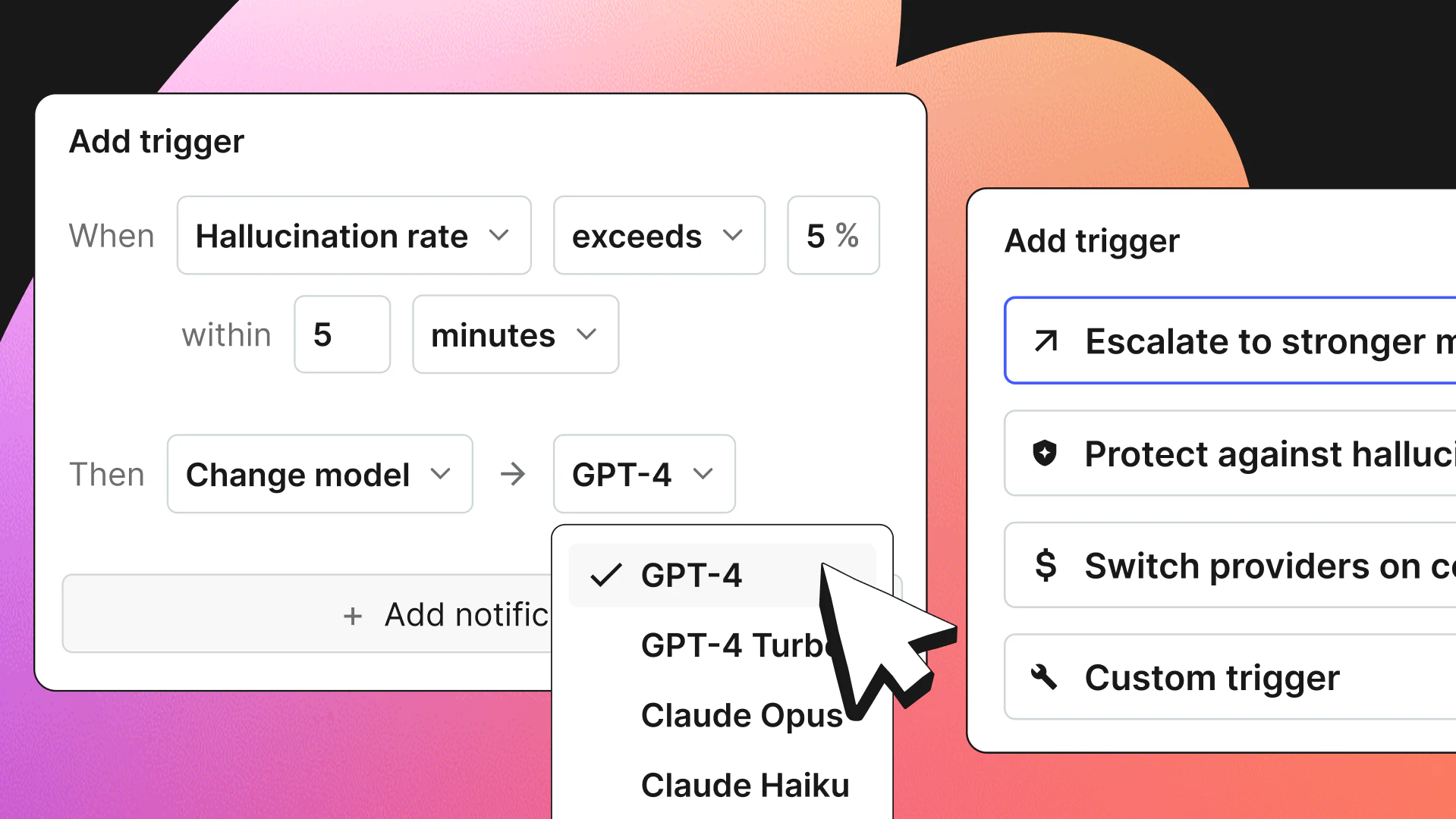
A common failure pattern in a retrieval-augmented generation (RAG) system is a progressive decline in performance. This decline, which can be difficult for users to detect initially, often begins with a reduction in retrieval relevance. Over time, it may lead to longer response times and increasingly inaccurate, incomplete, or less helpful responses. This gradual degradation of the system's performance creates a challenging user experience.
Production failures often stem from uncoordinated changes, with operators adjusting retrieval settings, reranking methods, or model routing without a shared change process. Without explicit versioning and ownership, it becomes difficult to trace which change caused a regression or who made it.
This article argues that production AI pipelines, particularly RAG systems, must be designed around explicit control of change. The system must treat retrieval and prompting, evaluation, and model selection as controllable elements that people running the system must be able to modify through visible changes during active system use. The goal is not to introduce new techniques but to show how existing, well-understood methods can be composed into a production system that remains stable, measurable, and adaptable over time.
