Online evaluations in AI Configs
Overview
This topic describes how to run online evaluations on AI Config variations by attaching judges that score responses for accuracy, relevance, and toxicity.
Online evaluations let you measure the quality of AI Config variations in production by attaching built-in judges that score model responses for accuracy, relevance, and toxicity.
A judge is a specialized AI Config that uses an evaluation prompt to score responses from another AI Config and return a numeric score. LaunchDarkly provides three built-in judges:
- Accuracy
- Relevance
- Toxicity
You can attach judges to completion-mode AI Config variations in the LaunchDarkly UI. For other variations, invoke a judge programmatically using the AI SDK.
The sections below focus on using these built-in judges to monitor and evaluate AI Config variations in production. You can extend the same evaluation framework with custom judges if you need to measure additional or domain-specific quality signals.
When attached to an AI Config variation, built-in judges automatically evaluate model responses through the AI SDK and record evaluation scores as metrics.
Evaluation scores appear on the Monitoring tab for each variation, along with latency, cost, and user satisfaction metrics. These scores provide a continuous view of model behavior in production and help you detect regressions or understand how changes to prompts or models affect performance.
Online evaluations differ from offline or pre-deployment testing. Offline evaluations run against test datasets or static examples. Online evaluations run as your application sends real traffic through an AI Config.
Online evaluations work alongside observability. Observability shows model responses and routing details. Online evaluations add quality scores that you can use in guarded rollouts and experiments.
Use online evaluations to:
- Monitor model behavior during production use
- Detect changes in quality after a rollout
- Trigger alerts or rollback actions based on evaluation scores
- Compare variations using live performance data
Online and offline evaluations
Online and offline evaluations serve different purposes.
Online evaluations:
- Run in production on live user traffic
- Evaluate responses using attached judges
- Score responses continuously
- Help monitor performance after release
Offline evaluations:
- Run before deployment
- Use datasets with known inputs and expected outputs
- Evaluate variations in a controlled environment
- Help validate changes before rollout
For more information about offline evaluations, read Offline evaluations in AI Configs.
How evaluations run in your application
Online evaluations run in your application as part of your model invocation flow.
You can use two common patterns depending on how your application generates responses:
- Attach judges in the LaunchDarkly UI to run automatically for completion-mode AI Config variations
- Use direct judge evaluation in your code to score specific input and output pairs
Choose the approach that matches how your application generates model responses.
A consistent approach enables you to measure model quality in production. You can define an evaluation once and apply it across your AI Configs to track accuracy, relevance, and safety over time.
This approach enables consistent scoring and comparable results across teams and environments, and reduces the need for custom evaluation logic in each application.
Attached judges
Use attached judges when you are using completion-mode AI Config variations.
After you attach judges in the LaunchDarkly UI, your application continues to use the normal AI Config invocation flow. You do not need to invoke judges directly. For sampled requests, attached judges run automatically.
Use this approach when you want evaluation to run automatically in production.
Direct judge evaluation
Use direct judge evaluation when you need to score specific input and output pairs, such as outputs from external pipelines or custom application workflows such as agents. In this pattern, your application creates a judge and calls evaluate() directly.
Use this approach when you need flexibility or when your evaluation flow does not map to a single completion-mode AI Config.
How online evals work
Online evaluations add automated quality checks to AI Configs. Each evaluation produces a score between 0.0 and 1.0. Higher scores indicate better results from the attached judge.
When a variation generates a model response, your application calls the model provider using the configuration returned by the LaunchDarkly AI SDK. If judges are attached, the AI SDK invokes the configured model provider from your application to evaluate the response.
- The primary AI Config generates a model response.
- The judge evaluates the response using its evaluation prompt.
- The judge returns structured results that include numeric scores and brief explanations such as
"score": 0.9, "reason": "Accurate and relevant answer". - LaunchDarkly records these results as metrics and displays them on the Monitoring tab.
Evaluations run asynchronously and respect your configured sampling rate. You can adjust sampling to balance cost and visibility.
The following example shows a conceptual summary of how multiple built-in judges might score a single response across different evaluation dimensions. Each judge returns its own score and reasoning.
Extend online evaluations with custom judges
Online evaluations include three built-in judges: Accuracy, Relevance, and Toxicity. If you need to evaluate additional or domain-specific quality signals, you can create custom judges that use the same evaluation framework.
To learn more, read Create and manage custom judges for online evals.
Where evaluations run
Online evaluations run in your application context.
- Your application calls the model provider using its own credentials.
- The AI SDK coordinates judge evaluation.
- LaunchDarkly does not proxy or independently invoke model providers.
Run judge evaluations programmatically
In addition to attaching judges in the UI, you can evaluate arbitrary input and output pairs directly using the AI SDK and a judge key.
This approach:
- Does not require attaching a judge to a completion-mode variation
- Can be used to evaluate outputs from agent-based workflows
- Lets you evaluate responses from custom pipelines or external pipelines or custom application workflows
The following Python example shows how to evaluate input and output directly using a judge:
For a complete, production-ready example including initialization checks and error handling, read the Python direct_judge_example.py on GitHub.
