

This awe-inspiring scene from the legendary film, Raiders of the Lost Ark, is undeniably iconic. If you haven't seen this film, picture Indiana Jones venturing deep into a mysterious tomb and looking to secure the golden idol.
Indy knows he needs to do it without triggering the traps within the tomb, and he must execute a lightning-fast maneuver to replace the precious artifact with an equal weight of sand, ensuring seamless preservation of the delicate balance.
He triumphantly starts to walk away, with the idol in his hands, before all the traps suddenly set off, leaving him with no option but to outrun a giant boulder hurtling towards him.

In the realm of technology, we can draw a striking parallel to this adrenaline-inducing scene—database migrations can invoke comparable sensations.
You carefully prepare ahead of time, planning precisely what, and when, things need to happen—and then make the cutover in a single, smooth movement—only to have everything fall apart around you, leaving you scrambling to escape to the safety of your backups. (You do have backups, right?)
But it doesn't need to be this way
Planning a migration customers won’t notice
At LaunchDarkly, we've developed three best practices that have allowed us to complete migrations with zero downtime and no scrambling.
As a fast growing business, our technology needs have changed over time. To improve resilience and availability, we wanted a region-aware, distributed datastore that supported serializable isolation. After a period of evaluating solutions, we choose CockroachDB. We then embarked on a gradual migration from our previous sources of truth, MongoDB and PostgreSQL, to CockroachDB.
Our platform is mission critical for our customers, so we don't have the luxury of taking downtime maintenance windows for changes. With this in mind, our guiding principle throughout this migration was that our customers should never notice any changes.
We also decided to take a piecemeal approach of changing one thing at a time. This meant doing an initial lift and shift to move from MongoDB to CockroachDB, while retaining our data in a predominantly document-oriented data model. After this, we could incrementally migrate the data representation into a relational data model.
From the outset, we knew we wanted to build confidence in the read and write code paths we were developing for CockroachDB, ensuring they would work as expected when handling customer data. But we also knew that automated testing and a typical CI/CD pipeline can only really prove what you thought to test ahead of time.
Leveraging production traffic
This brings us to the first best practice: leverage production traffic. Using LaunchDarkly feature flags allows applications to make informed behavior decisions on every request and, as feature flags can be updated without deploying code changes, allows for dynamically adjusting behaviors at any time.
In the early stages of the migration, before moving any data, we used feature flags to conditionally wrap our new code that read and wrote to CockroachDB, while still serving a request in our production environment using MongoDB. While we grew our familiarity and confidence operating CockroachDB at the scale we required, we treated these reads and writes as throw-away, using production traffic to generate shadow requests. With feature flag percentage rollouts, we also dynamically dialed the volume of shadow requests generated from live traffic up and down.
Once it was time to start moving data, we used the same feature flag that conditionally controlled reading and writing from CockroachDB, to replicate writes between new and old data stores by writing to both when flag evaluation directed the application to do so. This dual writing was our mechanism of maintaining data consistency between the two data stores.
Another benefit of this approach was that our application, as it was now reading from both data stores at the same time for the same logical query, was well-placed to compare the returned results from both systems, allowing us to verify data consistency on a request-by-request basis, surfacing any differences encountered.
Making things gradual
With these newly-developed capabilities to issue shadow requests, replicate data, and continually verify data consistency, we next wanted to formalize our migration process. This brings us to best practice number two: make migrations gradual (and instantly reversible without deploying code changes).
To add confidence-building steps that reduced risk and carve out safe fallback positions, we developed a 6-stage migration process. This general process is for migrating stateful data for a new and old system, as it considers which system(s) to read from, and which to write to, along with which read result should be considered authoritative for each stage of the migration.
