

We all know what an audit log is...right? We think of the audit log as a chronological list of changes in a system. Martin Fowler defines it as:
“...the simplest, yet also one of the most effective forms of tracking temporal information. The idea is that any time something significant happens you write some record indicating what happened and when it happened.”¹
While event logs will tell you that a thing happened, the audit log should also tell you what happened, when it happened, and who set that event into motion.
A Practice, Not a Product
I'm sure you can appreciate why having this level of detail is important. By understanding what, when, and who impacted an event that occurred in your system, you now have a timeline of how things have been changed, can infer why the change happened, and decide what your next steps should be.
A great example of this is with security and compliance. It's important to show a record of what transpired and have accountability. But the audit log is a practice, not a product. You have to think about how you track and record this information so that you can access it later.
One of the things that distinguishes LaunchDarkly from homegrown feature flagging systems, is that often people who build their own don't take the time to build an audit log. This is usually because an audit log requires a role based auth system that will allow you to track accountability. A standard database doesn't inherently have a way to track accountability, you must add that to the schema. LaunchDarkly, on the other hand, enforces this by requiring all users to authenticate into the system, even API access is authenticated and scopes through the use of personal access tokens.
Let's Play ‘What-If?'
Your team has a new feature, and you're releasing it to your end users. You've decided to do a percentage rollout because you're also testing in production—you want to be sure this new feature isn't going to have a negative impact on any customers. You've also explicitly excluded some specific users. You know they're in a quiet period, and this new feature would not be beneficial to them right now. Maybe you'll roll this out to them in two weeks when they're ready.
Just when you think the rollout is going smoothly, you get a call from a customer. They've reached out to support wanting to know what's going on. “There's a new feature and it's impacting our performance!” How do you find out what happened?
What if you didn't have an audit log? Well this process would look very different. This would be a lengthy process in which you (and your team) must look through everything to try and figure out what happened. What flag impacted the change? What was deleted or changed? Do you even have a dashboard to help you review this information? Who made the change—was it on the engineering side or the product team? How many people in support, product, and engineering do you need to talk to to sort out what could be the cause of this error? And keep in mind, you're probably relying on people's memory of what they might have done with 100s of flags… This is not an easy task!
The More You Know
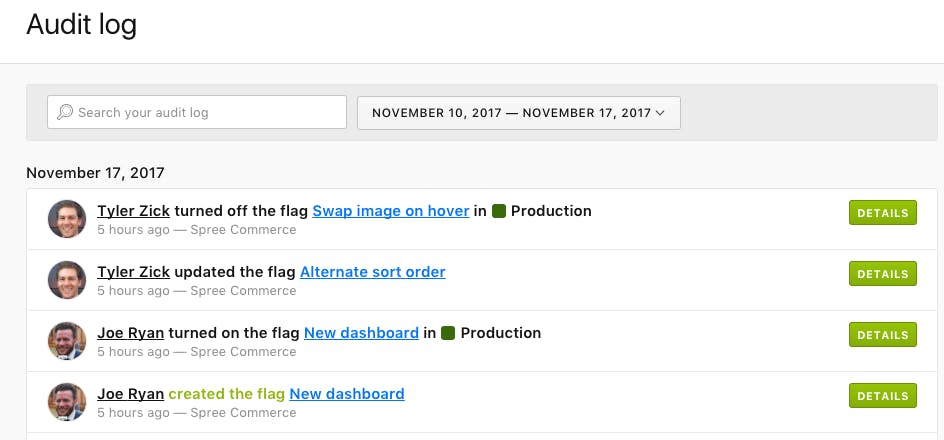
But if you did have an audit log in place, you could quickly go back into your records and identify where a change was made, what the change was, and who made it. In this case, someone thought the rollout was doing so well, they decided to push it to 100%. However, they didn't realize there were customers excluded from the rollout because they shouldn't be experiencing this kind of change just yet. You could see that the exclusion rule was deleted, and you now know what you can do to fix this and move forward.
So, now I'm sure you can appreciate the value of an audit log over a simple event log. And what your team could be doing instead of hunting down elusive unknowns and what-ifs. With this valuable knowledge in hand, you can quickly identify why an event happened, and decide on how to proceed next with more confidence.
¹Martin Fowler (2004), The Audit Log

















