Artificial intelligence tools, particularly large language models (LLMs), aren’t like traditional software. AI is probabilistic, so the same instructions and inputs can produce different results, especially when using non‑zero temperature or other sampling methods, and those results can shift as your context changes. That unpredictability brings real risks because models can miss the mark, invent facts, or generate unfair or unsafe outputs. They can also incur unexpected costs and slow down under heavy loads, and they must constantly adapt to evolving policies and ethical guidelines.
AI experimentation means iteratively testing data, algorithms, and parameters to optimize model performance and validate hypotheses. You need a clear, repeatable way to try ideas, compare prompts and models, validate how your system finds and uses information, and do safety checks before changes reach real users. Experimentation is not just a “nice to have”; it's essential for shipping AI responsibly, it optimizes resource efficiency to help reduce costs, and it accelerates innovation by enabling rapid, evidence-based iteration cycles.
Throughout this guide, we distinguish evaluation (offline benchmarking and scoring: test sets, human or AI judges, and quality metrics) from experimentation (controlled production changes that affect real users via A/B tests, interleaving, or staged rollouts). Evaluation tells you whether a variant clears a quality bar; experimentation tells you whether it beats the baseline in production, with statistical confidence and guardrails.
In this article, we cover the core ideas and practical steps for AI experimentation: how to plan a test, evaluate changes, run controlled trials with real users (A/B tests), choose metrics that actually matter to your product, and roll out changes safely. By the end, you will have an understanding of the process, from initial concept to a monitored, controlled production release that you can execute confidently and repeatedly.
AI experimentation best practices
Best practice | Description |
|---|---|
Use experimentation to manage uncertainty | AI outputs can shift over time; structured experimentation helps teams measure, compare, and validate changes before they reach users. It turns unpredictability into a controlled process for improvement. |
Build trust through evidence, not intuition | Without experimentation, teams rely on gut feeling. Controlled tests provide measurable evidence of what works, helping you make confident, data-driven decisions. |
Detect and reduce hidden risks early | Experimentation surfaces issues such as hallucinations, bias, or performance regressions before they impact real users. It’s a proactive safeguard for reliability and safety. |
Enable continuous improvement | AI systems evolve, with new data, models, and contexts constantly emerging. Experimentation provides a repeatable way to adapt and refine your system as conditions change. Reinforcement learning is a great example of this. |
Design experiments with statistical power and variance in mind | Collect multiple observations per variant to account for nondeterminism. Use confidence intervals and statistical significance tests over single-run comparisons to define a minimum detectable effect (MDE). Combine this with guardrails (e.g., latency, cost, safety) and a decision rule, as measurement alone doesn't distinguish real lift from noise. |
Support responsible and compliant AI | Experimentation frameworks help teams evaluate whether updates align with ethical standards, privacy requirements, and evolving policies, making responsible AI development a built-in process, not an afterthought. |
Keep track of cost and latency | Track per-session spend and speed, set budgets and max_tokens, optimize prompts/context, use caching/streaming, and monitor TTFT, p95/p99, retries, and spend. |
Conduct controlled testing with real users | Run A/B or interleaving with sticky cohorts; measure satisfaction, task completion, and business lift; and do a canary rollout with rollback thresholds. |
Perform evaluation | Define metrics for truthfulness, UX, reliability, and cost/speed; instrument deeply; and test in layers and expand only when stable. Evaluation alone tells you whether a system meets a bar, while experimentation determines which variant should be trusted in production and how traffic should evolve. |
Use retrieval evaluation (for RAG) | Evaluate model quality by measuring recall@k and citation accuracy (to prevent hallucinations), along with cost/latency. After offline quality assessment, use live or shadow traffic for controlled experiments to optimize the retriever, chunking, or ranking. |
Ensure proper governance and safety for AI experimentation | Pre-register your experiment plan, including hypothesis, primary metric, and MDE, and version all prompts, models, and guardrails to ensure compliance, safety, and auditability. |
Why AI needs experimentation
Traditional software works like a calculator: same input, same output. AI is more like a conversational smart assistant that is helpful and creative but can sometimes be surprising. Since AI is not predictable and small changes in words can shift results, you cannot judge the quality of a tool from a single right answer.
AI features are pipelines with many moving parts, models that may update, prompts that steer behavior, tools and APIs that can fail, and knowledge sources that drift as content changes. All of these can have an effect on accuracy, safety, speed, and cost. A one-time test won’t catch issues that show up under real traffic.
That’s why experimentation is essential. It gives teams a structured way to observe, measure, and improve AI behavior as it changes. Through continuous testing, you can detect drift, uncover hidden risks, and build confidence that your system performs reliably and responsibly.
In the next few sections, we explore how to put this into practice, from designing experiments and choosing metrics to running controlled rollouts and monitoring results.
