An open-source session replay benchmark
An open-source session replay benchmark
Published October 17, 2023

Replaying user sessions is useful for analyzing performance regressions and understanding how users interact with your site. At LaunchDarkly, our core product is an open-source session replay tool built on rrweb. One obvious question, though, is about the performance implications of using such a tool on your site. After all, additional computation must happen to record dom interactions.
In this post, we’ll discuss the overhead of session replay with respect to resource consumption and interaction latency in several scenarios.
In all of our test cases, we found that when session replay was enabled there was a slight increase in the browser’s resource consumption as well as time to interaction, however, these changes were so minor that they didn’t yield a perceivable difference in the user experience.
It is important to note that we did not measure SEO-esque metrics such as Web Vitals, as these metrics can easily be manipulated by delaying the execution of javascript on the client. Instead, we focused on metrics that affect the browser while session replay is actually recording data (e.g. resource consumption and “time to interaction”).
If you’re interested in reproducing the experiment detailed below or want to learn more about how it works, you can find it here.
The Setup
To test session replay against a realistic web application, we created two applications that go hand in hand: A simple React application and a Node.JS application which automates and profiles interactions.
The React application accepts URL parameters which determine the number of elements to render in a list, with an optional parameter to enable session replay. When enabled, we would start recording using rrweb (the open-source library used by several companies, LaunchDarkly included).
The second is a Node.js program that uses Puppeteer to control this react application and collect telemetry data. Through Node.js, we were able to access Chrome performance traces and collect the data with Puppeteer. Specifically, we collected heap usage, CPU usage, and the time taken for each incremental addition.
The experiment was performed on an EC2 instance (t4g.xlarge) running Ubuntu 22.04.03 LTS with a 4-core CPU and 16 GB of RAM. We ran three trials:
- To measure interaction duration, we tracked time from insert beginning to end via the
window.performance.now()API. This metric shows how long it takes the web app to make a change in the UI. We want this value low to keep the rendering looking smooth. - To measure heap memory usage, we used puppeteer’s performance API which tracks the heap usage of the underlying chromium process.
- To measure CPU usage, we compared active computation time vs. total time to have an estimate of JS loop execution. A large amount of time spent in active computation would mean that not much is available towards other important JS execution, which could result in frame drop and render stutter.
By measuring duration, we wanted to measure the Interaction to Next Paint (INP) time, which tests the responsiveness of an application. According to Google Chrome Developers, an INP of under 200 milliseconds demonstrates a reliably responsive page.
The heap and CPU usage metrics depend on the user’s hardware. An increase in usage is not always a bad thing, but it helps to see how session replay will affect resource consumption.
Results
Test 1
In this test, there were 250 additions to a list, with an addition of 100 items each. On average, using session replay added 0.017 seconds to the time taken for each addition. Despite this, the INP remains much less than 200 ms, demonstrating that session replay maintains “snappiness” on a regular web application.
As more elements are added, the memory consumption difference with session replay increases. On average, there is a 6 MB increase in memory usage when using session replay. Session replay tools often optimize the memory usage. For example, LaunchDarkly buffers a short interval of events in memory before sending them to a web worker. The web worker offloads serialization and compression of the payload to avoid blocking the main javascript thread with the compute-intensive operations.
For the CPU usage, we compared the active times for enabled/disabled session replay against the total time of the enabled session replay run. For a given time, we wanted to see how more the CPU is active for each run. In this test, enabling session replay yielded an average increase of 21% more usage of the total time.
