
It’s a familiar story: an ambitious company starts out with a homegrown solution to perform a specific task. As business scales, complexities arise, and there's a gradual realization that the original homebuilt tool is not going to work out in the long run.
For Rick Riensche, a senior software engineer, the migration from a homegrown feature management solution to a vendor tool was a little different. His team switched to LaunchDarkly following the acquisition of his former company, PlanGrid, by his current organization, Autodesk.
At PlanGrid, Riensche was using a homebuilt solution called Flipper. In this talk from our user conference, Galaxy, Riensche explains the process as his team migrated from Flipper to LaunchDarkly, and dispenses advice for those considering making the jump.
Transcript:
Hello, I'm Rick Riensche, a senior software engineer at Autodesk. I joined PlanGrid in February of 2012, the same month that PlanGrid was acquired by Autodesk.
As part of that transition, we migrated from a homegrown feature flag system to LaunchDarkly, which was already being used as the preferred feature flag platform within Autodesk. Uh, today I'll be talking about what that migration looked like.
In this first section I'll give you a very brief overview of the migration. Uh, I'm gonna skim over this pretty quick. So for a slightly less brief version I'll refer you to the blog post that you can find at this link.

Our homegrown Flipper system had some definite pros and cons. Uh, on the plus side it was very simple to use and featured a Slack application that made it easy for developers as well as for our sales and support staff to control flags via Slack.
On the negative side, that Slack app was the only way outside of the actual API to work with our flags. Without any other user interface, as our list of flags grew, it became increasingly difficult to manage them. That also effectively masked certain issues, uh, for example, erroneous flags created because someone typed a flag name with the wrong casing. Last but not least, Flipper, like any homegrown app, required maintenance, which meant engineers spending time working on something other than the software products we're trying to sell.
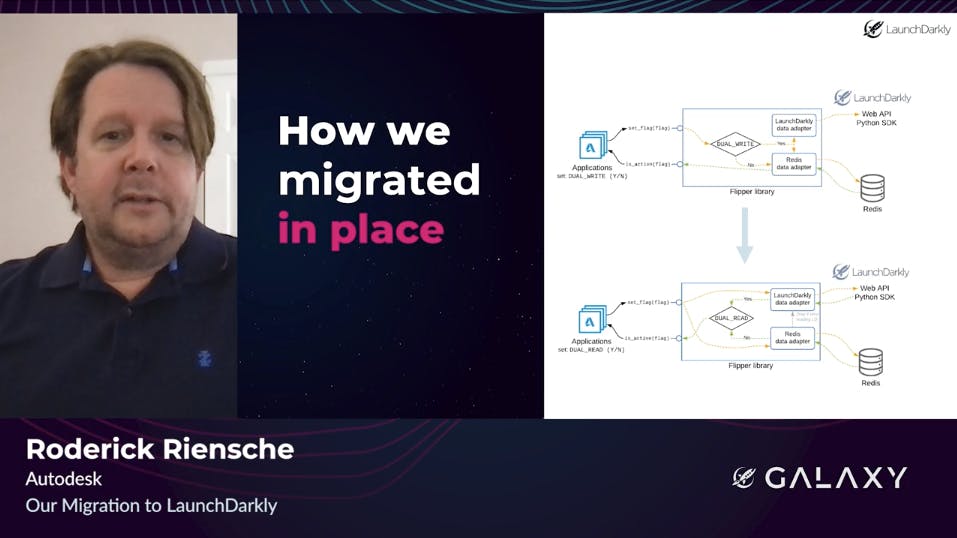
For an orderly migration, we introduced some data adapter shims so that our Flipper library could interact with its original Redis data store as well as with LaunchDarkly. We ran in a dual write mode for a while during which all reads still hit the Redis store, but writes went to both. We then augmented with dual read so that in addition to dual writing, the library would read LaunchDarkly first and then fall back to Redis if something went wrong. Notably, that almost never happened and usually was the result of a programming error on our end. So kudos to LaunchDarkly for that. The Last step, of course, not pictured here was to disable dual writes and dual reads and use LaunchDarkly exclusively.
In addition to getting to use the features of LaunchDarkly and no longer having to maintain our homegrown system, we reaped some pretty impressive performance awards. Uh, this is what happened to our biggest and busiest service when we switched to reading primarily from LaunchDarkly. Overall, response times dropped, uh, dramatically and became drastically less sensitive to load when we eliminated these million of Redis calls that were happening per minute in the old system.
Okay. So now you know roughly what we did and when we got out of it. Uh, I'll spend the rest of my time talking about how we did it and what we learned.

The, uh, key pieces to making our migration smooth were definitely our data adapter shims. Uh, the first of those was the adapter for write operations. For this shim, we used the LaunchDarkly rest API with one time post operations to create flags and patch operations to update them whenever targeting rules were changed.
Uh, before being pressed into service for ordinary use, this data adapter was used for our initial copy of flag data from Redis to LuanchDarkly. Uh, note that initially all flag manipulation was still done using our Slack application and it was important that users not start changing flags within the LaunchDarkly UI until we told them it was okay, uh, because we were still, at that point, reading data from our legacy data store.
Once we had our data all cloned into LaunchDarkly with write operations set to send data there, as well as to our legacy data store, we could start shimming those read operations. For this we used the Python SDK because our, uh, vast majority of our services are written in Python. For most basic reads, this equated to a call to the LaunchDarkly clients variation method. Uh, we did have a couple of cases in which we used the all flags state method. Uh, at least one of those was a case where we shouldn't have used it and I'll talk more about why that is in a couple minutes here.