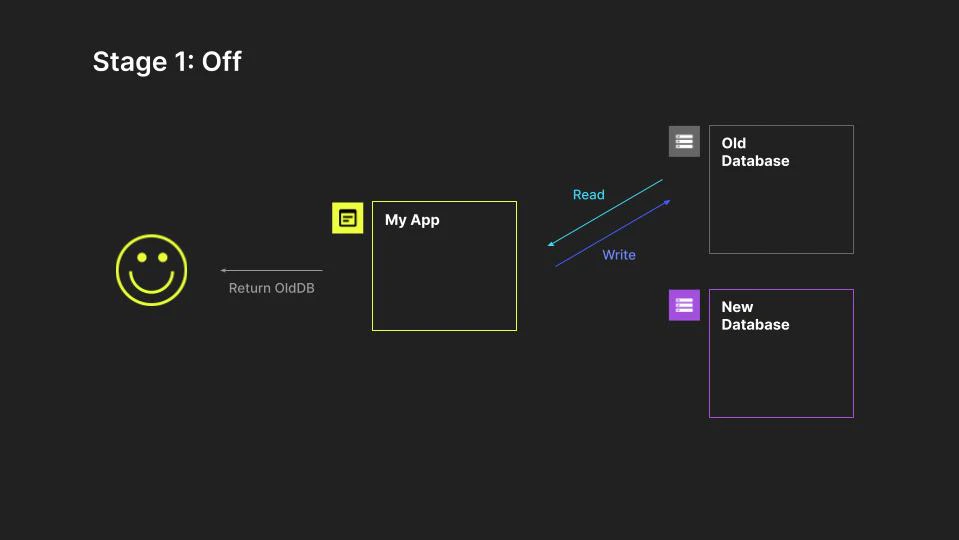
At this point, the migration has yet to start, so it's off. Only the old system is read from, and written to, so only the old system can be considered authoritative.
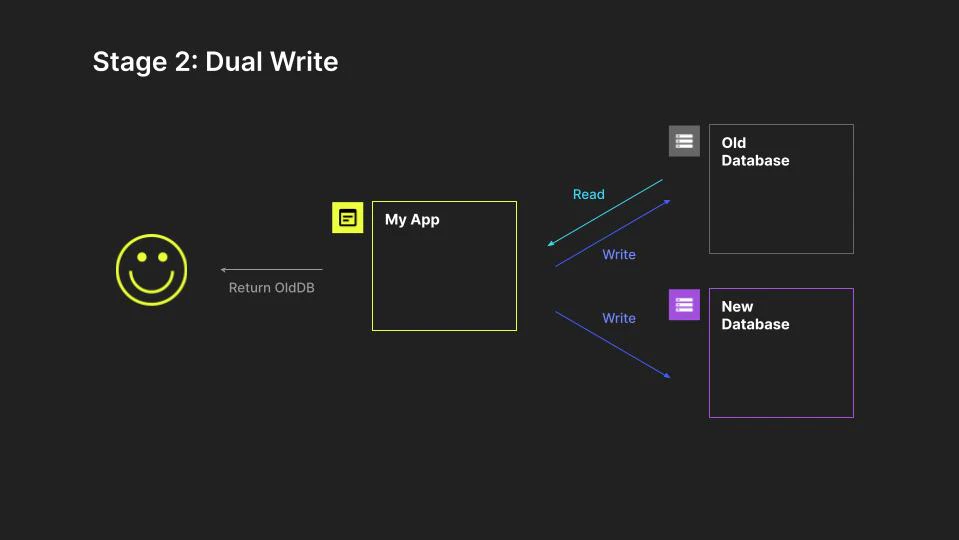
Next, we continue reading from the old, but now the application dual writes to both new and old, while still returning the old result. Now that the application is actively maintaining data consistency with dual writes, and we can also backfill the new system with all the data from the old system, knowing the two will remain in sync when future writes occur.
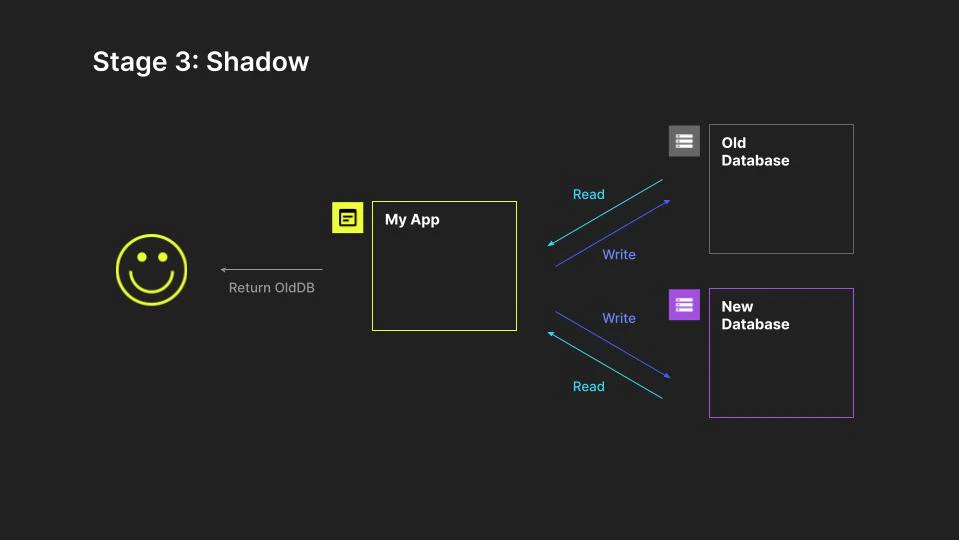
At this point, there's now value in the application issuing shadow read requests to the new system, as this allows us to verify the data consistency of the two systems for the same query. At this point the old system is still considered authoritative and is returned. If verification issues come up with the new system, they can be addressed and data can be backfilled as needed.
