
Dogfooding. Catfooding. Drinking your own champagne.
Whatever you want to call the act of an organization using its own software product internally, LaunchDarkly does that across multiple departments.
In this talk from our recent user conference Galaxy, LaunchDarkly Engineering Manager Lexi Ross explains how we leverage our feature management platform on API rate limiting, code migration, support ticket distribution, and more.
Maybe these use cases can inspire some fresh ideas about how you might be able to gain more leverage from LaunchDarkly. And if you already have some interesting examples for how your team is using our platform, we'd love to hear them: feedback@launchdarkly.com.
Watch the full talk below or check out the transcript.
Transcript:
Hi, everyone. My name is Lexi Ross and I'm going to be speaking about maximizing your use of LaunchDarkly.
So a bit of background on me, I joined LaunchDarkly about a year ago as an engineering lead. Prior to that, I was a software engineer at a variety of small startups. Here at LaunchDarkly, I manage the Feature Workflows team. We're building tools that let customers define repeatable flows for every step of a feature release. I'm a Bay area native living in Oakland, and outside of work I enjoy Olympic weightlifting, hiking, and riding my bike.
Now, let's talk about some unconventional ways you can leverage LaunchDarkly within your organization, to move fast with less risk.
If you're using LaunchDarkly to test in production, release to users progressively, and kill switch misbehaving features, you're already ahead of the curve, but it's likely there is even more value you can get from the platform.
We're going to cover six ways that we use LaunchDarkly at LaunchDarkly to manage features and mitigate risk: API rate limiting, code migration, infrastructure migration, targeting by SDK version, automatic trials, and support ticket distribution.

First, let's talk about API rate limiting. If you have a public-facing API, you're probably familiar with the need for rate limiting, but one size doesn't fit all when it comes to limiting the number of requests your customers can make. Here, we use targeting rules on a feature flag to set different rate limits based on the route and the method. In rule 10 above, we enforce a lower rate limit of 30 requests per minute for some of our admin endpoints. Rule 24 below is more of a catch-all. It gives us a 6000 requests per minute rate limit for all GET, HEAD, and OPTIONS requests, where the route starts with the string API. Note the use of RegEx there.
We can even rate limit by account. This customer, Customer A, has hundreds of environments so we needed to impose a lower rate limit on some of our endpoints that involve iterating through all environments. Because LaunchDarkly allows you to manage features without a deploy, we can use this flag to quickly move to rate limit customers who are using our API in unintended ways.
So how is this flag being evaluated? It's pretty simple; in this code snippet, which lives inside of a middleware, we're creating an anonymous user with attributes for method and route, and using that user to evaluate our rate limit flag. By using feature flags to manage API rate limiting, we're able to exert fine-grained control over how much traffic each of our endpoints receives, which helps us keep our service available for all customers.

Next, let's talk about a way we used LaunchDarkly for a major code migration. If you use the LaunchDarkly REST API, you might know that we allow you to make updates to flags and other resources, using a syntax called Symantec Patch. It's a way to specify the modifications to perform on a resource as a set of executable instructions.
Recently, we undertook a large rewrite of the backend system that pursues and executes those Symantec Patch instructions. This system manages almost all flight updates in LaunchDarkly, so if the rewrite went well there'd be no visible customer impact, but if things went wrong, customers could experience major issues so it was critical to come up with a smooth and incremental migration plan that minimized risk. Well, that meant using feature flags.
In order to migrate our backend from V1 to V2, we had to re-implement about 40 instruction types. Here, you can see we used a JSON flag, where each variation represented the set of instructions for which we were ready to use the new system. We had variations for none, some, a minimal set of instructions to test the new system, and all, which we progressively added instruction types to as they were migrated to V2.
So how did this work in our code? Well, we fetched the list of already-migrated instructions from the flag variation. Then, we made sure every instruction in the incoming patch was included in this list before deciding to use the V2 backend. By using feature flags, we were able to pull off this migration safely and smoothly.
We're also using LaunchDarkly to manage a massive database migration. We're currently in the midst of a zero downtime migration as some of our data from Postgres to CockroachDB, a commercial distributed sequel database. Migrations like this are always complex and risky, but we're mitigating that risk with LaunchDarkly.

Let's take a look at this targeting rule. First, some terminology. The four variations you see below refer to patterns for reading and writing data from the old Postgres versus the new Cockroach database. Mode A uses old only, Mode AB uses the old as a source of truth, but verifies against the new. Mode B on the other hand, uses the new only, and Mode BA uses the new but verifies against the old. So you can see here, we're 100% rolled out to BA Mode, so we're using Cockroach as a source of truth, but we're making sure the data matches our old Postgres database. We've bucketed this rule by account ID to ensure we're operating in the same mode for all requests by a given customer
You can also see this rule is targeted by datastore package and we're only serving this particular variation for the code rest package. Targeting by package allows us to use this flag to manage a complex migration across multiple packages, where each package might be on its own timeline. And of course, if anything goes wrong in production, we can immediately stop serving traffic to our new database by updating this flag, no deploy required. And so, using LaunchDarkly to manage this migration gave us the confidence we needed to execute this switch without causing downtime for customers.

