The gap between something going wrong with a production AI system and getting the right fix live has never been zero. An alert fires, someone diagnoses the cause, a decision gets made, the fallback goes live—and users are experiencing the problem throughout. For traditional software, that gap is at least bounded: Behavior stays stable between deploys, and the sources of change are largely things you shipped.
Agents don't work that way, as agents and models are inherently unpredictable and indeterminate. Model checkpoints update on the provider's schedule, provider health fluctuates, and environment changes that nobody on the team initiated can shift behavior that was working reliably the day before. The gap between detection and response is the same as it always was, but the surface area for something going wrong is much larger, and most of it is outside your control.
Most teams running agents in production have already defined what to do when something goes wrong: a fallback model with a backup provider, a more conservative configuration for when the primary fails. The alternative is there, already wired up. What's been missing is the mechanism that activates it at the moment the signal arrives, without waiting for someone to make the call. Today, we’re happy to introduce the missing piece.
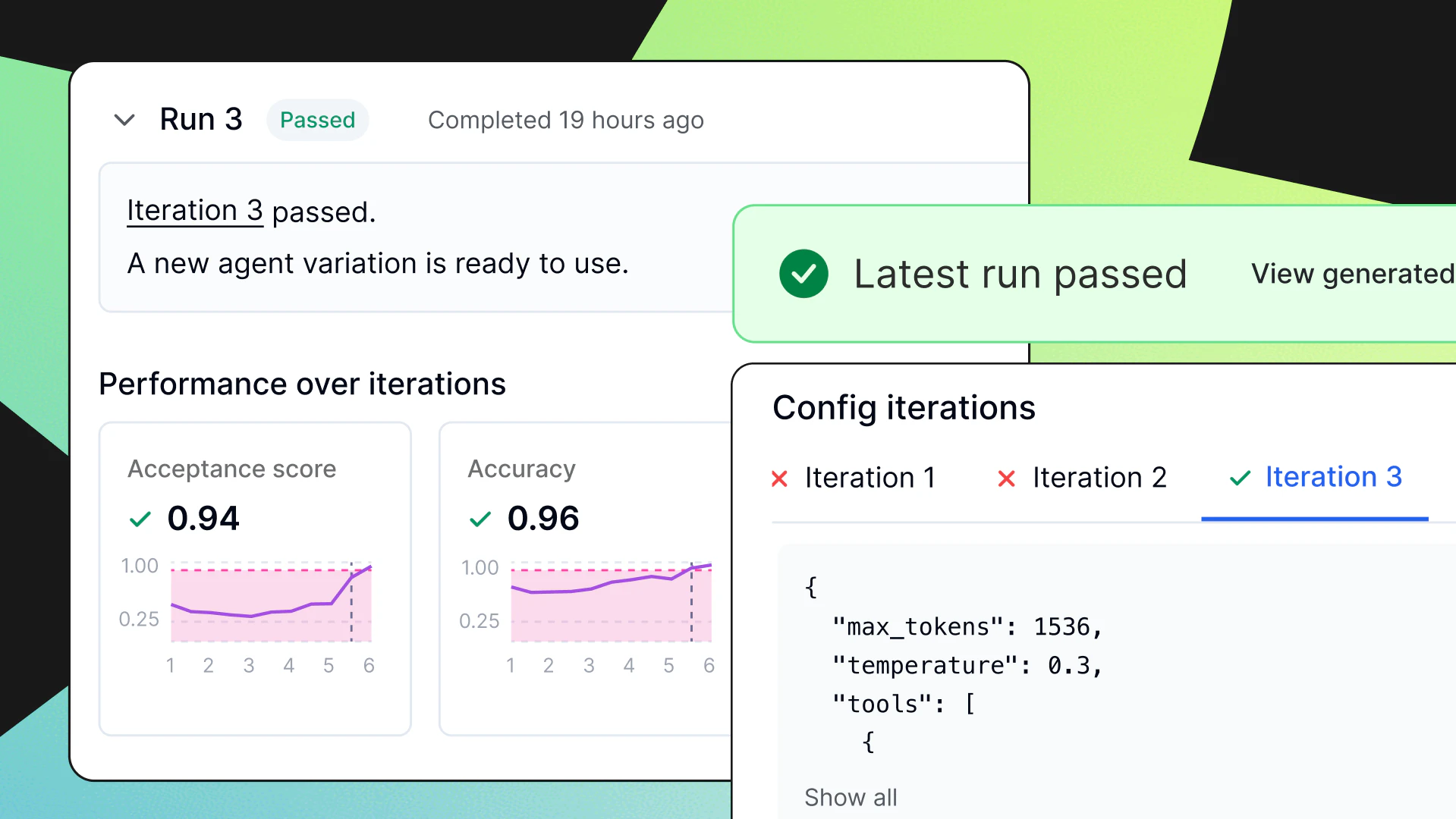
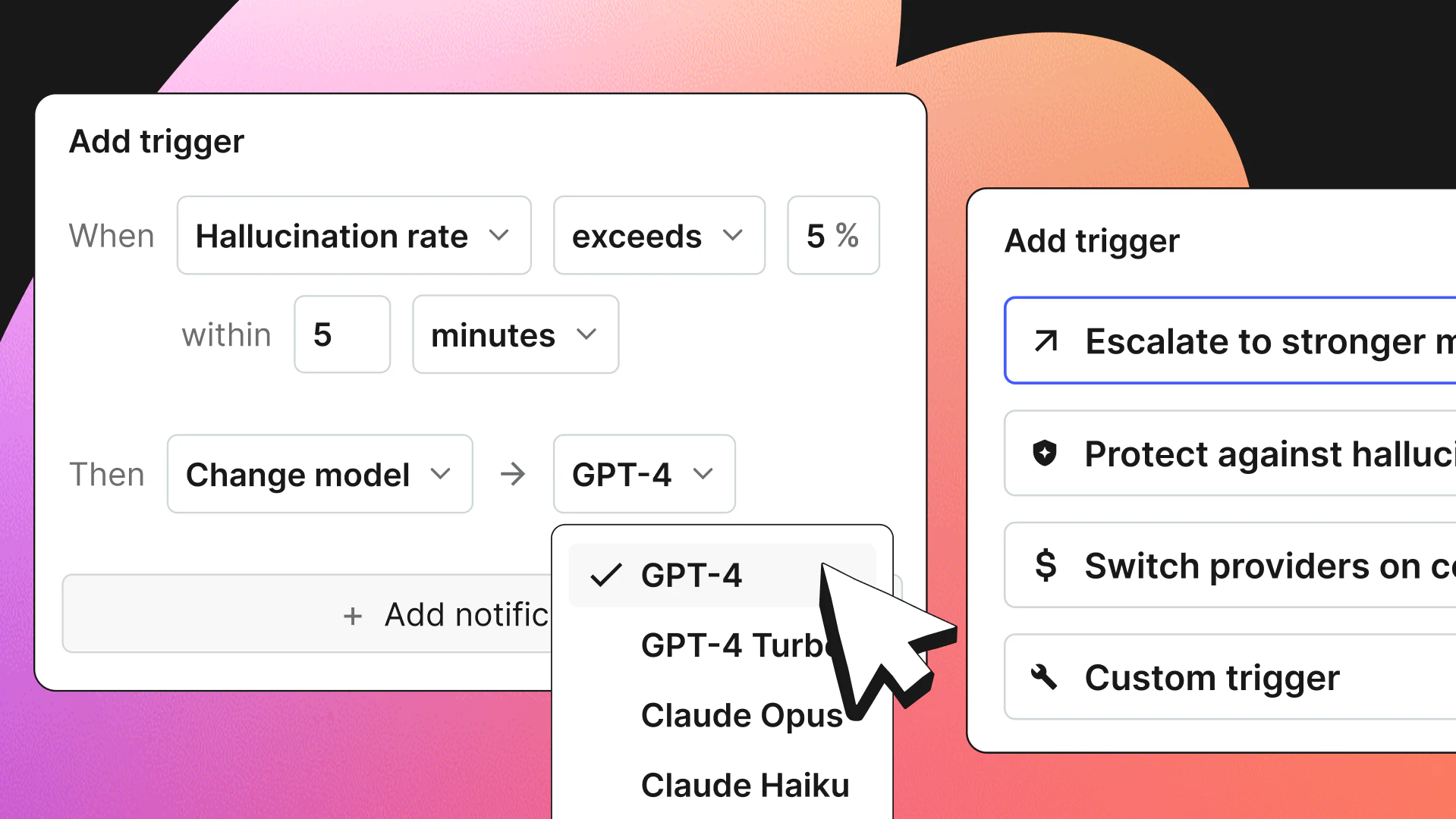
Adaptive Triggers is now available in closed beta. Teams define a rule directly on a config: When a monitored metric breaches a threshold within a time window, switch to a specified variation. When the threshold is crossed, AgentControl makes the switch automatically, with no human in the loop.