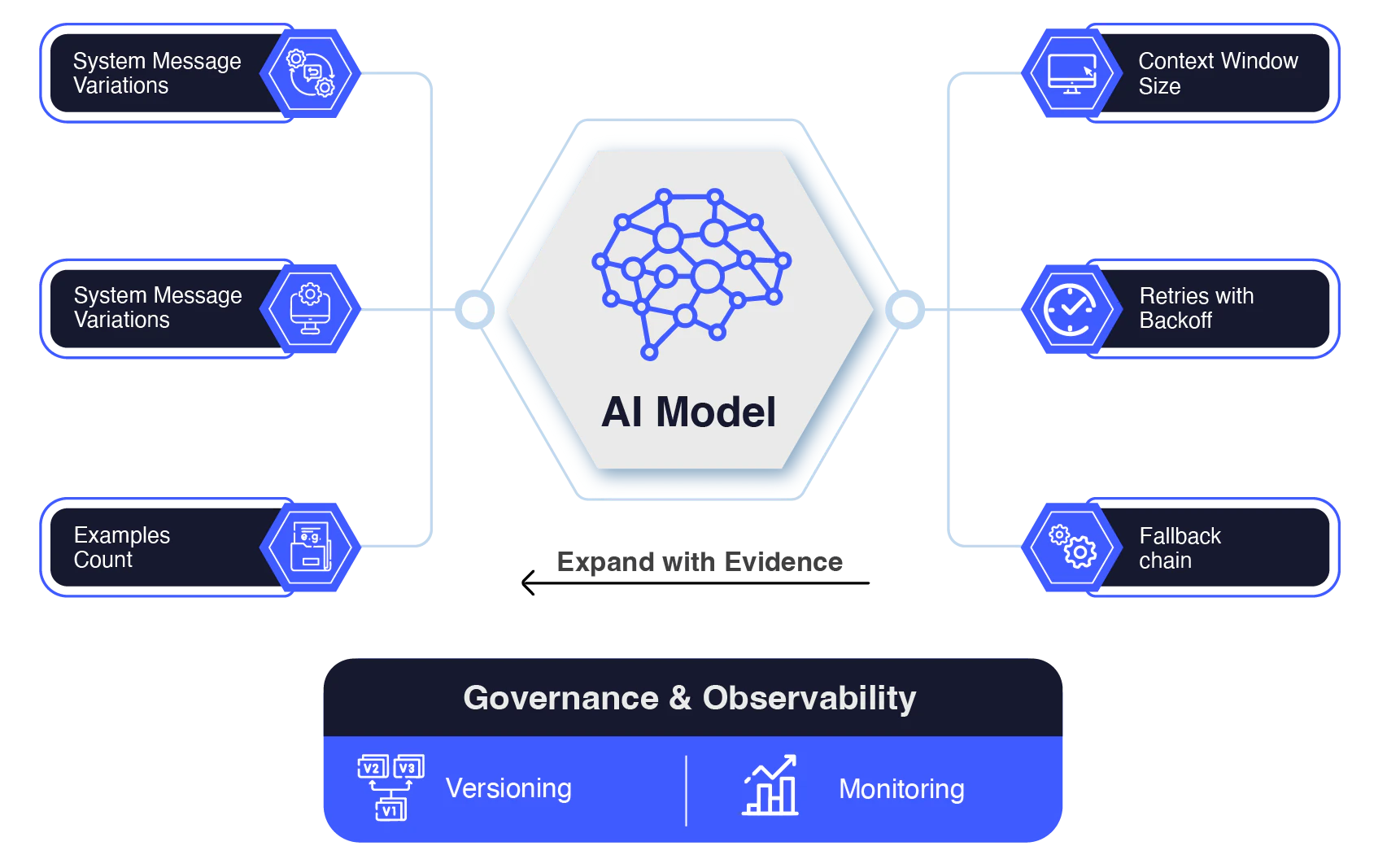
The hierarchy of levers: Where to focus your optimization efforts
In practice, these levers should be optimized in order of impact and reversibility: system message → examples → output format → context → retries/fallbacks → model and parameters.
System message variations
The system message is one of the most powerful levers in shaping an AI model’s behavior. It defines the model’s role, tone, and boundaries, essentially setting the “personality” and guardrails for how it responds.
Small changes here can dramatically affect safety and reliability. For example, tightening the tone or adding an “out-of-scope” clause can prevent the model from generating speculative or unsafe content. On the other hand, overly rigid instructions can make responses sound robotic or unhelpful.
That’s why it’s worth experimenting with a few variations and testing how different system messages perform across diverse scenarios, including edge or adversarial cases. The goal isn’t just to find one that “works” but to understand how tone and framing influence quality, cost, and latency.
In short, system messages are your first and most important quality lever; they set the foundation for every other experiment that follows.
Choosing the right number of examples
Compare zero-, one-, and few-shot (typically 3–5) examples in the prompt. Mix common and edge cases, include “do and don’t” examples, and show the exact output format. Short examples teach patterns, but they also add tokens and delay. Measure accuracy, format adherence, generalization, and cost.