Summary of core AI pipeline design considerations
Stage | Core Focus | Why It Matters | Relevant AgentControl config Features |
|---|---|---|---|
Problem Definition | Defining use case, retrieval scope, and measurable KPIs | Unenforceable or missing baselines make it impossible to detect degradation later. | AgentControl config variations and tools for retrieval depth, reranker selection, and instant switching without redeployment |
Knowledge Grounding and Retrieval | Chunking, embeddings, retrieval, GraphRAG, and reranking | Uncontrolled changes to retrieval parameters are a primary source of grounding failures. | AgentControl config variations for retrieval parameters (top-k, graph hops); model-specific index routing |
Model Selection and Orchestration | Routing across embedding models, rerankers, and LLMs | Hard-coded models make every experiment a redeployment and every failure a production incident. | AgentControl config variations bundle model, prompt, and parameters atomically; percentage rollouts for A/B testing |
Prompt Engineering and Configuration Management | Versioned, parameterized prompt templates | Ungoverned prompt changes are one of the fastest ways to break a functioning pipeline. | AgentControl config for prompt versioning with variable substitution and segment-based targeting |
Evaluation and Guardrails | Grounding accuracy, safety filters, and gating logic | Changes without evaluation gates allow regressions to reach users undetected. | AgentControl Online Evaluations for accuracy, relevance, toxicity scoring; guarded rollouts for automatic rollback |
Experimentation and Feature Flags | Controlled variant testing under live traffic | Without bounded exposure, pipeline variables interact in ways that are difficult to diagnose or reverse. | AgentControl config variations with percentage rollouts; traffic allocation by segment or context |
Deployment and Rollout | Separating code deployment from behavioral rollout | Releasing behavior changes to all users at once amplifies the impacted scope of any regression. | AgentControl config targeting with percentage rollouts; progressive exposure with instant rollback |
Cost and Latency Optimization | Complexity-based routing, caching, and batching | Routing all requests through the highest-capability path increases cost without proportional quality gain. | AgentControl config targeting rules for model tier routing; context-based cost optimization |
Monitoring and Observability | Tracking retrieval drift, grounding accuracy, and latency | Early detection of issues. RAG systems degrade gradually: Regressions often only become visible after affecting end users | AgentControl monitoring for per-variation metrics |
Feedback and Iteration | Structured collection of user signals and error traces | Continuous improvement loops. Ad hoc iteration based on intuition rather than signals leads to unpredictable system behavior |
Note that “hit rate” refers to the proportion of user queries for which the retrieval layer successfully returns at least one relevant document that is subsequently used in the generated response.
In practice, this architecture benefits multiple roles across the AI team. Engineers can test retrieval and model changes safely under controlled exposure, product teams can iterate on prompts through versioned configurations, and operations teams gain faster response to production regressions through automated rollback and monitoring signals.
Note: For demo purposes, you can set up a reference implementation of a configuration-driven RAG pipeline in a single executable environment, while in practice, production usually operates with numerous services.
The following diagram shows how these stages from the above table connect in a production RAG pipeline, each independently configurable under live traffic conditions.
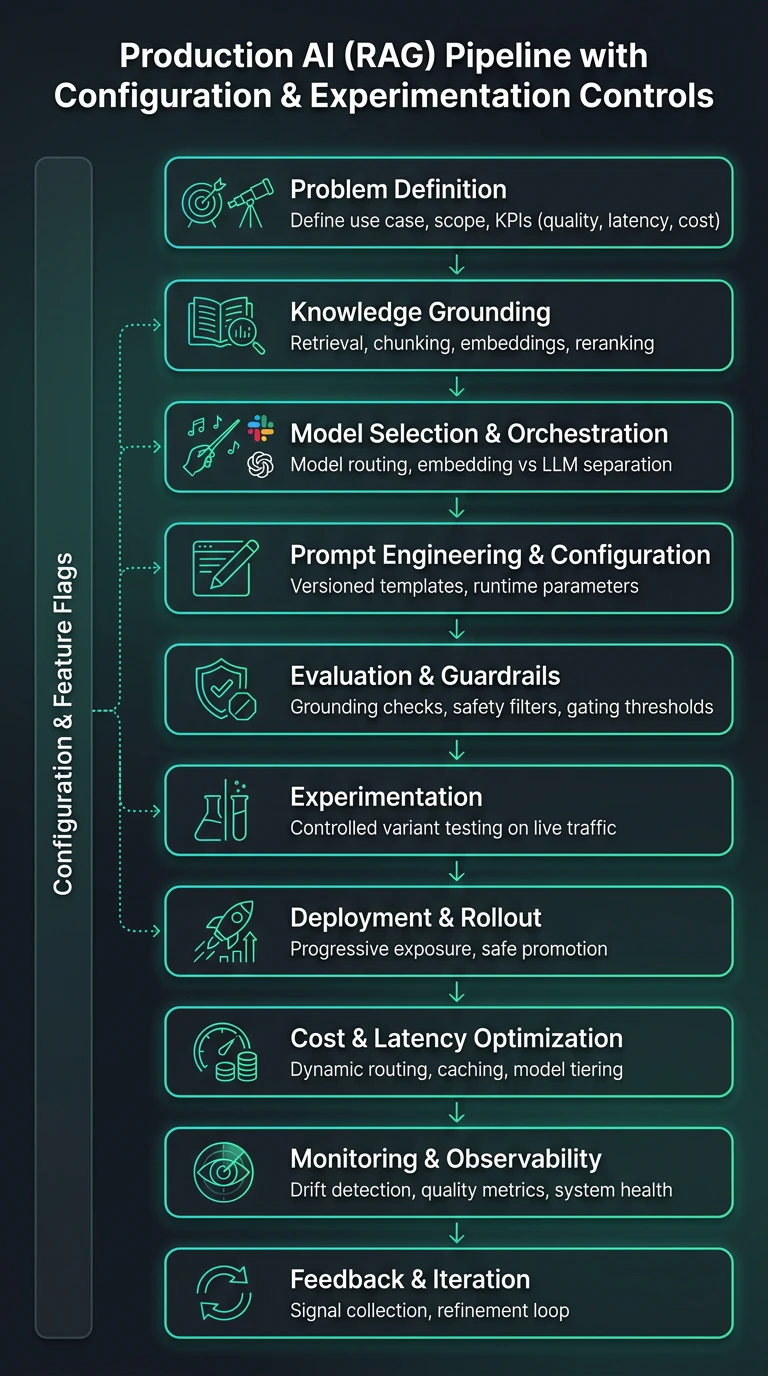
Changes such as modifying retrieval depth or enabling a reranker can be exposed to a subset of users, evaluated against grounding and latency thresholds, and automatically rolled back if regressions are detected, essentially keeping iteration safe without freezing the system.