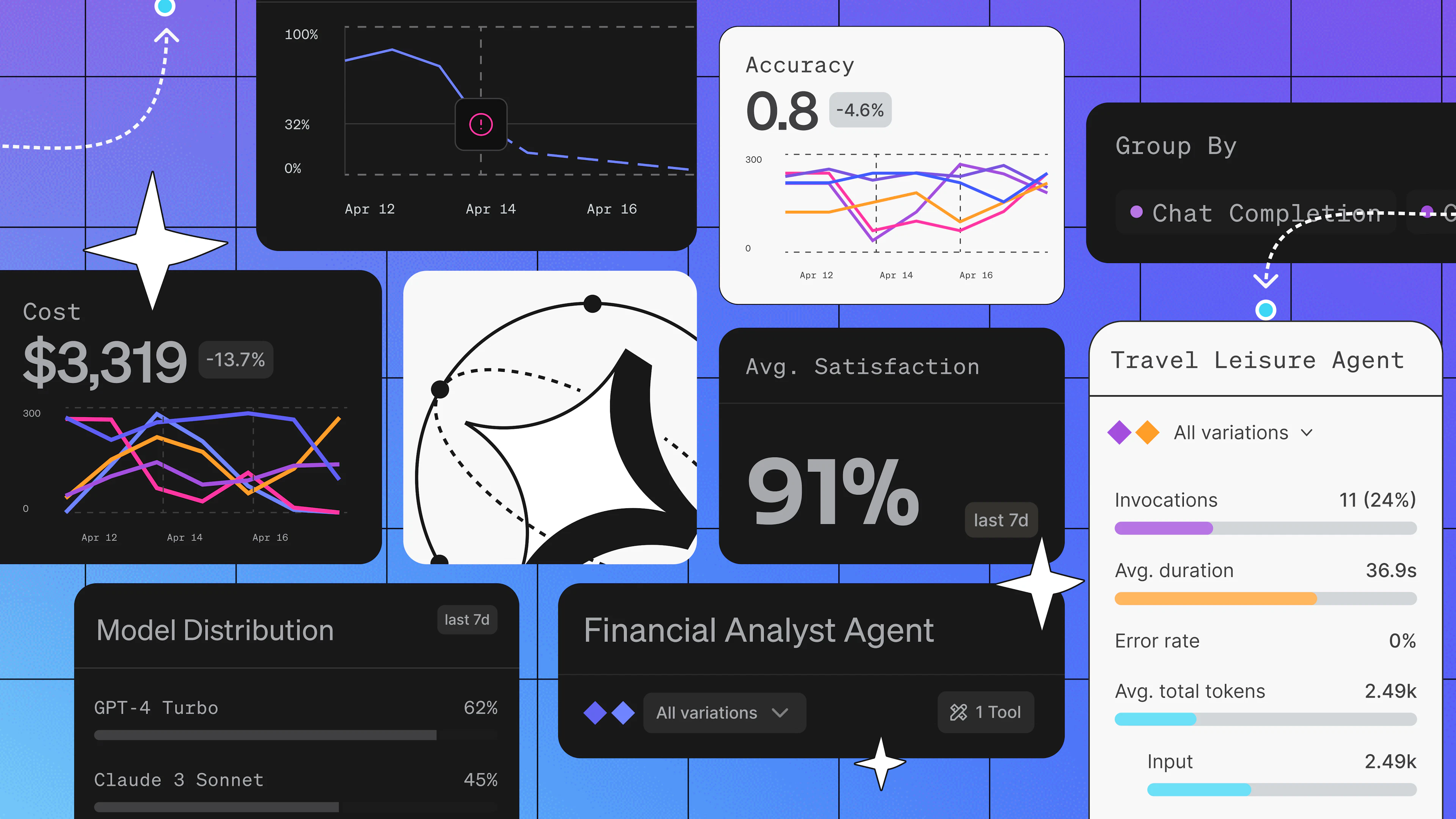
A team running their agent on Claude Sonnet hosted on AWS Bedrock has a backup variation configured to route the same model to GCP Vertex. When Bedrock error rates climb past the configured threshold (say, more than 10 failures in five minutes), the trigger fires. AgentControl switches the default variation to the Vertex configuration and traffic reroutes. The experience is uninterrupted, and nobody gets paged.
The response that doesn't wait
What makes the switch instant isn't only that it's automated. Because AgentControl controls the configuration layer, the fallback variation has already been pulled by the SDK and is instrumented in the running system. When the trigger fires, there's nothing to build and no deployment to kick off. The switch happens in under 200 milliseconds because AgentControl sits inside the application, not between it and the model provider. The team made the decision about what to do in advance, and Adaptive Triggers executes it the moment the signal arrives.
Most tools can surface a problem or change a setting. Adaptive Triggers does both automatically, in real time, inside the same platform. The gap between seeing a production problem and responding to it closes when the response is already defined.
The direction from here extends to every signal in the observe-and-act loop: quality scores that drop below threshold, cost spikes that warrant routing to a lighter configuration, paired triggers that restore the primary variation automatically when metrics recover. The response that doesn't wait becomes a loop that runs on its own.
Adaptive Triggers is available in closed beta. Book a demo to request access.