Output format
Choose between free text, simple structured templates, or native structured outputs. Structured outputs are easier to parse and validate but can constrain creativity or break on truncation. Always validate, handle partial outputs gracefully, and keep templates simple. Use a temporary “explain” field while testing.
Context window size
Your experiment should focus on testing the cost-benefit of precision context vs. extended context. Often, increasing the context only increases cost and latency without actually improving output quality.
Retries with backoff
Use 1–2 attempts for temporary errors (failures likely to succeed on retry, like rate limits, timeouts, or server overload) with exponential backoff and jitter. Log error rates, latency, and cost. Ensure idempotency, cap retries, and enforce timeouts. Offer a polite fallback when limits are hit.
Fallback chain
Route to a backup model/provider in the event of failures or slowness. Keep prompts and formats aligned (ensure that the backup model understands your prompt structure and returns responses in the same format) and preserve the conversation state. Verify that the required features exist on the fallback, and log the reasons for routing.
The expansion rule
Experimentation should scale based on evidence, not just enthusiasm. Once your pilot shows strong performance, expand the rollout to broader audiences. Scale only when metrics justify it: Success rates are high, failure rates are low, and time or cost remains acceptable. Expansion ideally means scaling up after validation; high success rates are the trigger for expansion, not something that happens coincidentally.
Models and parameters
Now that we've covered core quality levers, prompts, evaluation, and operational practices, let's dig into models and parameter tuning, the backbone of any AI system. These are the foundational choices that determine your system's capabilities, behavior, and costs.
Think of models and parameters as your AI tuning panel: the set of dials you reach for when you want more accuracy, fewer hallucinations, faster responses, or lower cost. The art lies in knowing which dial to turn, and by how much.
Start with the right model for the job. Use a more capable one for complex reasoning or planning and a smaller, faster one for routine tasks. A good rule of thumb is to match the model’s strength to the complexity and stakes of the task and not use a heavyweight model when a lightweight one can do the job just as well. Always lock down the exact version so your results stay reproducible as the model evolves. That said, version pinning reduces variability but doesn’t eliminate drift. Because upstream model behavior and real‑world inputs can still change over time, production experiments and ongoing holdbacks are necessary to detect regressions even when versions are pinned.
Then come the parameters, the fine‑tuning knobs that shape how your AI behaves:
- Temperature: Temperature controls how adventurous or conservative the model’s output is. It is the primary generation setting most users adjust.
- Keep it low (0-0.3) for code, structured formats, or safety‑critical tasks.
- Go higher (0.7-1.0) when you want creativity or brainstorming.
- Stay in the middle for everyday conversations.
Other sampling parameters like top_p or top_k also influence output diversity, but in practice, temperature has the largest and most predictable effect, so it’s usually the first (and often only) parameter worth tuning.
- Retrieval and search: Don’t rely only on keywords because meaning matters more.
- Semantic search helps the model understand intent.
- Hybrid search (semantic + keyword) works best for short queries or exact names.
- Choose an embedding model that fits your language and domain, and keep its version fixed.
Quick note on database types: a graph database models relationships and traversals (nodes/edges)—for queries like “how is X connected to Y?”—while a vector database (or vector-enabled datastore) is optimized for similarity search over embeddings to support retrieval in RAG pipelines.
- Chunking and metadata:
- Split documents into natural sections with slight overlaps; sliding windows help for long text.
- Add good metadata to improve filtering and relevance.
When experimenting, start with a baseline and tweak one variable at a time: temperature, chunk size, top_k, re‑ranking, or search type. Evaluate offline using a labeled dataset from your domain, and measure both accuracy and faithfulness to the provided context.
For safety‑sensitive or compliance use cases, keep the temperature low and favor concise, structured answers. If you need strict formats, define a clear schema and stick to it.
In short, models and parameters are your creative controls, and small adjustments here can completely change how your AI thinks, speaks, and performs.