Production reliability depends on three disciplines: explicit versioning of prompts and models, continuous evaluation signals, and enforced rollback logic. Together, these prevent uncontrolled drift while enabling safe iteration.
Problem definition: Making quality measurable before you optimize
The quality of a production RAG pipeline is strongly influenced by how clearly the problem is defined before implementation. The problem definition directly constrains downstream design choices such as retrieval scope, evaluation metrics, latency budgets, and acceptable trade-offs across the system.
Start by identifying the primary use case and pairing it with measurable KPIs: retrieval hit rate, reranker lift, citation accuracy, latency budgets, and hallucination or grounding error rates. These should be treated as configurable ranges rather than fixed standards, since acceptable thresholds differ across domains and use cases.
While initial requirements may live in planning tools like Jira or Confluence, AgentControl configs elevate key parameters to operational controls, making retrieval thresholds, quality gates, and rollback triggers runtime-configurable rather than static specifications. Unlike hardcoded thresholds buried in application code, AgentControl configs surface these parameters in a dashboard where they can be adjusted, monitored, and rolled back by anyone with access, not just engineers with deployment permissions.
For example, teams may externalize the thresholds for retrieval quality, reranker effectiveness, and latency as configuration flags that control enforcement and rollback. In Python, these can be combined as shown below:
In this model, thresholds are active policies integrated into evaluation gates and rollout controls. Changes can be exposed incrementally, measured against live metrics, and automatically rolled back when performance degrades. By treating configuration as an operational control surface rather than static settings, the pipeline remains adaptable without sacrificing production stability.
Knowledge grounding: Designing retrieval as a configurable system
In production RAG workflows, unregulated changes to retrieval methods and performance parameters—such as chunking strategies, embedding models, graph traversal depth, or reranker settings—often degrade retrieval quality. This degradation then propagates downstream, manifesting as grounding failures during generation. To minimize this risk, the retrieval layer should be designed as a thoroughly parameterized system, encompassing chunking methods (fixed or semantic), embedding model selection, retrieval depth (top-k), GraphRAG traversal depth, reranker configuration, and context window limits.
A layered retrieval approach might consist of vector-based retrieval of unstructured data, optional graph-based expansion for the improvement of relational context, and reranking for precision. A control-plane system governs the parameters exposed by each pipeline layer, making them observable, configurable, and safe to experiment with without modifying application code. In LaunchDarkly, AgentControl configs provide this control layer, storing retrieval configuration as versioned variations that can be tested incrementally and rolled back instantly. Retrieval quality remains adjustable at runtime, and the retrieval quality is not dependent on the speed of the assessment of the variants (e.g., chunk size or hop depth), since the assessment can be done with live traffic, provided that changes are gated and evaluated incrementally.
Parameters such as top-k, graph-hop depth, reranker toggles, embedding model selection, and fallback behavior are governed through configuration, enabling safe iteration without redeployment. AgentControl config targeting enables instant fallback by switching which variation is served with no redeployment required. If a new retrieval strategy degrades quality, revert to the baseline variation in seconds. This means existing vector stores such as Pinecone, Weaviate, FAISS for embeddings, and Neo4j for knowledge graphs are able to continue being used.
For instance, it is possible to construct a multi-layer pipeline: RAG on internal documents, GraphRAG via Neo4j for structured data, and a cross-encoder reranker. The transitions between these layers can be made configurable, allowing reranking to be enabled or disabled, embedding strategies to be adjusted, and routing logic to evolve while preserving production quality.
In practice, retrieval parameters can also be managed as part of a versioned AI configuration, allowing chunking, retrieval depth, graph expansion, reranking, and index selection to evolve together under controlled rollout.
In this model, retrieval behavior becomes a controlled surface rather than a static implementation detail. Teams can enable or disable GraphRAG, adjust traversal depth, swap embedding models, or toggle rerankers safely while monitoring grounding accuracy and latency. This configuration-driven approach keeps retrieval flexible without sacrificing production stability.
Model selection and orchestration
Hard-coding embedding models, rerankers, or LLMs directly into orchestration logic is a common anti-pattern in production AI systems that is easy to trace. The case becomes even more difficult if the embedding model, reranker, or chat model is hard-coded, for then every experiment becomes a redeployment. This will not only slow down the learning process but also increase the risk at the same time.
Model selection should be treated as a routing process rather than a one-time selection decision. AgentControl configs bundle model, prompt, temperature, and max_tokens as a single versioned configuration. When you switch variations, all parameters change atomically, reducing the risk of mismatched model/prompt combinations that can occur when using separate flags for each parameter. In practice, this means that each request is dynamically routed to a model variant based on configuration, traffic allocation, or runtime signals rather than binding the pipeline to a single hard-coded model. The pipeline is asking for “an embedding model” or “a chat model” all the time. Model selection is governed through configuration rather than hard-coded API calls.