Next, let's talk about using flags to manage SDK versions. LaunchDarkly maintains over 20 SKDs with updates and improvements added frequently. This means that some of our customers are using older SDK versions that might not support certain features. We can use feature flags to ensure that their application experience matches the SDK version that they have.
For instance, let's say we want to launch a dashboard in our web application for a brand new feature. Data will be populated in that dashboard via the SDKs, but we don't want to show the dashboard for customers on old SDK versions, their dashboards will be blank. So we add a targeting rule to the flag that controls this dashboard.
The rule says that a customer can see the dashboard only if they're on version 5.0.0 or above of the SDK. Note here our use of the Symantec versions comparison operator to express this rule. Even better, as soon as customers upgrade to that next SDK version, they'll automatically see the new dashboard. By using feature flags, we're able to stay nimble and flexible as we build new features, while at the same time ensuring that none of our customers have a degraded experience.
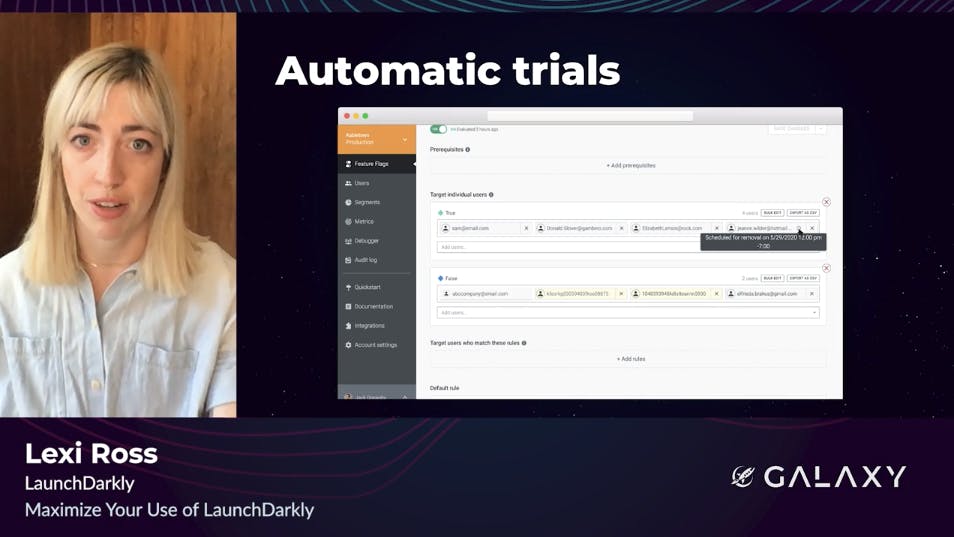
Next, we'll look at how we grant automated trials. Often, our revenue team needs to provision a trial of a specific feature for a customer. Let's say in this case, we want to give a customer access to experimentation for the next 30 days. We can use the individual user targeting feature to add that customer to the trial, but when it comes time to remove them, we used to have a manual process in which the account executive would create a calendar reminder to remove that customer from the targeting after the 30 day trial had lapsed, but this process was prone to human error. Sometimes, we'd accidentally give customers permanent access to features that we only intended for them to trial for a short time.
So, we recently began to use LaunchDarkly's new auto removal dates features for user targets to automate the process. When we add the customer to user targeting, we can also set a removal date. On that date, LaunchDarkly will automatically remove that customer from the flag. By using flags, we've made our trials process more accurate and streamlined, freeing up the revenue team to focus on customers.
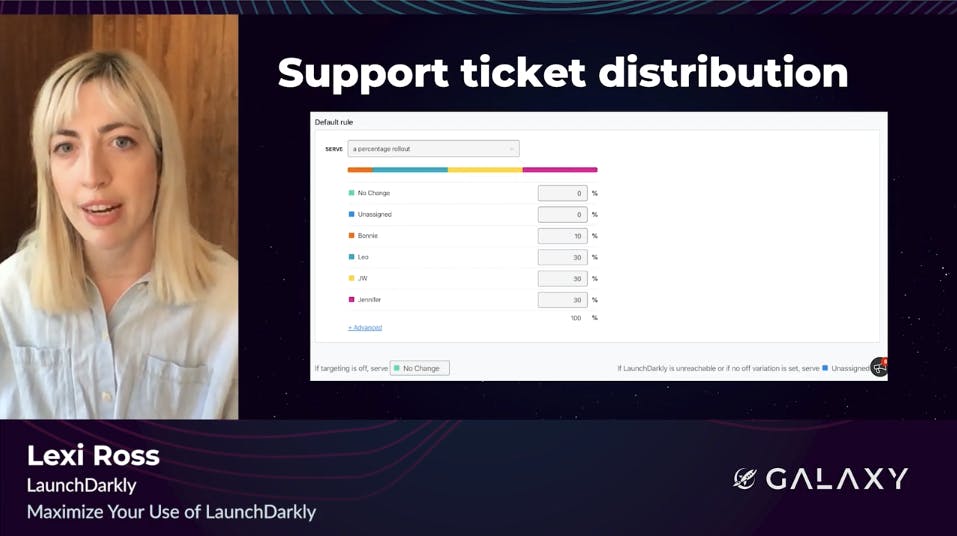
For our final example, let's look at a really creative way the support team at LaunchDarkly uses feature flags to manage their tickets. The support engineers at LaunchDarkly wanted a way to set a custom adjustable distribution for handling customer support tickets. Each variation on this flag represents an individual on the support team, like Leo or JW, and the percentage rollout determines what proportion of tickets should be assigned to that team member.
When a support ticket comes into Zendesk, it gets routed a note app that we have running on Heroku. This app is connected to the LaunchDarkly note SDK, which determines a variation based on the percentage rollout and reassigns a ticket in Zendesk accordingly. There's also some custom logic in that note app to offset the randomness of a flight evaluation and ensure that support engineers aren't getting assigned too many tickets in a row. Here, feature flags ensure a fair and even distribution of support requests, helping the support team do their best work.
That's all. I hope this talk inspired you to find more unconventional ways for your team to take advantage of feature management in LaunchDarkly. If you have any creative use cases for LaunchDarkly on your team, let us know at feedback@launchdarkly.com. Thanks for listening.