Tool and function management
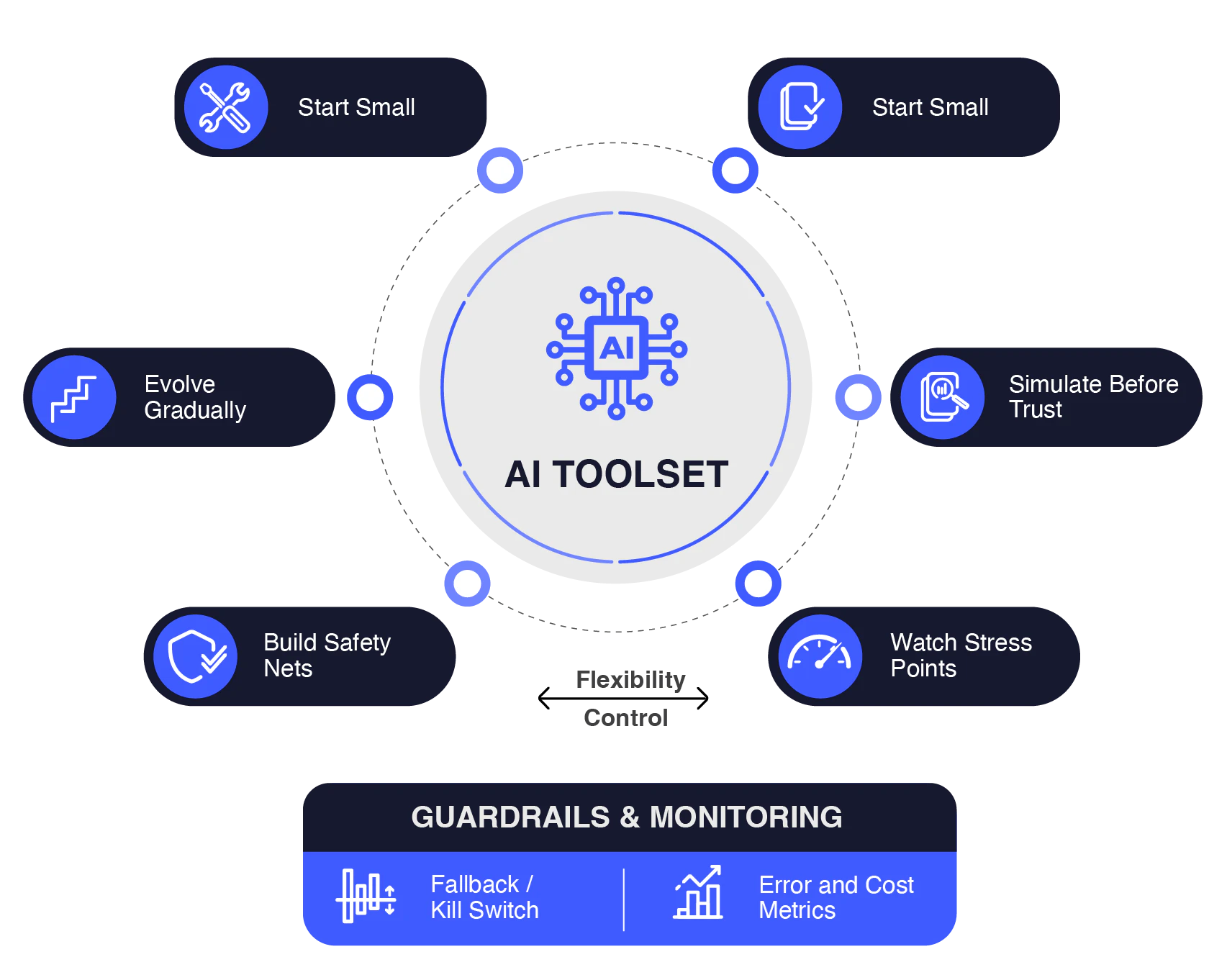
Think of tools as the hands and eyes of your AI: They’re what turn abstract intelligence into real‑world action. But just like you wouldn’t hand every tool in a workshop to a beginner, your AI shouldn’t have access to everything all at once either. A focused, well‑defined toolset keeps things efficient, safe, and predictable. The trick is finding that sweet spot between flexibility and control: enough freedom for the AI to get creative but enough guardrails to prevent chaos.
When you’re experimenting, it helps to keep a few ideas in mind:
- Start small: Give your AI only the tools it truly needs, then expand as you learn what works.
- Simulate before you trust: Test tool behavior with mock or historical data before letting it touch anything live.
- Watch for stress points: Even great tools can fail under load, so monitor error rates, latency, and cost so you can react fast.
- Build safety nets: Use circuit breakers, fallback options, and kill switches to keep things stable when something breaks.
- Evolve gradually: Roll out changes quietly, shadow test, and scale only when the data says it’s safe.
In the end, managing tools is less about control and more about balance, giving your AI just enough reach to be useful but not so much that it forgets to play safe.
Cost and latency
Managing cost and latency in AI systems is a bit like tuning a race car: You want speed and performance, but you can’t afford to burn all your fuel in one lap. The trick is knowing where your money and time actually go: tokens in and out, model rates, tool usage, and even retries.
Experiment design plays a role here, too. Multi‑armed-bandit approaches can reduce spend by shifting traffic away from losing variants early, while long, fixed‑horizon A/B tests can waste budget once a clear winner has already emerged. Once you see the full picture, optimization becomes a lot less mysterious.
A few smart habits go a long way:
- Match the model to the job: Use smaller models for routine tasks and save the heavyweights for complex reasoning or creative work.
- Set clear budgets: Cap tokens and costs per session, so things don’t spiral.
- Cache and reuse: If you’ve already fetched or generated something useful, don’t pay for it twice.