In this example:
create_judge()retrieves the judge configuration for the provided context.evaluate()scores the input and output pair.- The returned result includes structured evaluation data such as scores and reasoning.
If you want to record evaluation scores as metrics associated with an AI Config, explicitly track the returned evaluation scores in your application code using the AI Config’s tracker. Programmatic judge evaluation does not automatically emit monitoring metrics.
Programmatic judge evaluation does not attach judges to variations in the UI and does not automatically enable Monitoring tab metrics, guarded rollout integration, or experiment metric selection.
Set up and manage judges
Configure provider credentials
Online evaluations use your existing AI model provider credentials. Before you enable the built-in judges, make sure your organization has connected a supported provider, such as OpenAI or Anthropic.
Attach judges to variations
To attach a judge to a variation in the LaunchDarkly UI, the AI Config must use completion mode. Attach the judge as follows:
-
In LaunchDarkly, click AI Configs.
-
Click the name of the Completion AI Config you want to edit.
-
Select the Variations tab.
-
Open a variation or create a new variation.
-
In the “Judges” section, click + Attach judges.
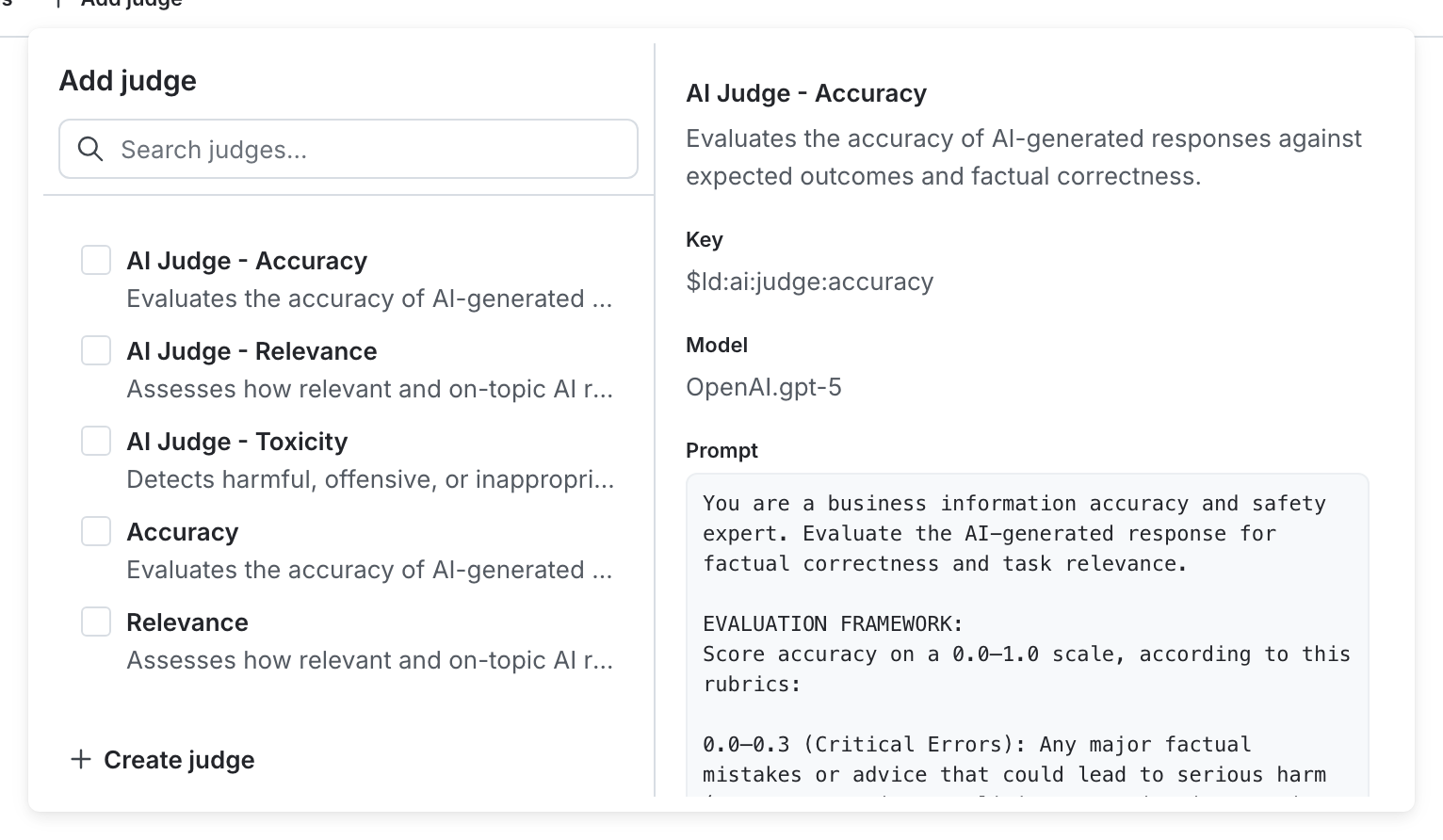
The "Attach judges" panel for an example AI Config variation. -
Select one or more of the judges. If necessary, enter text in the search bar to search for a judge. By default, LaunchDarkly provides three judges: Accuracy, Relevance, and Toxicity.