So that brings us to, uh, an important portion of the talk. Uh, we, of course, faced some challenges in our migration. Most of them I would probably categorize as user re-education, uh, as they were less technical challenges and more cases of unfamiliarity with a new system after years of using one, uh, that had some of its own quirks. Uh, your own migration might not look exactly like ours, uh, but hopefully these will give you ideas of the types of things to look out for.
First up is rate limiting. While the SDK doesn't need any kind of rate limiting because it's generally not making a lot of outbound requests, the rest API, like pretty much every rest API out there, does. For ordinary operations this isn't really a problem for us, but it did mean we had to throttle our migration scripts.

Uh, this could also be a factor if you were doing, uh, something like dynamic updates of flags, uh, code driven that's causing lots of changes to targeting rules. Um, if you are to run into a case like that in day to day use I would suspect it's time to reevaluate that approach that led you there. And that would also be a really good time to involve the folks at LaunchDarkly, uh, because they will help you figure out, uh, not only the technical how to use the system, uh, but the operational, uh, best practices.
Uh, so I mentioned earlier that we made limited use of the "all_flags_state" method. Uh, one ... This was actually one initial point of confusion, uh, for some of our developers. Uh, it was an expectation that we would start to see evaluations on pretty much every flag when we looked at the insights graph in LaunchDarkly, uh, not realizing that all flag requests don't contribute to that graph.
Uh, of course, once we took a closer look at what was happening, it made sense, uh, because requests for all flags would tend to pollute the metrics if what I really wanted to know is how often is someone requesting feature X. Uh, so for that reason the insights graph ignores those bulk requests that aren't targeted to a specific flag.
Uh, it's also worth noting that relative to the variation method all flags state was a fairly expensive operation, especially because we had a lot of flags. Our general position on this is now that we avoid using this method in any code that is part of a user impacting work flow.

Uh, on this one we had a combination of two significant differences in behavior between our legacy Flipper system and LaunchDarkly. Uh, in our old system we had to explicitly create each flag in each of dev, test, and production environments. Uh, Flipper also did not have a concept of targeting being turned on or off. Uh, if targets were present, targeting was on.
Uh, when we initially migrated our flags the default value if targeting was off ended up being true on all of them. Uh, so combined with the fact that flags get created in all three environments at once this caused some concern, uh, do to a misconception that LaunchDarkly was going to, uh, always create flags defaulting to true until we went and turned them off.
Um, it turns out this was actually an avoidable side effect of a developer not explicitly specifying defaults and not understanding how LaunchDarkly's default ordering of variations worked. Uh, when you think about it in terms of array indexes, it's not hard to see how this mistake was made, uh, because variation zero, uh, by default was true and variation one, which to a programmer says true, was false. Uh, the lesson here, of course, is to be explicit. When creating a flag from code specify your variations and specify exactly what you want the default to be.
Uh, this is an important lesson, uh, that, uh, was, was quite a surprise to us, uh, but you never ever, ever want to send random keys without marking them as anonymous. Uh, again, this was ... Uh, education was key on this.

LaunchDarkly generally assumes that the key for a flag evaluation is a user ID. Uh, we did not have that assumption in our previous system, so we had flags, um ... When we had flags that weren't user specific there were places where developers had just shoved random garbage into the key field because they knew it was going to be ignored.
Uh, this ended up wildly inflating our monthly active users metric, uh, when we switched to LaunchDarkly because it was seeing, uh, uh, a random UID as a unique user. Um, thankfully the team that we work with at LaunchDarkly was very helpful, uh, not only in tracking down what was happening, but also in giving us some leeway to straighten it out despite us being well over our license usage at that point.

Lastly, we did have a couple of cases where we hit some resource constraints. Uh, while the LaunchDarkly client didn't have a particularly large footprint we did start with a fairly messy database with several hundred flags all of which we'd migrated over. Uh, those got pulled into local memory along with all the rules needed to evaluate them. So on a couple of applications servers where we had aggressive resource limitations, we ended up bumping up against those and needing to allocate more memory.
Uh, the other key lesson, of course, that that reinforces is this was evidence that our previous system really did not encourage good flag hygiene, uh, because we shouldn't have had several hundred active feature flags in the first place. Uh, by my estimate roughly half of those flags were old. Uh, no longer in use. Should've been removed, but since there was nothing showing people that we had these old flags they just sat there, uh, endlessly.
All told, uh, our migration was a significant challenge, uh, but ultimately we were able to run it smoothly, uh, with zero downtime, and, um, came out the other end with a more functional system that is more performant. Uh, so really, uh, a win on all counts. Uh, if you find yourself wondering if you should consider a similar migration, I could highly encourage you to take a good hard look and to engage with the folks at LaunchDarkly, and, uh, seek some advice.
Thank you for watching my talk. And I look forward to answering any questions.
From more LaunchDarkly tips, tricks, and advice check out the rest of the talks from Galaxy.
