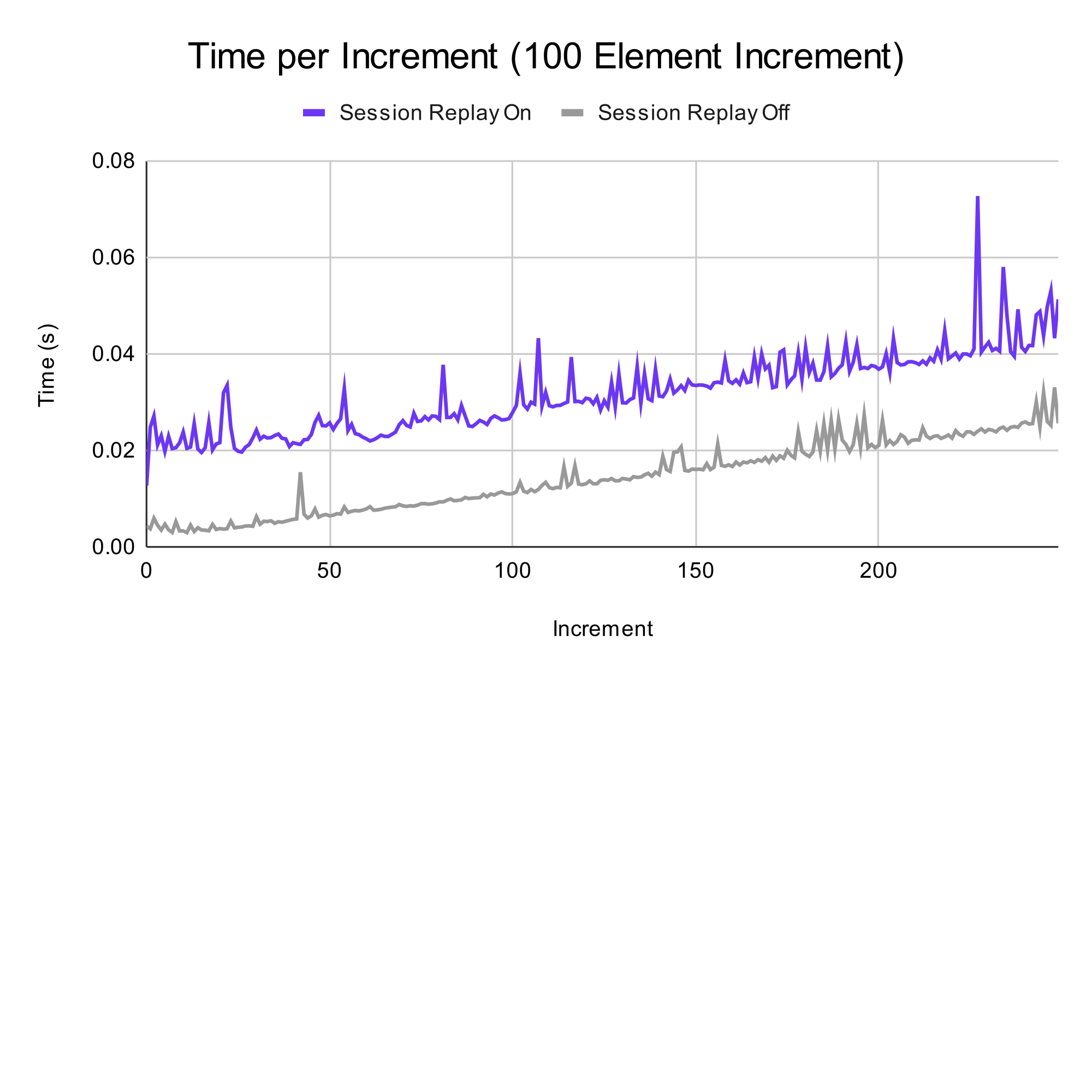
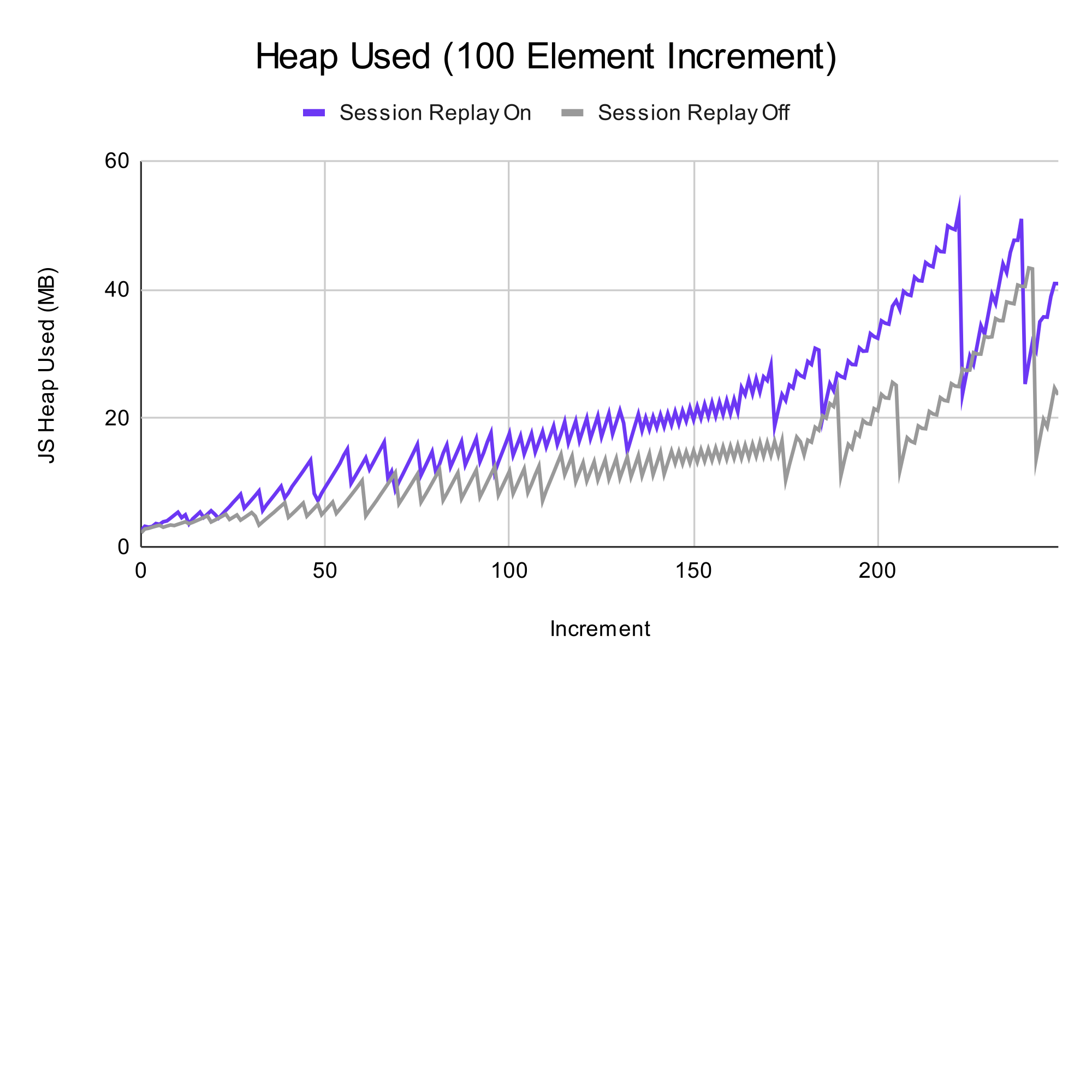
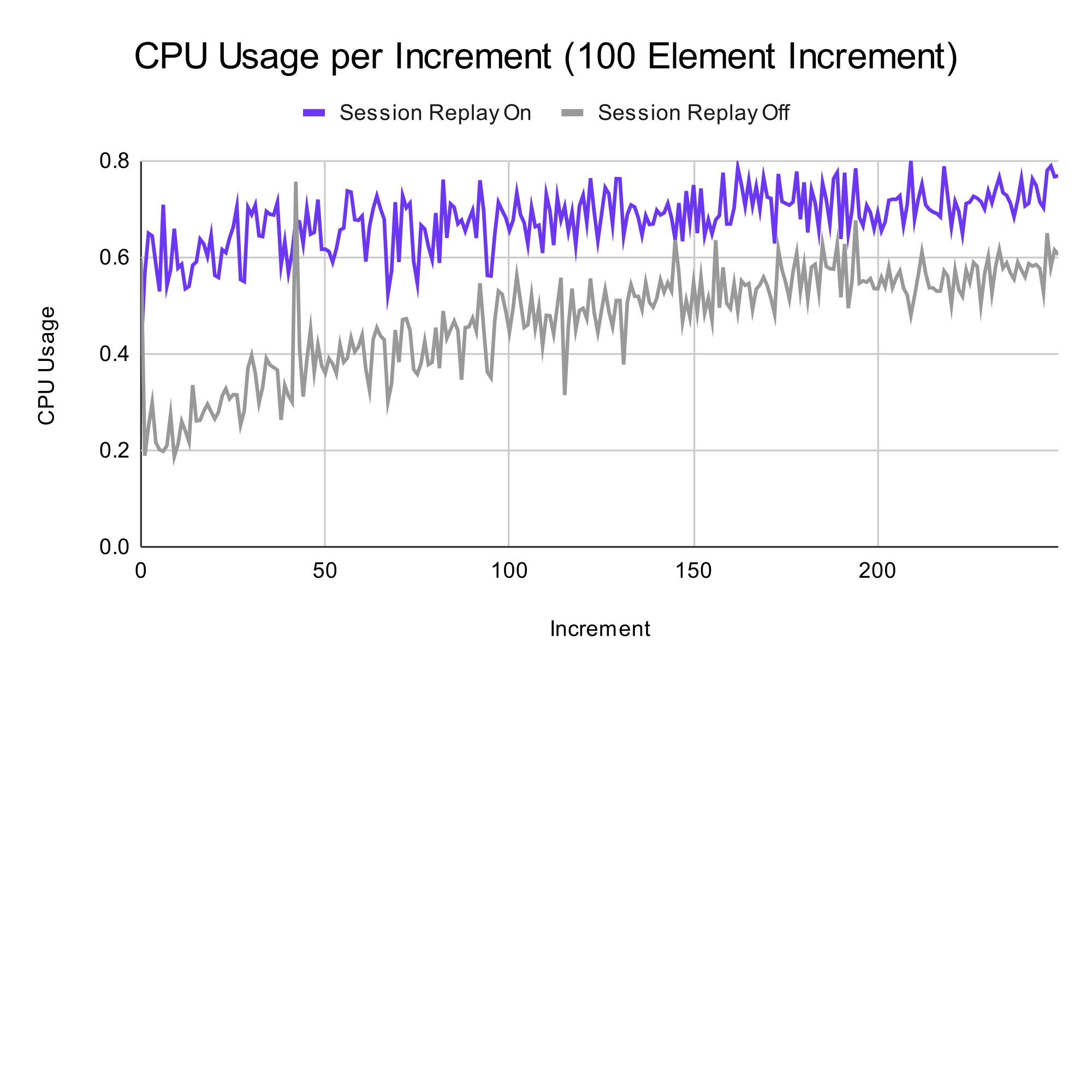
Test 2
In this test, there were 250 additions to a list, with an addition of 500 items each. On average, using session replay added 0.07 seconds to the time taken for each addition. Utilizing the 200 ms cutoff from before, we can see that enabling session replay maintains responsiveness until the 200th addition. More importantly, we can confirm that enabling session replay increases the duration of a task by a small constant amount. For this test, the addition is only 3.5% of the responsiveness window of 200 ms.
On average, there is a 60 MB increase in memory usage when using session replay, and for the CPU usage, enabling session replay yielded an average increase of 25% more usage of the total time. Again, these numbers are not necessarily negative and they could have different effects on various hardware.
