Software can be a risky business. From downtime to bugs to botched deployments to security vulnerabilities, there are plenty of ways things can go wrong.
Despite these risks, the push toward agile workflows means developers are expected to deliver features and fixes at an ever-increasing pace.
Fortunately, automated DevOps practices offer us many opportunities—both pre- and post-deployment—to deliver quickly without sacrificing safety.
Let's take a look at what might go wrong—and how we can leverage our DevOps pipeline to make software production and delivery less risky.
Common risks
DevOps practices offer us automation, speed, and efficiency. But they don't inherently prevent our software from breaking in production. There are numerous reasons things can go wrong. Some of the most common reasons for failure are:
- Differences between development and production environments
- Inability to scale
- Software supply chain vulnerabilities
- Buggy code
- Insufficient monitoring
Fortunately, we can overcome all of these challenges through creative use of DevOps tools and practices.
Strategies for reducing risk
Leverage containerization and infrastructure-as-code
Containers are a great way to ensure that our software runs in a consistent environment. When we run our apps in containers, we no longer need to worry about differences between dev, test, and production. Containerized apps mean developers no longer have to fear things like deployment disasters stemming from a statement like, “Well, it worked on my machine."
Of course, containerization does us no good without reliable infrastructure for running them. Infrastructure-as-Code (IaC tools) let us define our production infrastructure using easy-to-understand templating languages. We can update our infrastructure code via pull requests—and even put it through code review to ensure we don’t actually provision a tiny Kubernetes cluster incapable of running our app at scale. To top it off, we can use our CI/CD pipeline to validate our IaC code and automatically provision new infrastructure as needed.
Your software supply chain
The tools and libraries we depend on as developers comprise our software supply chain. Unluckily for us, our software supply chain is a significant source of risk.
It only takes a single compromised dependency to expose sensitive application data. When we use open-source libraries, we’re often pulling hundreds of direct and transitive dependencies into our projects.
There’s no way to personally vet all the code we depend on. So how can we be sure there’s no malicious code lurking in our libraries? Fortunately, we can run dependency scanners like Snyk in our CI/CD pipelines to let us know if we’ve accidentally imported compromised code.
Libraries aren’t the only part of our supply chain we need to worry about. The container images that run our apps might also contain vulnerabilities. We’re in luck here, too. There are a wide variety of container scanners we can add to our CI/CD pipeline to catch container vulnerabilities before we push our app to production.
At the OS level, try to minimize the difference between the production and dev environments. If you use containers for your application, make sure that the containers are from a genuine source. Compromised containers at the OS level can expose applications to threats. To eliminate vulnerabilities, use a dynamic security scanner such as Acunetix to find problems at the earliest stage. Make sure you are adequately managing your secrets and that you haven’t exposed them. If you use containers and Kubernetes, CyberArk Conjur can be the right tool to manage all your secrets centrally.
Static and dynamic analysis
Your CI/CD pipeline is the last line of defense before your application makes it into production. This makes it the ideal time to run both static and dynamic analysis to detect problems.
Static analysis refers to analyzing application source code for errors and vulnerabilities. Static analysis tools help eliminate common code errors, such as buffer overflows and SQL injection. Apart from preventing buggy or insecure code from making it to production, static analysis tools also help developers write quality code and help enforce good coding practices and style. There are plenty of static analysis tools to choose from, both commercial and open-source. Many of them run inside a CI/CD pipeline.
In contrast, dynamic analysis scans code while it is running. Performing dynamic analysis during runtime empowers developers to examine specific features and isolated sections of code, including pieces of code that may not be executed during a static test. This is extremely helpful for practices such as unit and integration testing. Alternatively, it can run the entire application and test it from outside. Dynamic analysis is a critical step in the DevSecOps world because it controls the delivery of the application and ensures business logic and user experience are up to the mark before it goes into the production environment.
An example of this includes API testing and API vulnerability scanning. In the DevOps pipeline, you deploy your app to the staging environment first. Then, you run a series of tests on it, and if it succeeds, you deploy the app to production. If it fails, you abort the deployment, and the pipeline doesn’t push the incorrect code to production.
Monitoring and alerts
DevOps doesn’t end after an app is deployed.
One of the most critical aspects of a successful DevOps pipeline is monitoring. Monitoring lets us observe our apps and infrastructure and detect any issues that arise. Thorough monitoring is pivotal in helping prevent service disruption by catching errors before they become outages. We can even use monitoring data to forecast demand and scale up our infrastructure before we hit capacity limits.
Most monitoring services are integrated with multiple applications to send alerts. This way, in the event of an outage, an application notifies a DevOps team as soon as possible. The alert message can also include relevant information to help engineers narrow down the issue and save time.
Feature flags
Maybe you saw this one coming? Well, rolling out new features can be risky, as they can be buggy or vulnerable to threats. There may be times where you want to roll out a feature to a few users without affecting the experience of other users. How can you do that with ease? Feature flags.
A feature flag allows you to enable or disable a feature without code deployment. You can set a condition on a feature of your app to make it either available or unavailable, depending on the situation. With feature flags, you don’t have to maintain multiple branches of code: Instead, the source code for any feature can stay in the primary branch because the flags decide what the end-user sees.
Feature flags can also control access based on the user. For example, you can enable a new feature in your test environment just for users in your organization to test it. More importantly, feature flags can be pivotal in minimizing disruptions if something fails in production because they can make the fix as simple as turning off the failed feature.