In LaunchDarkly, AgentControl config bundles the model, prompt, temperature, and max_tokens as a single versioned variation. When a variation changes, these parameters update atomically, eliminating the risk of mismatched configurations and allowing traffic allocation and fallback behavior to be controlled safely. Fallbacks can be triggered by concrete conditions such as degradation in grounding accuracy, violations of latency budgets, elevated error rates, or failed evaluation checks, allowing the pipeline to revert to a known-stable model automatically.
The following simplified example illustrates how model routing can be externalized through configuration. Rather than binding the pipeline to a specific chat model, the active variant is selected at runtime based on a configuration flag, enabling controlled experimentation and safe fallback behavior.
AgentControl configs separate model selection from application code entirely. The pipeline requests a configuration, and AgentControl config returns the complete model setup based on targeting rules, enabling A/B tests, gradual rollouts, and instant rollback without code changes.
Controlled experiments can be conducted behind this one banner. For example, a Mistral or LLaMA-based deployment can be given just 5% of the total traffic while the baseline continues to be unaffected. Experimentation primitives such as traffic allocation, targeting, and instant kill switches support safer operation in production when combined with proper evaluation signals, monitoring, and rollback discipline, but they do not replace sound system design or operational oversight.
Prompt engineering and configuration management
Prompts are not constant resources; they move with changes in requirements, the evolution of data, and the appearance of edge cases. A lack of governance, coupled with changing prompts, is one of the quickest methods to cause the uprooting of a perfectly functioning pipeline.
AgentControl configs store prompts as versioned configurations in LaunchDarkly rather than in application code. Prompts support variable substitution such as {{context}} and {{user_tier}}, and the template structure, variable slots, and active prompt variants can all be versioned and selected at runtime. This allows teams to test prompt variants, compare outcomes, and restore previous versions when needed. The following simplified example shows how a prompt variant might be selected through configuration at runtime.
This method allows for structured testing, selecting specific users to expose to the new feature, and quickly going back to the previous version, thus harmonizing prompt iteration with the deployment discipline already established for code.
Evaluation and guardrails
During evaluation, configuration values remain in effect, but the focus shifts from the configuration itself to measurable attributes of system behavior, such as grounding quality, latency, and safety-related metrics. Changes in retrieval, prompts, or models should be governed by both objective metrics and qualitative evaluation signals.
Objectively speaking, the correctness of grounding, the time taken, and the accuracy of citations are among the measures applied. Relevance and helpfulness are typically assessed through LLM-as-judge patterns, an approach popularized by tools such as OpenAI Evals and Patronus.
AgentControl includes built-in Online Evaluations that allow teams to attach judges for metrics such as accuracy, relevance, and toxicity to any variation. Sampling rates can be configured, and the resulting scores appear in the Monitoring dashboard alongside operational metrics such as latency and cost. These signals should be regarded as indicators of relative change rather than absolute truths. AgentControl displays them per variation, making it easy to compare whether a variant actually outperforms the baseline without building custom analytics. When used together through Guarded releases, they drive gating decisions automatically, pausing rollout exposure or triggering rollback when quality thresholds are violated without requiring manual intervention.
Safety evaluation typically focuses on detecting risks related to personally identifiable information (PII), toxicity, and compliance violations. Deterministic detectors such as Presidio are often used alongside probabilistic classifiers and cloud DLP services to reduce false negatives. In addition, evaluation systems can attach automated judges to monitor safety signals. For example, AgentControl Online Evaluations can apply toxicity judges to sampled responses and surface the results in monitoring dashboards.
The following simplified example illustrates how evaluation signals can be computed by the application and emitted as events to support configuration-driven gating decisions. In this pattern, scoring logic remains inside the application, while promotion or rollback behavior is governed through configurable rules.
Evaluation signals are computed by the application and emitted as events to support configuration-driven gating decisions. When grounding accuracy falls below the configured threshold, guarded rollouts automatically pause the variant and restore the baseline, without requiring manual intervention.
Experimentation and feature flags
As soon as evaluation and guardrails are implemented, experimentation ceases to be treated as such and is instead fully integrated within the system's daily cycle. The state of the pipeline at this stage is not “trying out methods and praying for the best” but an incessant, subtle, and well-managed learning process.
In practice, RAG-based experimentation is rarely isolated to a single variable. Adjustments in one area often influence others. For example, increasing retrieval depth changes the volume of context supplied to the model, graph traversal affects which documents are visible, rerankers modify relevance ordering, prompt changes alter tone and structure, and switching models impacts latency and cost. These dimensions interact, which makes controlled experimentation and careful gating essential.
AgentControl configs make these interactions explicit and controllable. Each variation represents a complete configuration—model, prompt, parameters, and tools—that can be tested against others under controlled traffic allocation, allowing multiple variables to evolve under bounded exposure. Traffic allocation and evaluation thresholds are managed through AgentControl configs, while Guardian-guarded rollouts enforce rollback conditions automatically when metrics indicate regression. The pipeline decides at runtime which choices to make instead of sending out a new deployment every time there is an idea to be tested. The code remains unchanged; only the behavior changes.
Each configuration change becomes a small, bounded experiment with a clearly defined blast radius and rollback path. Every meaningful decision in the pipeline is externalized to AgentControl configs. Multiple variations evolve safely under controlled exposure, with built-in metrics showing which performs better, no custom instrumentation required. From the application’s perspective, this process is straightforward: On each request, it simply retrieves the active configuration and executes accordingly.