- Retry wisely: Every retry costs tokens, so validate inputs early and use exponential backoff to avoid waste.
- Measure what matters: Track cost per successful answer, not just per call, to see true efficiency.
- Watch the signals: Keep an eye on latency metrics, like time to first token (TTFT), p95/p99 response times, and error rates, to catch slowdowns before they hurt users.
In short, cost and latency aren’t enemies; they’re partners in performance. The goal is to spend smart, getting the best possible result for every token and every millisecond.
Experimentation before user exposure
Before any major AI update reaches real users, it deserves a proper dress rehearsal. Catching issues before users see them prevents bad experiences, unnecessary costs, and reputational damage. A single poor output in production can erode confidence; ten minutes of offline testing can often save hours of incident response.
Start by building a test set that mirrors real‑world scenarios: a mix of genuine examples and synthetic edge cases. If you’re working with RAG, make sure answers link back to their sources, so you can check how well the model grounds its responses. Then bring in an AI judge or evaluation rubric to score outputs for correctness, completeness, and clarity. Automating this process helps you see how each tweak affects quality, reliability, cost, and latency. The goal isn’t just to test but to make experimentation repeatable and data‑driven.
Here are a few best practices to keep things disciplined:
- Set clear thresholds: Define what “good enough” means (e.g., a minimum score lift or win rate) before moving forward.
- Shadow test safely: Run your new model alongside the current one on real traffic, but keep the results hidden from users.
- Control costs; Sample requests, cache results, and limit verbosity to keep experiments efficient.
- Protect fairness and privacy: Ensure that retrievals are consistent and independent, and compare both versions in terms of quality, reliability, cost, and speed.
Once the new model shows stable performance, no quality drops, no latency spikes, and no cost overruns, you’re ready for a canary rollout with instant rollback on standby. It might feel slow, but this careful, staged approach is what separates reliable AI systems from risky experiments. Every improvement you ship should be backed by evidence, not just optimism. While pre‑production testing catches many issues, it can’t replace controlled experimentation in production, where real traffic distributions, latency constraints, and cost dynamics truly emerge.
Controlled testing with real users
Testing with real users is where theory meets reality. It’s the moment your AI steps out of the lab and into the wild, and you learn what truly works. The goal is to gather insights while keeping risk low and user experience intact.
A practical way to do this is through A/B testing. By assigning users to consistent test groups (often called sticky assignments), you can compare different versions of your AI system under real conditions. This helps you see what’s improving and what still needs work, without disrupting everyone’s experience, and it enables statistical decision-making (e.g., confidence intervals and significance testing) rather than relying on anecdotal wins.
To make your tests meaningful:
- Keep traffic splits representative: Cover different user segments, regions, and use cases.
- Tag everything: Include version, prompt, model, and settings in every request so you can trace outcomes later.
- Measure what matters: Focus on metrics that reflect real impact, user satisfaction (e.g., thumbs up/down, edits, and retries), task completion, and business outcomes like conversions or revenue lift. Skip vanity metrics that don’t tell a real story.
When rolling out updates, start small with an internal beta, then gradually expand (1%, 5%, 10%, and so on). Watch quality, latency, and failure rates closely. If something goes wrong, roll back instantly and investigate.
If metrics dip and then pause, route traffic back to the stable version, debug with detailed logs, fix the issue, and restart from a smaller group. This iterative rhythm/test/learn/adjust process keeps users safe while your AI evolves steadily.
Not all AI experiments have a fixed end date. Many teams run ongoing control groups (holdbacks) or multi-armed bandits (MABs) that continuously monitor performance and adapt traffic allocation as models, data, or user behavior change. They are able to do this while keeping explicit guardrails and rollback thresholds so optimization never trades off safety, latency, or cost.
At the end of the day, the principle is simple: Learn fast, protect users, and let data lead the way. Thoughtful testing, meaningful metrics, and firm rollback rules are what turn experimentation into confident, responsible progress.
Evaluation
Evaluation isn't just about checking if the model runs. It's about understanding how well it serves users, how reliable it is under real conditions, and whether it delivers value within your operational limits. A strong evaluation framework helps you balance quality, cost, and performance, ensuring that your AI system grows responsibly and sustainably.
Remember that testing shouldn’t stop once you deploy. Layer your evaluations, starting with offline tests, then shadow testing, and finally limited rollouts. Set clear targets for quality, reliability, and cost. Instrument everything, so you can explain wins and diagnose regressions. Expand only when metrics hold steady and costs stay within bounds.
Here are some specific areas to look at when it comes to evaluation.
Quality and accuracy
Start with the basics: Does the model tell the truth?
Validate answers against a known ground truth using offline tests and side‑by‑side reviews. AI judges provide scalable signals, but they should be calibrated against human review and used primarily for relative comparison between variants rather than absolute truth. In production, track user‑reported issues and citation accuracy. Metrics such as acceptance rate, faithfulness, and hallucination frequency reveal whether your system is trustworthy. Setting minimum quality thresholds ensures that you never trade accuracy for speed.
