hours required to wait for the next poll. If the rules for your service fall out of sync between instances, your service could begin to degrade and could even cause a catastrophic outage. Imagine a financial transaction application or a messaging service—inconsistent application of rules could result in data loss or total system failure.
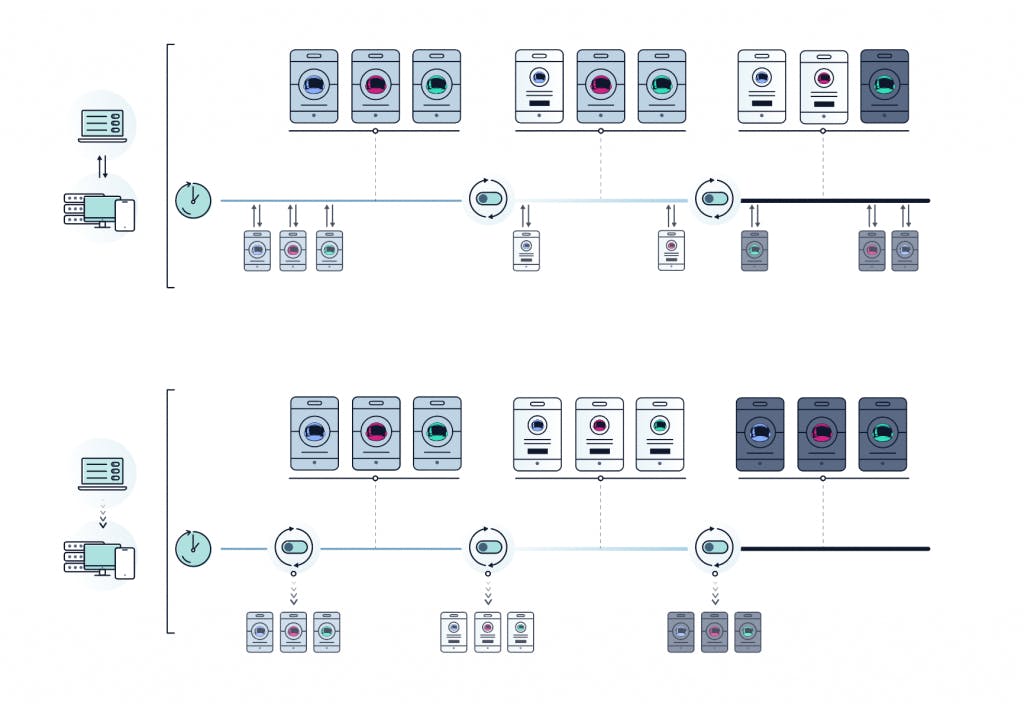
“But, can’t I just poll more often?” This was something we considered and quickly dismissed. First, polling becomes very expensive very quickly. As you change your polling to go from once an hour to once a minute, your external network traffic goes up sixty-fold. If you were to poll once a second, your external network traffic would be more than 3,000 times greater. Second, the more often you poll, the more you introduce network and compute overhead on your service. In the case of mobile, this increased overhead from your polling can dramatically impact battery performance.
The costs of network traffic from polling every few seconds from a few servers might seem reasonable, but when you have hundreds or thousands of servers making polling requests every single minute the bandwidth cost can outpace the value of your feature flag system. By making a streaming connection to LaunchDarkly, your application only communicates with the LaunchDarkly service when changes occur and your application receives those changes as soon as they are made.
LaunchDarkly’s feature management platform empowers you to deliver value faster. By minimizing the risks involved with releases, your team is free to focus on delivering value to your end users.


