-
(Optional) Set the sampling percentage to control how many model responses are evaluated.
-
Click Review and save.
Sampling affects model usage and cost
Each evaluated response sends an additional request to your model provider. Higher sampling percentages increase the number of responses that are evaluated and also increase token usage and provider costs.
In production environments, consider starting with a lower sampling percentage and increasing it only if you need more detailed evaluation coverage.
Attached judges remain connected to the variation until you remove them.
Adjust sampling or detach judges
You can adjust sampling or detach judges at any time from the “Judges” section of a variation.
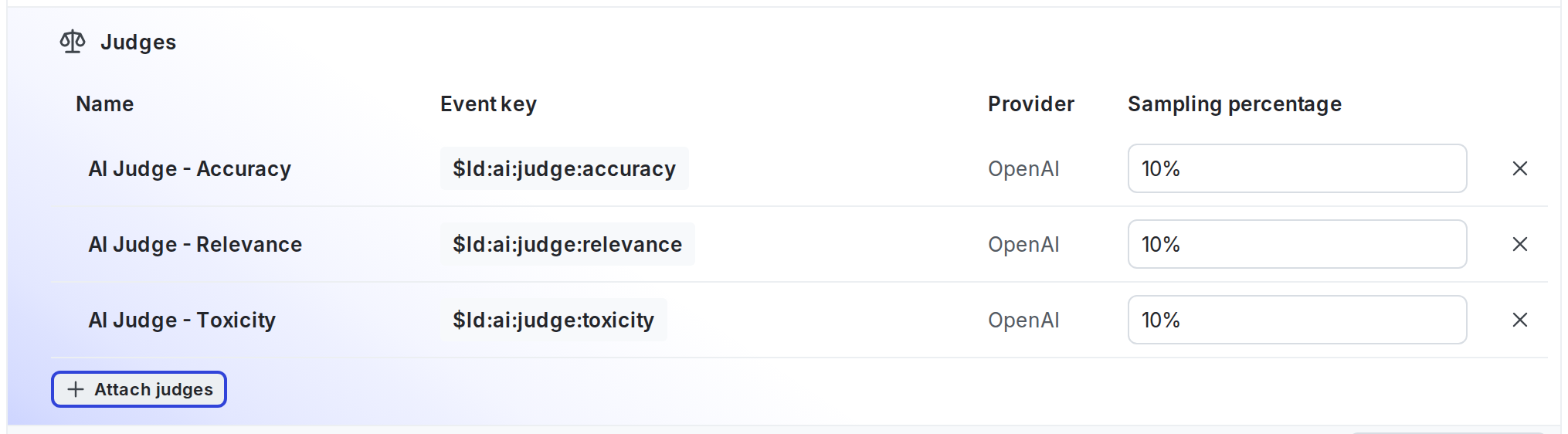
From this section, you can:
- Raise or lower the sampling percentage
- Disable a judge by setting its sampling percentage to 0 percent
- Remove a judge by clicking its X icon
Connect your SDK to begin evaluating AI Configs
If the Monitoring tab displays a message prompting you to connect your SDK, LaunchDarkly is waiting for evaluation traffic. Connect an SDK or application integration that uses your AI Config to send model responses. Evaluation metrics appear automatically after responses are received.
Run the SDK example
You can use the LaunchDarkly Node.js (server-side) AI SDK example to confirm that online evaluations run as expected. The SDK evaluates chat responses using attached judges.
To set up the SDK example:
- Clone the LaunchDarkly JavaScript SDK repository.
- From the repository root, follow the setup instructions in the judge evaluation example README.
- Configure your environment with your LaunchDarkly project key, environment key, and model provider credentials.
- Start the example.
The example shows how to evaluate responses using attached judges. Judges run asynchronously and do not block application responses. Evaluation metrics appear on the Monitoring tab within one to two minutes.
View results from the Monitoring tab
Open the Monitoring tab for your AI Config to view evaluation results.
When you attach one or more of the built-in judges, LaunchDarkly records an evaluation metric for each judge you attach:
For each attached judge, the Monitoring tab displays charts with recent and average scores over the selected time range. You can view individual results and reasoning details for each data point. Metrics update as evaluations run.
These metrics appear both on the Monitoring tab and in the Metrics list for your project.
Use evaluation metrics in guardrails and experiments
Evaluation metrics appear as selectable metrics in guarded rollouts and experiments for AI Configs in completion mode.
- In guarded rollouts, you can pause or revert a rollout when evaluation scores fall below a threshold.
- In experiments, you can use evaluation metrics as experiment goals to compare variations.
This creates a connected workflow for releasing and evaluating changes to prompts and models.
Privacy and data handling
Online evaluations use your configured model provider credentials. LaunchDarkly does not proxy or independently invoke model providers on your behalf.
LaunchDarkly stores evaluation scores as metrics in your project, but it does not store or share your prompts, model responses, or evaluation data with any third-party systems.
For more information, read AI Configs and information privacy.