User experience
Even a perfectly accurate model fails if it frustrates users. Focus on fast, helpful first responses and aim for fewer hand‑offs to humans. Measure satisfaction, task completion, and rewrite rates to see where users struggle. Instead of only tracking throughput, monitor time to first token and useful answer, the outputs that shape perceived responsiveness.
Reliability
Reliability means having tools that behave predictably. Check that outputs match expected formats and that retries or timeouts are rare. Track error rates, schema validity, and success ratios. Define service‑level objectives (SLOs), and trigger automatic rollbacks if failures exceed limits. This discipline keeps small glitches from snowballing into outages.
Cost and speed
Every token, retrieval, and retry has a price, so break down the latency and cost by stage to know where the money goes. Use smaller or cached models for routine tasks, stream responses when possible, and tighten prompts to cut waste. The goal is to optimize cost per successful answer, not just raw token count.
Observability
You can’t improve what you can’t see, so log prompts, parameters, and tool calls (masking any personal data), then feed them into dashboards that track cost, speed, quality, and safety. Open telemetry standards make it easy to integrate with existing monitoring tools. Alerts on anomalies or drift can help you catch regressions before users notice.
Evaluating retrieval quality
Great answers depend on great context. Assess the retriever, reranker, and generator both separately and together:
- Recall@k shows whether the right documents even appear.
- Precision@k (percentage of retrieved docs that are relevant) and nDCG/MRR (ranking quality; how well relevant docs are ordered) reveal how well they're ranked.
- Attributable accuracy ties correct answers to supporting evidence, while unsupported claim rate flags hallucinations.
- Track citation correctness, freshness, and cost/latency impact to ensure that retrieval adds value rather than overhead.
Offline QA sets with labeled passages make quality measurable. Slice results by topic, query type, and language to uncover weak spots. Add confidence gating, so the system can admit uncertainty instead of fabricating answers.
Observability for retrieval
Instrument retrieval is just like generation. Log query details, index versions, and latency. Use dashboards to visualize recall, accuracy, and latency percentiles. Set up drift detection to catch drops in recall or spikes in unsupported claims after reindexing. Use canary or shadow tests before rollout to keep new indexes safe.
Governance and safety in AI experimentation
When it comes to AI experimentation, governance and safety aren’t just boxes to tick; they’re what keep innovation trustworthy. The goal is to find measurable improvement while protecting users, respecting constraints, and keeping everything reproducible.
Security and access control
Before any experiment touches real data or users, establish who can change what and how:
- Role-based permissions: Limit who can modify prompts, deploy models, or access production logs. Use separate environments (dev, staging, prod) with different access levels.
- Approval workflows: Require signoff from security, legal, or compliance teams before experiments involving sensitive data, regulated industries, or high-risk use cases.
- Audit trails: Maintain immutable logs of who changed what, when, and why. This isn't just for compliance; it's essential for debugging and accountability.
Safety guardrails
Set hard limits that experiments cannot violate:
- Content filters: Block harmful, biased, or inappropriate outputs before they reach users. Test these filters regularly against adversarial examples.
- Rate limiting: Cap API calls, token usage, and costs per user/session to prevent abuse or runaway expenses.
- Automated circuit breakers: Define thresholds for error rates, latency spikes, or quality drops that trigger automatic rollbacks or alerts.
- Privacy protections: Mask or redact PII in logs, ensure that data retention policies are enforced, and validate that experiments against privacy requirements including GDPR, CCPA, or other relevant obligations.
Reproducibility and compliance
Strong governance means being able to prove exactly what happened in any experiment:
- Control randomness (where possible): Fix random seeds or sampling settings (e.g., temperature or top_p) when supported, so runs can be repeated consistently.
- Version control: Lock down dataset versions, model IDs, prompt templates, and configuration files. Every experiment should be reproducible from these artifacts.
- Preregistration: Document your hypothesis, success criteria, and analysis plan before running tests. This prevents post hoc rationalization and ensures honest evaluation.
- Immutable experiment records: Store snapshots of inputs, outputs, parameters, and results that cannot be altered after the fact. Use tools like MLflow or DVC to centralize tracking.
Rollback and kill switches
No matter how careful you are, things can go wrong. Governance means being prepared in multiple ways:
- Instant rollback: Keep the previous version ready to deploy with a single command. Test rollback procedures regularly.
- Kill switches: Build manual overrides that can immediately halt an experiment if safety or quality issues emerge.
- Staged rollouts with monitoring: Deploy to 1% of users first, watch for anomalies, then gradually expand only when metrics stay stable.
Ongoing monitoring
Governance doesn't stop at launch. Continue tracking by alerting when model performance, user behavior, or data distributions shift unexpectedly. Periodically re-run safety and quality checks as your system evolves. And be sure to have a documented process for investigating failures, notifying stakeholders, and implementing fixes.