The following simplified example demonstrates how multiple pipeline parameters can be externalized as configuration variables. Rather than hard-coding retrieval depth, graph traversal limits, reranker activation, prompt versions, or model variants, these values are resolved at runtime, enabling controlled experimentation and gradual rollout. In this pattern, retrieval depth, graph expansion, reranking behavior, and model selection are resolved together as part of a versioned AI configuration rather than managed as unrelated flags.
In this pattern, experimentation occurs by adjusting configuration values and traffic allocation rather than modifying orchestration logic.
Key Insight: No redeployment is required to adjust retrieval depth, switch prompt variants, or test new models.
Configuration determines runtime behavior, while evaluation metrics determine whether those changes persist. For example, an config with two variations might include:
- Variation A (Baseline): GPT-4o-mini, temperature 0.3, concise prompt
- Variation B (Experimental): Claude 3 Haiku, temperature 0.5, detailed prompt with citations
Use percentage rollouts to send 10% of traffic to Variation B, then compare token cost, latency, and quality metrics in the LaunchDarkly dashboard before promoting.
The diagram below illustrates how an experiment progresses from limited exposure to promotion or rollback based on measurable thresholds.
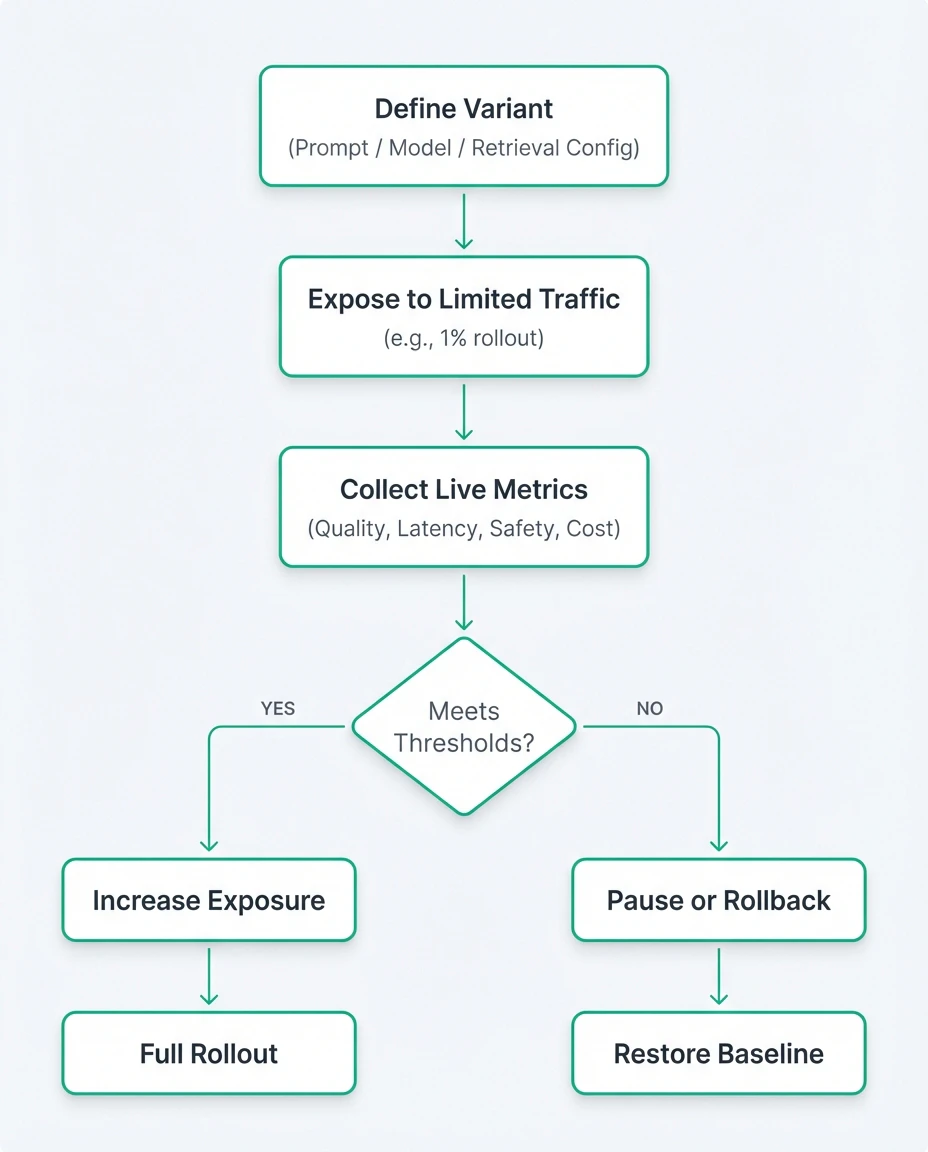
At this stage, experimentation becomes a routine, low-risk operational activity rather than an ad hoc process with uncertain production impact. Variants are promoted only when metrics validate improvement; otherwise, rollback restores the baseline automatically. Decisions are governed by thresholds and enforced by configuration logic, not by informal coordination or manual caution.
In practice, this shifts how teams manage risk. Engineers can test ideas earlier and under real traffic, while product teams receive measurable feedback instead of speculation. When regressions occur, as they inevitably will, the system absorbs them predictably through rollback mechanisms rather than escalating into production incidents.
This is not experimentation for its own sake. It is controlled exposure, enforced by configuration and measurable thresholds rather than personal discipline alone.