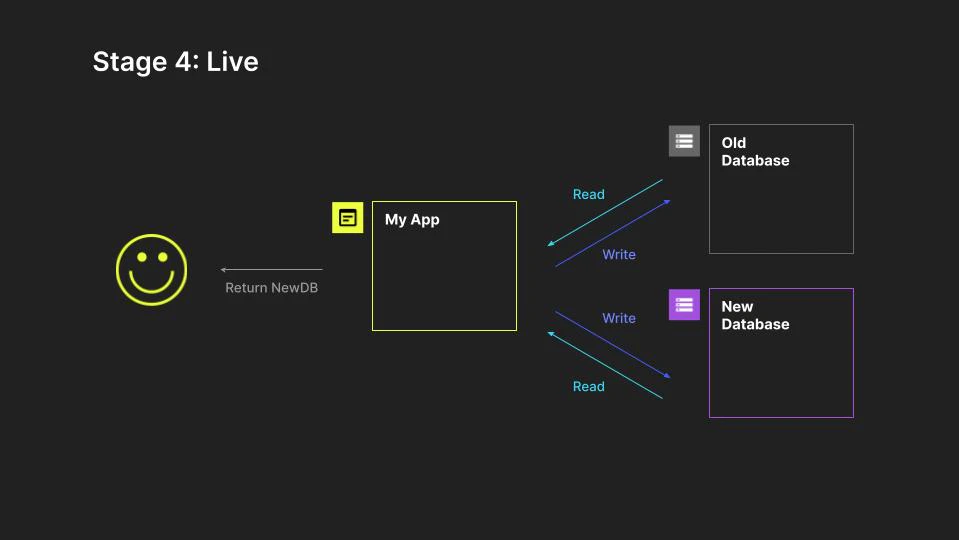
Later, once we have sufficient confidence that the application can maintain data consistency in the new system, we start returning from the new system as authoritative instead. At this point we consider the new system live, but should anything go wrong we could still switch back to the old system as authoritative.
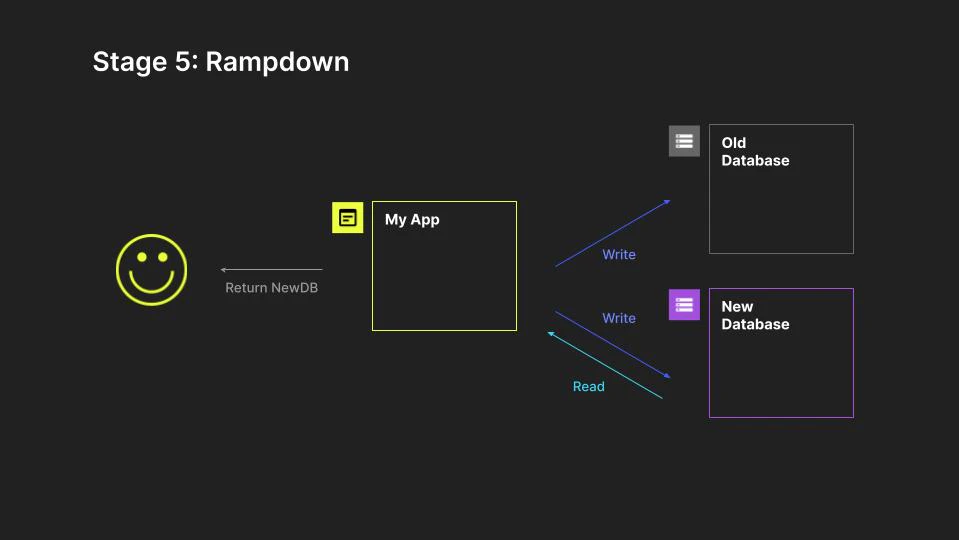
As we develop full confidence in the new system, we can stop reading from the old system, while still continuing to write to both while we prepare to fully commit to the new system.