How LaunchDarkly helps with AI experimentation
Where many AI tools stop at evaluation, LaunchDarkly helps enable true production experimentation with traffic allocation, statistical significance, and automated decision-making. AI experimentation needs an operational layer that manages prompts, models, parameters, cohorts, traffic allocation, and rollouts safely. Teams often try to build things themselves, but it quickly becomes complex.
Unlike homegrown solutions that require engineering work for every change, LaunchDarkly gives you:
- Instant updates without deployments: Change prompts, swap models, or adjust parameters through the dashboard without redeploying application code.
- Safe, gradual rollouts: Test new models on 1% of users, monitor quality and cost in real time, then expand or roll back instantly based on what you observe. You avoid the typical all-or-nothing deployments.
- Centralized control with governance: Version-control every configuration change, maintain audit trails, and manage who can modify what. Your entire team can experiment safely without stepping on each other's toes.
- Built-in experimentation framework: Run A/B tests comparing models, prompts, or parameters with proper statistical rigor. Set up LaunchDarkly to track metrics automatically, so you can make data-driven decisions.
- Separation of concerns: Developers can focus on building features, cross-functional teams can safely participate in experimentation workflows, and automated systems handle traffic allocation, optimization, and rollback.
LaunchDarkly feature flags and AgentControl let you treat AI components as dynamic configurations rather than static code, giving you the speed and safety needed for continuous experimentation at scale. Let's see this in action by building a simple switch between two different AI models using AgentControl configs.
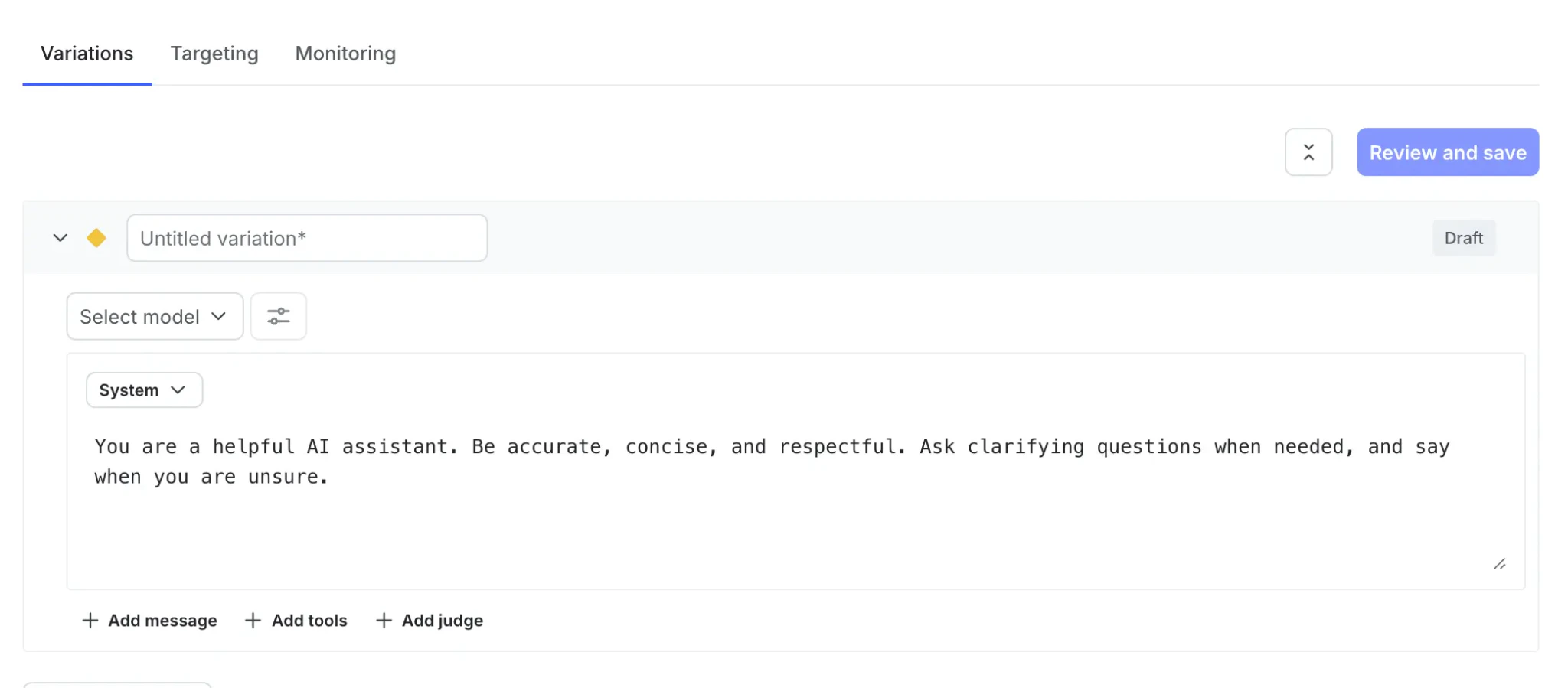
In the LaunchDarkly dashboard, open AI, select AgentControl, create a config for the AI workflow, and define variations for each model you want to compare.