Deployment and rollout
In AI pipelines, notably RAG systems, deployment and rollout are the key operational milestones that support controlled execution and minimize the risk of production disruptions. Deployment refers to changes in code or infrastructure. Rollout, by contrast, refers to the controlled exposure of new behavior in production, such as introducing new models or configuration variants gradually to reduce risk.
Separating deployment from rollout allows teams to validate behavior changes incrementally under real traffic conditions. Take, for instance, a new LLM version rollout: Start with a small percentage of traffic and track grounding correctness and latency. If metrics remain healthy, exposure can be increased. If issues emerge, rollback is immediate and configuration-driven.
LaunchDarkly controls these rollouts through AgentControl Configs percentage-based targeting, and segment rules, with Guardian guarded rollouts that automatically pause or roll back based on quality signals. Exposure is increased only when metrics confirm the new variation is safe. Actual deployment is handled by infrastructure tools such as Kubernetes or Docker, while LaunchDarkly acts as the rollout control layer, managing fallback routes and ensuring configuration consistency across services. For example, retrieval config updates might be first shown to beta users and later on rolled out based on performance.
Here is a Python example that uses the LaunchDarkly SDK to manage the rollouts dynamically in your pipeline.
This setup allows rollout percentages, targeting rules, and cohort segmentation to be adjusted directly through configuration. Exposure can be increased incrementally under live traffic, while evaluation metrics determine whether promotion continues or rollback is triggered.
Separating deployment from rollout ensures that behavioral changes are introduced gradually and reversibly, reducing production risk while maintaining iteration speed.
Cost and latency optimization
Complex queries usually call for the use of models of higher capability to satisfy the quality requirement, which usually means longer latency and more cost. On the other hand, many requests can be handled with lower-cost paths when quality signals remain within acceptable limits.
This is fundamentally about dynamic optimization. Possible strategies include routing queries based on complexity, caching frequently accessed results, adjusting retrieval depth, and batching requests where appropriate. These techniques aim to balance accuracy, latency, and cost rather than optimizing any one dimension in isolation.
In practice, routing policies and cost controls can be governed through AgentControl configs targeting rules. Requests can be routed based on attributes such as user tier, region, or query characteristics. For example, complex queries may be sent to a larger model such as GPT-4 while simple lookups are routed to a smaller model, and different retrieval or reranking strategies can be applied to different traffic segments, all without modifying application code.
A complexity classifier provides a practical example of cost-aware routing in production AI systems. Rather than routing all requests to the most expensive model and deepest retrieval path, the system evaluates incoming queries and dynamically selects an appropriate tier.
Routing decisions are not hard-coded. Instead, configuration flags determine tier selection and threshold limits. This allows routing behavior to evolve safely under live traffic without redeployment. In practice, complexity classifiers should be treated as heuristics and continuously calibrated using production metrics.
Below is an illustrative example of cost- and latency-aware routing controlled through configuration.
In many production deployments, routing decisions can also be managed directly through AgentControl config targeting rules. For example, different model tiers may be served based on user subscription level, geographic region, or environment without requiring custom routing logic in application code.
This pattern allows teams to adjust routing tiers, thresholds, and fallback behavior dynamically. Lightweight requests can be served at lower cost and latency, while complex queries are automatically escalated to higher-capability paths. Performance and quality remain observable and controllable through configuration.
The diagram below illustrates how routing decisions move between lightweight and high-capability paths based on configuration and runtime signals.
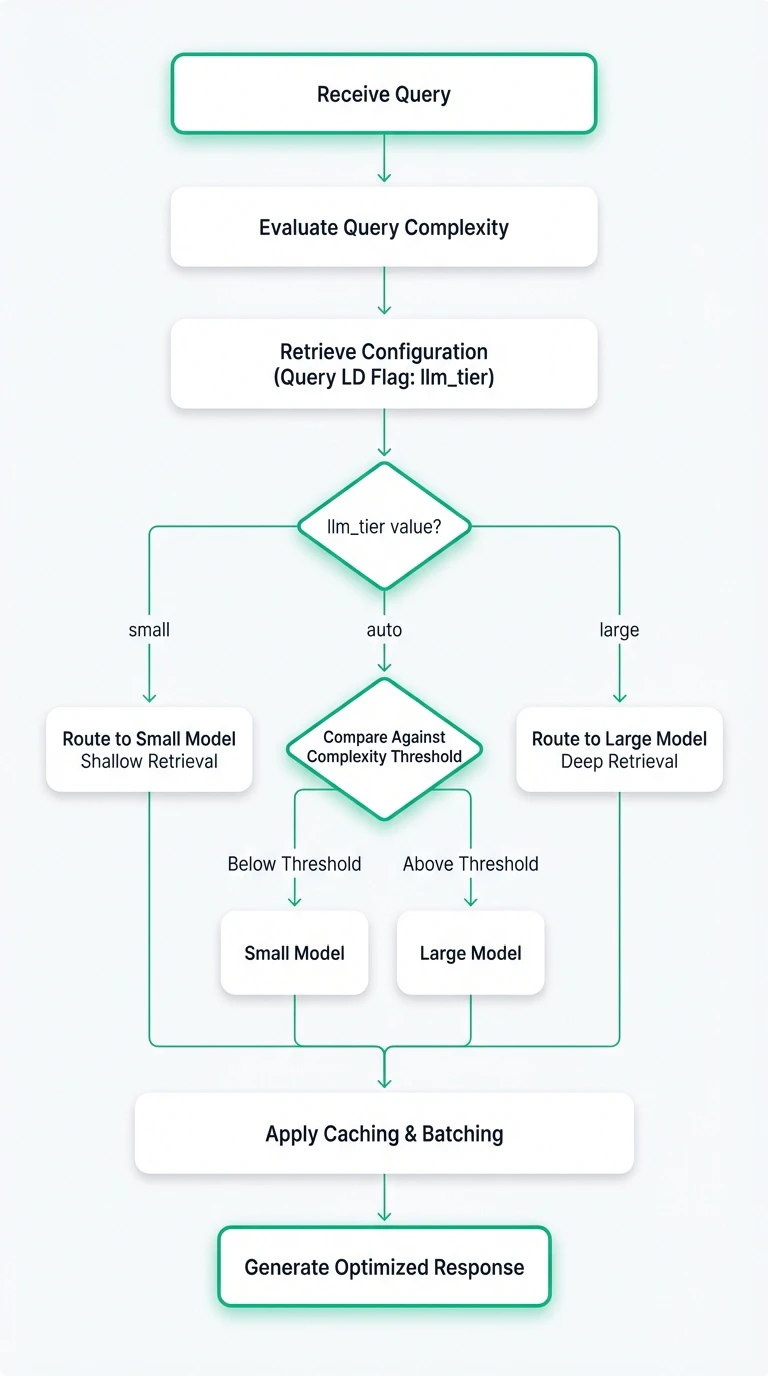
The lightweight path (small model with shallow retrieval) and the high-capability path (large model with deep retrieval) converge before caching, batching, and final response generation. This ensures that cost optimization does not fragment the delivery pipeline and that observability remains consistent across tiers.