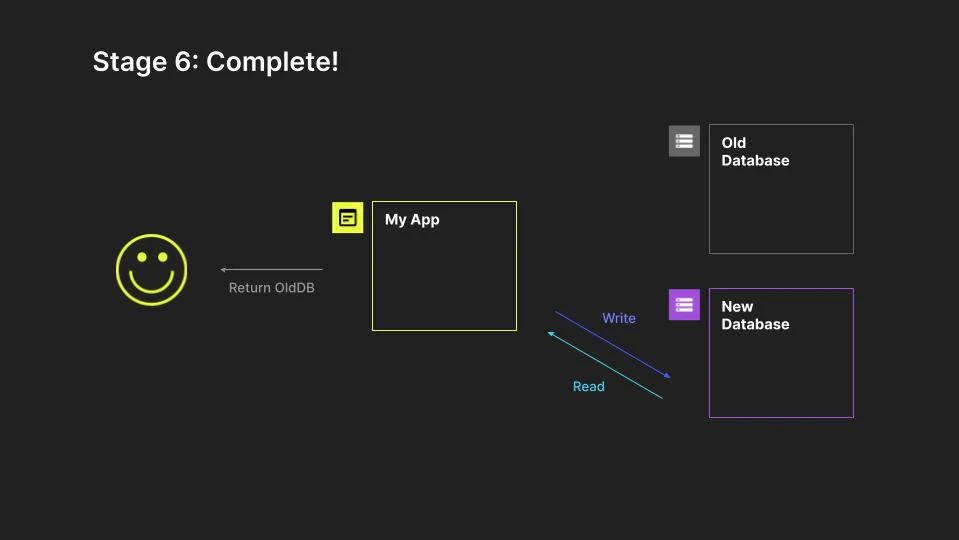
Finally, we switch to read and write entirely with the new system. At this point, the application doesn't need the old system and it can be decommissioned.
Using LaunchDarkly feature flags and percentage rollouts to manage this 6-stage process meant we could gradually shift traffic between each stage, one stage at a time. If something unexpected occurred, we could fallback to a prior, known-safe stage while investigating. This capability gave us high confidence and allowed us to move faster, knowing we were not risking our data at any point until we decided to fully commit to the new system.
Splitting migrations into cohorts
Our 6-stage process is only one dimension of our migration. And this brings us to our last best practice: splitting traffic into cohorts.
We used flag targeting rules to split our traffic into a number of different cohorts. We first targeted some test accounts, which allowed us to test the migration with low-risk data. We created another cohort by targeting internal users, which allowed us to dogfood the migration process ourselves with our own data—before moving any customer data. As we moved customer cohorts through the initial stages of the migration, we further leveraged production traffic, using customer traffic from those cohorts to generate shadow requests in production to validate data consistency in CockroachDB.
As the migration progressed, we also found ourselves, at times, carving hold-out cohorts of challenging traffic. This allowed most of the cohorts to continue through the migration process while we simultaneously optimized queries to support our most demanding workloads within the carve-out cohorts. This was another powerful capability as it allowed the majority of the migration to proceed, rather than halting everything when we encountered an outlier.
Putting It Together
Bringing that all together we have the three best practices we developed at LaunchDarkly while working on this migration.
First, take advantage of production traffic to make shadow requests to the new system and use feature flags in your application to control write replication between the two systems. Use your application's unique position to verify data consistency by reading from both databases with the same logical query and compare the results.
Secondly, make your migration gradual by adding confidence-building steps to reduce risk and carve out safe fallback positions should issues arise.
And finally, split your traffic into migration cohorts. Move each cohort independently through migration and move the least risky cohorts first. Lastly, create hold-out cohorts for challenging traffic so the remainder of the migration can continue progressing.
We’ve found that using feature flags to manage our complex database migrations allowed us to go faster—or slow down when necessary—while maintaining high confidence in our database migration.
Learn more about the ways LaunchDarkly feature flags support seamless technology migrations.


