In this example, we create two config variations for different OpenAI models so we can switch between them after deployment.
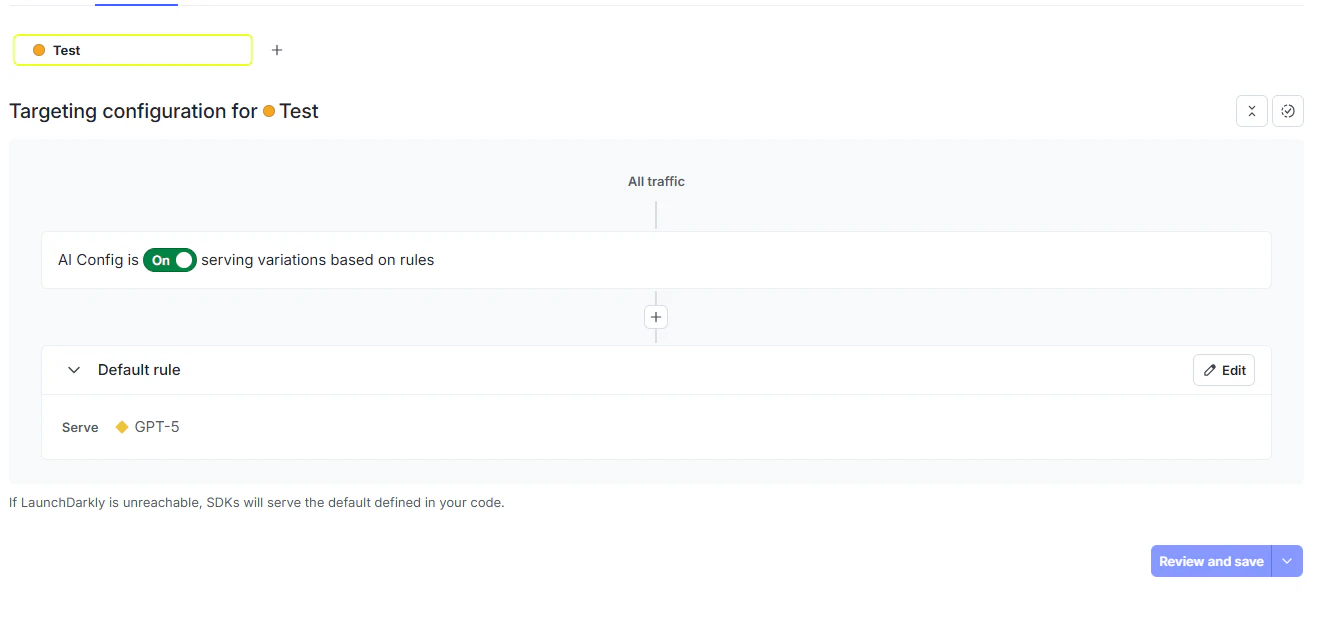
After setting up the config variations, use targeting to control which model variation is served and define a safe default.
You can integrate the config into your application using the LaunchDarkly SDK and AI SDK. The simplified example below shows how an application retrieves a config variation at runtime and uses it to call the selected AI model.
Note: This example is simplified for illustration. Production implementations should externalize secrets, define explicit fallbacks, enforce timeouts, and include error handling and guardrails.
Notebook: LaunchDarkly Setup and AgentControl configs. This also highlights how you can get the SDK key.
Install the necessary Python packages to enable LaunchDarkly.
Next, import essential dependencies.
Now set up the OpenAI and LaunchDarkly clients.
The code below runs an A/B test where two users receive responses from different AI model configurations to the same query, allowing baseline and experimental outputs to be compared.
Using the code above, one user receives the GPT-5 variation from the config.

Using the same code, just after changing the model, we get a different output with the OpenAI gpt-4o model.

Outcome: The two users receive different model variations without requiring a redeploy, making it easier to compare quality, latency, and cost under controlled conditions.
Final thoughts
Experimentation should be part of everyday work: a habit, not a one‑off project. Keep iterating, version your data, and let real numbers guide your decisions instead of hunches. Treat every AI change like a hypothesis, where every hypothesis should map to a clear traffic allocation strategy, decision rule, and rollback condition. Change one thing at a time. Roll out updates in safe, deliberate steps, start offline, move to shadow testing, then gradually expand through canary rollouts while tracking quality, cost, and latency.
In the end, the teams that win are the ones that measure, monitor, and improve continuously, shipping based on data, not guesses. Tools like LaunchDarkly AgentControl configs make this process smoother by keeping prompts, models, and parameters versioned, targetable, and reversible.