Monitoring and observability
In every production RAG pipeline, performance monitoring is a must-do process that helps you discover issues before they get out of control. To do this, it is necessary to monitor the most important metrics, which include retrieval drift, grounding accuracy, hallucination rates, and related reliability signals. Latency spikes and the overall health of the API will be monitored as well. In practice, these metrics should be tracked over time and analyzed across percentiles (e.g., p95, p99) rather than relying solely on averages.
These observability signals will then be incorporated into your control plane, for instance, LaunchDarkly, to automate actions such as rollbacks or switching to safe-mode configurations whenever things go wrong. Observability provides the signals; AgentControl configs enforce the decisions. When grounding accuracy drops below the threshold, AgentControl configs can automatically shift traffic back to the stable variation without waiting for manual intervention.
Why invest in continuous monitoring? Because RAG systems are inherently dynamic: models evolve, underlying data shifts, and user behavior changes across contexts. These factors can gradually degrade performance in ways that are not immediately visible. Continuous monitoring is necessary because regressions often become apparent only after affecting end users. Early detection of hallucinations or accuracy drops allows issues to be addressed proactively, improving reliability without constant manual intervention.
Telemetry data can be collected through vendor-neutral observability frameworks such as OpenTelemetry or through an organization’s internal monitoring infrastructure. AgentControl configs also provide a built-in monitoring dashboard that surfaces variation-level metrics automatically, allowing teams to compare model and prompt performance across experiments without additional instrumentation. The dashboard reports metrics such as token usage, cost, latency, and quality scores for each configuration variant. These metrics can then be used by rollout controls to suspend, promote, or roll back configurations when thresholds fall outside acceptable ranges.
For example, if the performance of the grounding deteriorates, LaunchDarkly will immediately unmask the experimental model and pull the reranker back to reliable settings, depending solely on the live data. The intervention should be driven by predefined thresholds and rules defined per metric rather than by a single global criterion, and not by unpredictable human interference.
Shown below is a Python snippet that demonstrates feeding metrics into LaunchDarkly for decision-making purposes.
When AI requests are executed through the AI SDK, operational metrics such as token usage, cost, latency, and success rates are captured automatically using the track_openai_metrics() instrumentation. These signals appear in the AgentControl monitoring dashboard alongside evaluation scores and configuration variations, enabling teams to compare model and prompt performance without building custom analytics pipelines.
Using observability data to inform LaunchDarkly controls makes your pipeline adaptive. Teams get traceability, faster incident response, and safer production iteration by clearly separating metric computation from configuration enforcement.
To help you visualize, here's a flowchart of the observability pipeline.