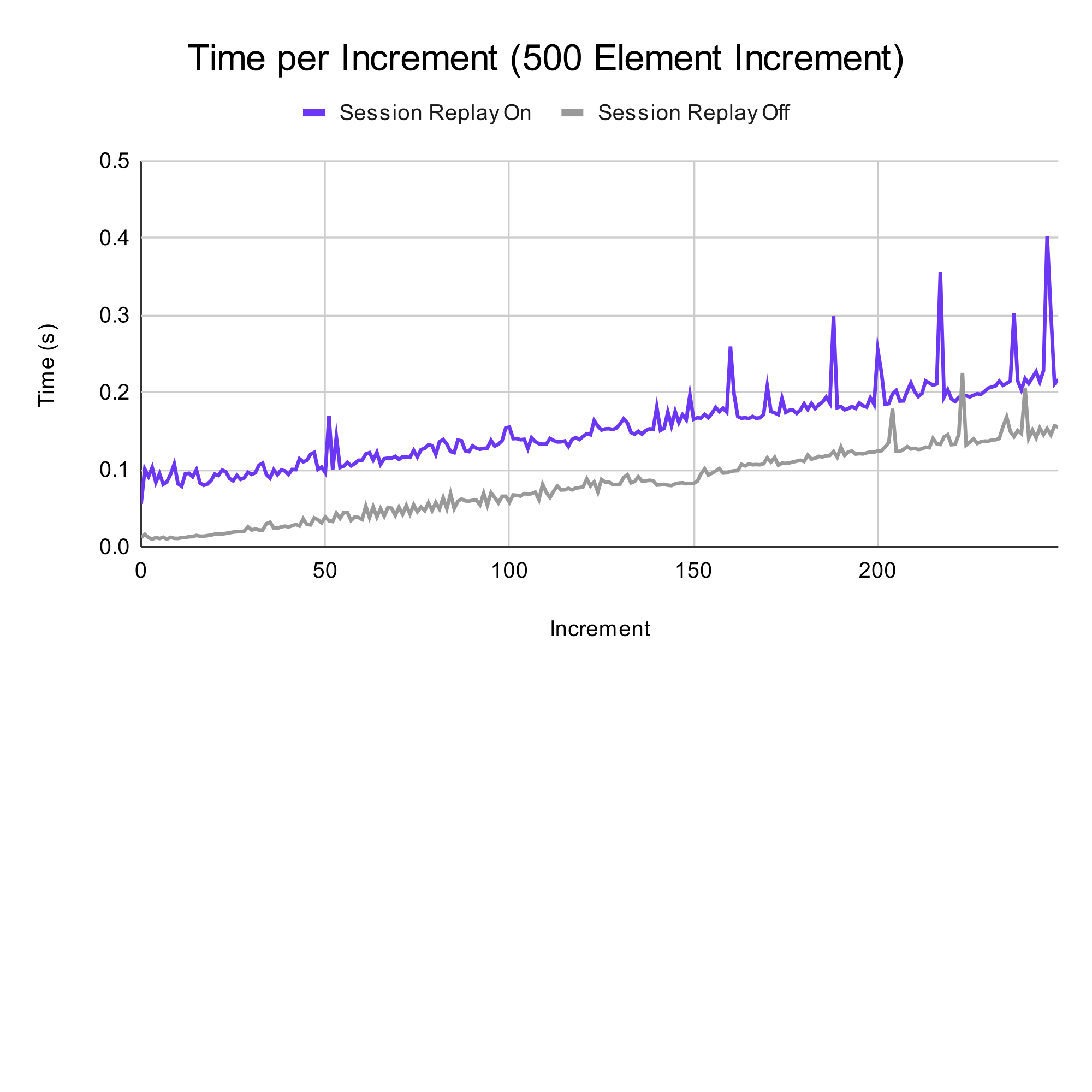
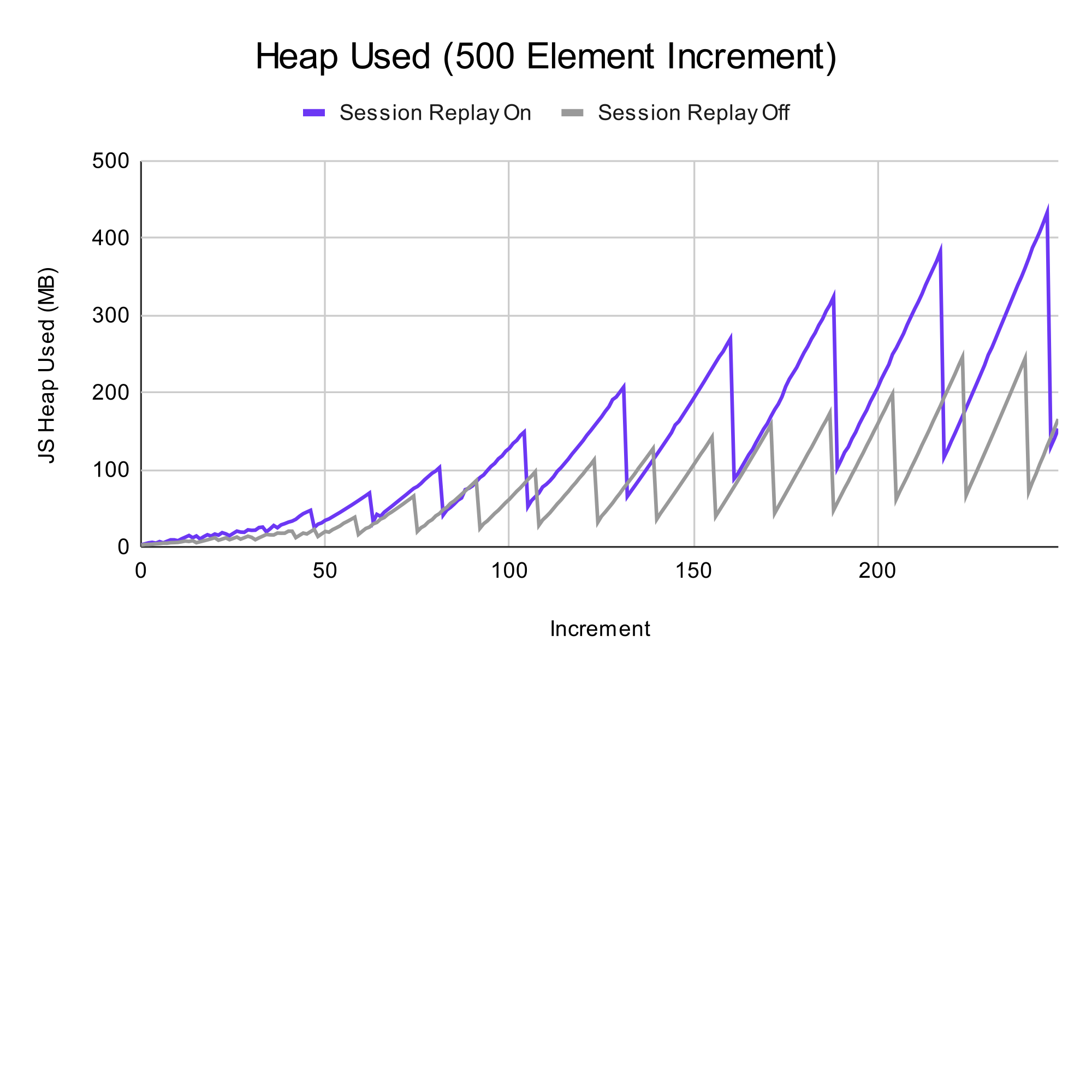
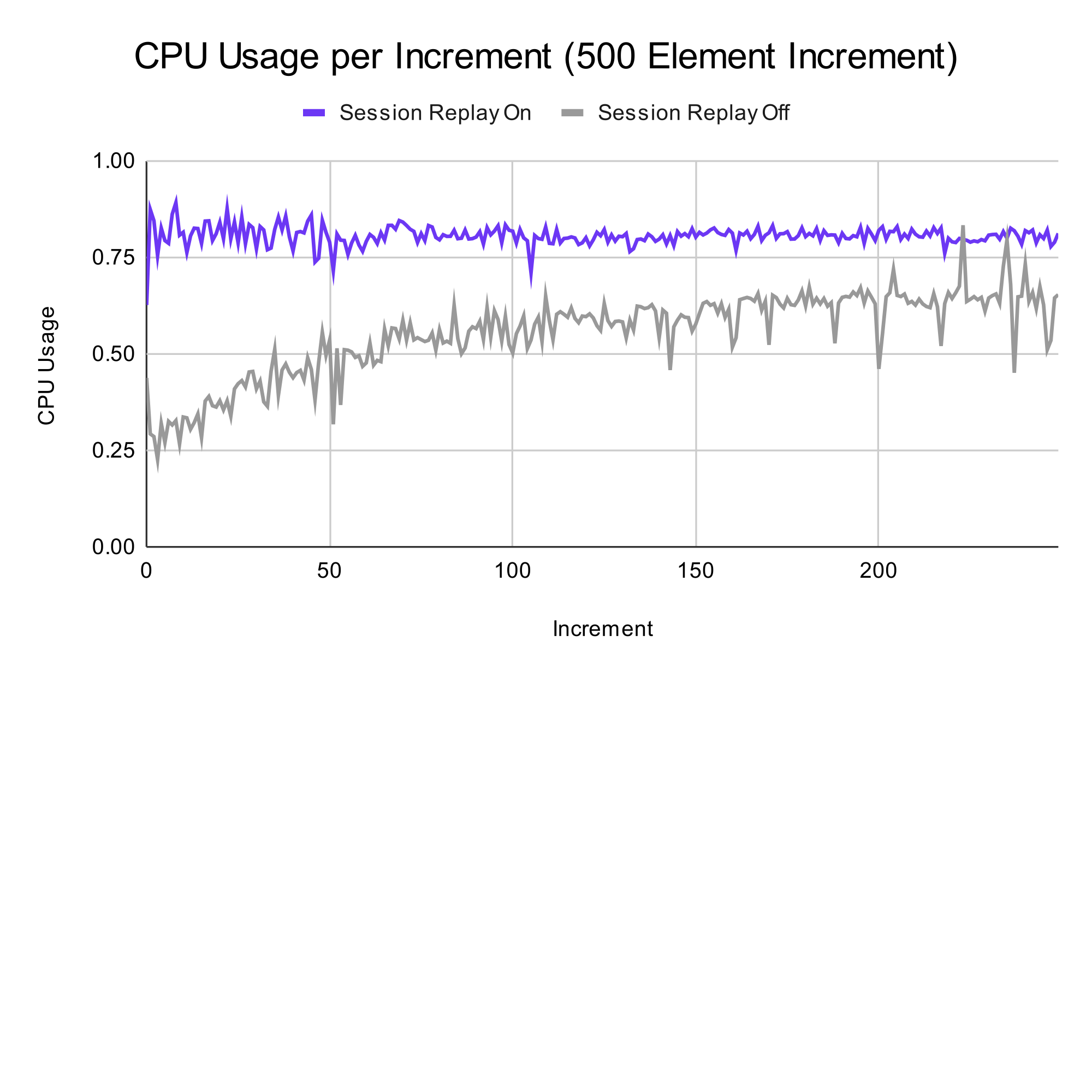
Conclusion
From the above data, while there is a difference in metrics when enabling session replay, we’ve noticed that there isn’t a very large hit to user experience, even on an extreme web app which renders hundreds of components at a time.
You may wonder how Session Replay can be so efficient. The secret lies in the optimal implementation in modern browsers which do the hard work of efficiently calculating how the DOM changes. Using the HTML Mutation Observer API to set up a callback doesn’t add much overhead to your javascript runtime; the only complicated bit is serializing the modified DOM nodes into a format that can be replayed.
One feature we wish to get to is profiling the inner workings of the Mutation Observer API itself to break down which parts of session replay (in rrweb specifically) actually cause the overhead we see. We’ve published this experiment on Github and we encourage you to run it yourself and share benchmarks on your respective devices. We’d love to see folks contribute as well!