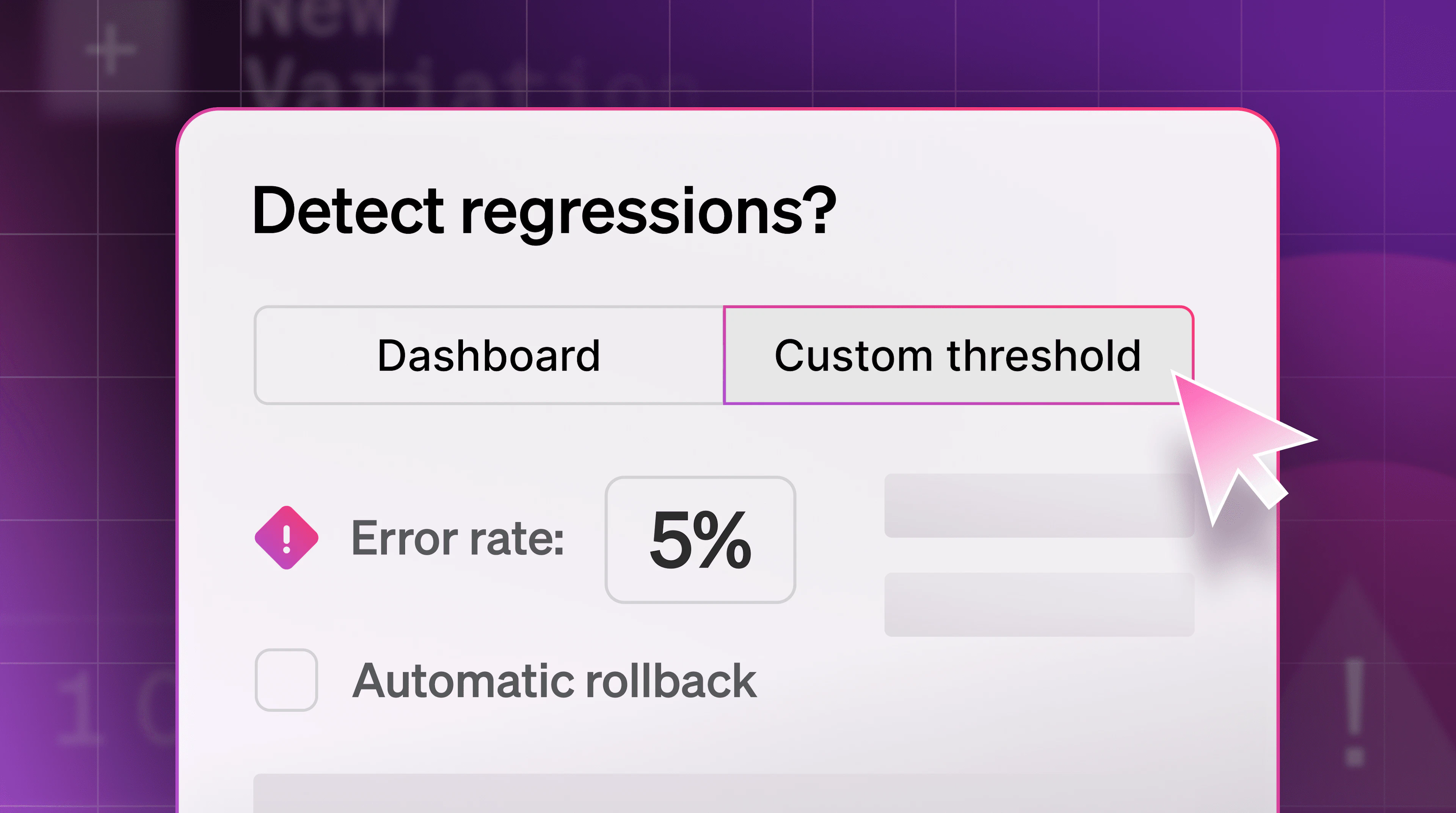
One of the most significant uses of feature flags is when you want to roll out a feature only to a subset of users first, then everybody. Feature flags are one way to enable canary deployments, where you want new features to be available only to a few users first so that they can be tested and checked before being made available to all users. If the code is faulty, all you have to do is turn off the feature, fix the code, redeploy, and re-enable the feature.
Feature flags let us extend our DevOps pipeline to runtime. We can make changes and disable buggy features with a single click instead of a slow redeployment. Feature flags work great with canary and progressive deployments strategies to minimize disruption and improve availability, which directly improves user experience.
Conclusion
Modern software development can be stressful. Developers and DevOps professionals are bombarded by a steady stream of news about vulnerabilities, breaches, and costly app outages.
But as we've seen, we shouldn’t lose hope! The right set of tools and practices can help us reduce risk and deliver safe, reliable, and secure software. Better yet, we can use our DevOps pipeline to automate risk mitigation—so we can spend less time chasing down bugs and breaches and more time developing features that delight our users.
Feature flags are an important (and underutilized) way to minimize application disruption to end-users and maximize productivity. They're software toggle switches that let us instantly enable or disable features. In addition, you can use them to serve content to specific users to meet various purposes conditionally. These widely used feature flags come in very handy when working with progressive and canary deployments. They increase efficiency by allowing you to switch on and off application features without deployments.
Best of all, you don't have to build and manage feature flags yourself. LaunchDarkly feature flag platform is a game-changer because of the agility and control it provides. Ready to learn more? Sign up for a demo.