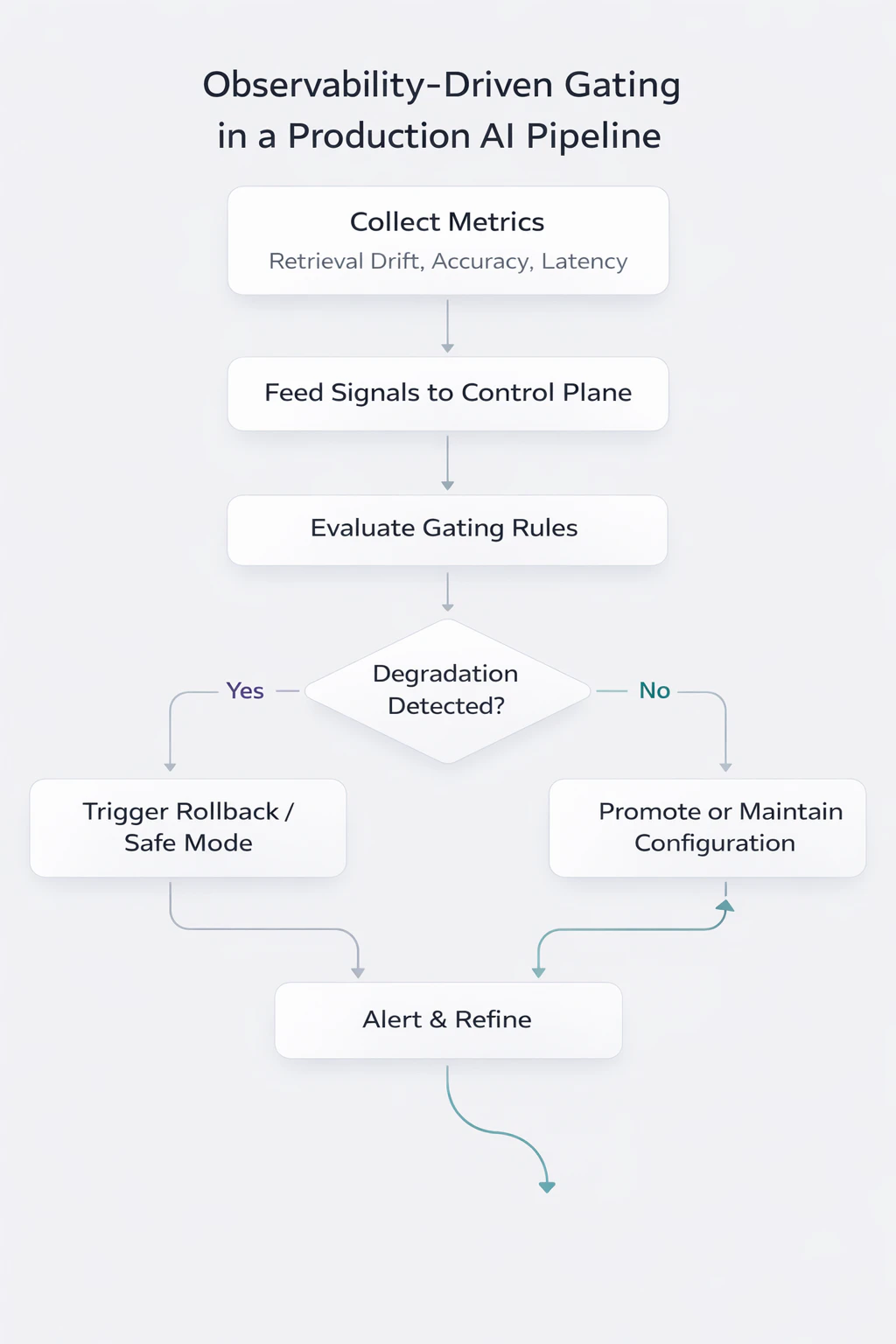
Observability metrics feed directly into configuration-driven gating rules, enabling automatic rollback or promotion without manual intervention. The control plane does not compute metrics itself; it enforces decisions based on thresholds defined in configuration.
Feedback and iteration
Closing the RAG pipeline loop involves activating structured user feedback, such as ratings, error logs, and usage traces, and feeding these signals back into retrieval, prompt, or model adjustments. AgentControl configs then controls the release of refined configurations. New prompt variations can be tested on a small percentage of traffic, evaluated against satisfaction metrics, and promoted only when signals confirm improvement, ensuring that they are tested under limited exposure before broader rollout. This promotes a never-ending process of evolution with closely-knit feedback loops, allowing you to quickly iterate while still having a solid production environment, without requiring broad, unmanaged production changes.
In practice, these feedback signals can be sourced from RLHF-derived signals, user feedback systems, satisfaction metrics, or built-in telemetry. LaunchDarkly coordinates the rollout of the updates, managing the exposure or reversions depending on the feedback received.
Feedback signals such as lower satisfaction scores, increased clarification requests, or higher error rates indicate that users struggle with the new prompt format. The new prompt variant can be kept in evaluation-only mode, allowing time to refine and retest through online evaluations, automated or semi-automated assessments run on live or shadow traffic, before any wider rollout.
Here's a Python snippet to integrate feedback signals with LaunchDarkly for adaptive rollouts.
The method used here makes the iterations both data-driven and lower-risk. Teams blend the feedback with the same setup and launch discipline as other pipeline modifications, thus preventing ad hoc decision-making and ensuring that the system behaves predictably even while it is being continuously evolved.
Last thoughts
Production AI systems rarely fail because a model is imperfect; they fail because change is unmanaged. In RAG pipelines, even small adjustments to retrieval depth, reranking logic, prompt structure, or model routing can compound quickly under real traffic. When those decisions are embedded directly in code, iteration becomes slow, risky, and difficult to reverse.
The goal is not to freeze behavior but to externalize it. AgentControl configs provide that external control surface: versioned configurations, percentage rollouts, automatic metrics, and instant rollback. When configuration, experimentation, evaluation, and rollout are treated as first-class architectural concerns, change becomes measurable and reversible. Teams can introduce improvements incrementally, observe their impact under real conditions, and roll back regressions without destabilizing the system.
Unlike general-purpose feature flag workflows, AgentControl configs are designed specifically for runtime AI configuration, combining prompt versioning, automatic metrics tracking, and online evaluations in a single control surface. Unlike broader MLOps platforms, it focuses on operational behavior in production rather than training pipeline management.
The more dynamic and compositional AI systems become, the more valuable controlled change becomes. Production RAG is not about finding a perfect configuration. It is about building a system that can evolve safely, intentionally, and continuously. AgentControl configs make this practical, giving teams a single place to manage model selection, prompt engineering, and quality evaluation, with the safety nets needed for production AI systems. Get started with the AgentControl Quickstart or explore the Python AI SDK for implementation examples.