Most engineering teams spent the last year figuring out what agents could do. Developers built a lot across different frameworks and approaches, and enough of it made it to production that a harder problem has taken its place: Building agents is no longer the challenge—operating them at scale is.
Unlike traditional software, where behavior is expected to remain stable after deployment, agents have no equivalent moment of “done” as agents and models are inherently unpredictable and indeterminate. With agents, behavior can degrade without a code change as model checkpoints update, environments shift, and something that worked reliably can drift without anyone on the team touching it. When something goes wrong, customers can feel it before anyone on the team does, and the standard response (find it, fix it, redeploy) is often too slow for a system that never stops running. The problem compounds when organizations are running multiple agents across different frameworks and codebases, with no shared standard for how any of it is governed.
Most teams running agents in production have invested in observability and generally know when something is wrong, but visibility into a problem and the ability to act on it fast enough to matter are different things. Layering monitoring on top of whatever framework the team started with (or assembling point solutions around it) still leaves the same gap: An alert tells you something degraded, but it doesn't act on it, and the controls needed to respond aren't in the same place as the data that surfaced the problem, which leaves teams well-informed about an issue but scrambling to fix it.
"More and more, developers are not just writing code. They are directing agents, which is fundamentally changing how work flows. GitHub is where that work actually happens: where people and agents build, review, and ship software together in a single system. The challenge is turning agent-generated work into code that can be validated, governed, and safely shipped to production. LaunchDarkly has been solving release governance for years, and AgentControl extends that to agentic workloads. Together, we give teams a real path to ship agents and agent-built software without losing governance, observability, or control. That’s what it looks like to scale responsibly."
— Mario Rodriguez, GitHub Chief Product Officer
AgentControl is the operational layer for managing agents in production. It runs on the LaunchDarkly flag delivery infrastructure, the same network handling 50T+ flag evaluations a day, which turns out to be well-suited to the problem: The things that shape agent behavior (prompts, models, parameters, tools) need to be updatable faster than a deployment cycle allows. Models and prompts can be changed in under 200 milliseconds, targeted to specific users, and governed from a single place across every team in the organization. LLM traces surface what's happening across agent invocations, and the platform connects that observability to the controls needed to act on it, so teams can catch quality, cost, and reliability problems before customers do.
"To deliver best-in-class AI agents to our customers, we need to keep pace with the latest frontier models. AgentControl lets us systematically test and upgrade our agents in production without waiting on a full deployment cycle."
— Zack Rossman, Senior Staff Engineer, Veeam
AgentControl covers the full agent lifecycle, including:
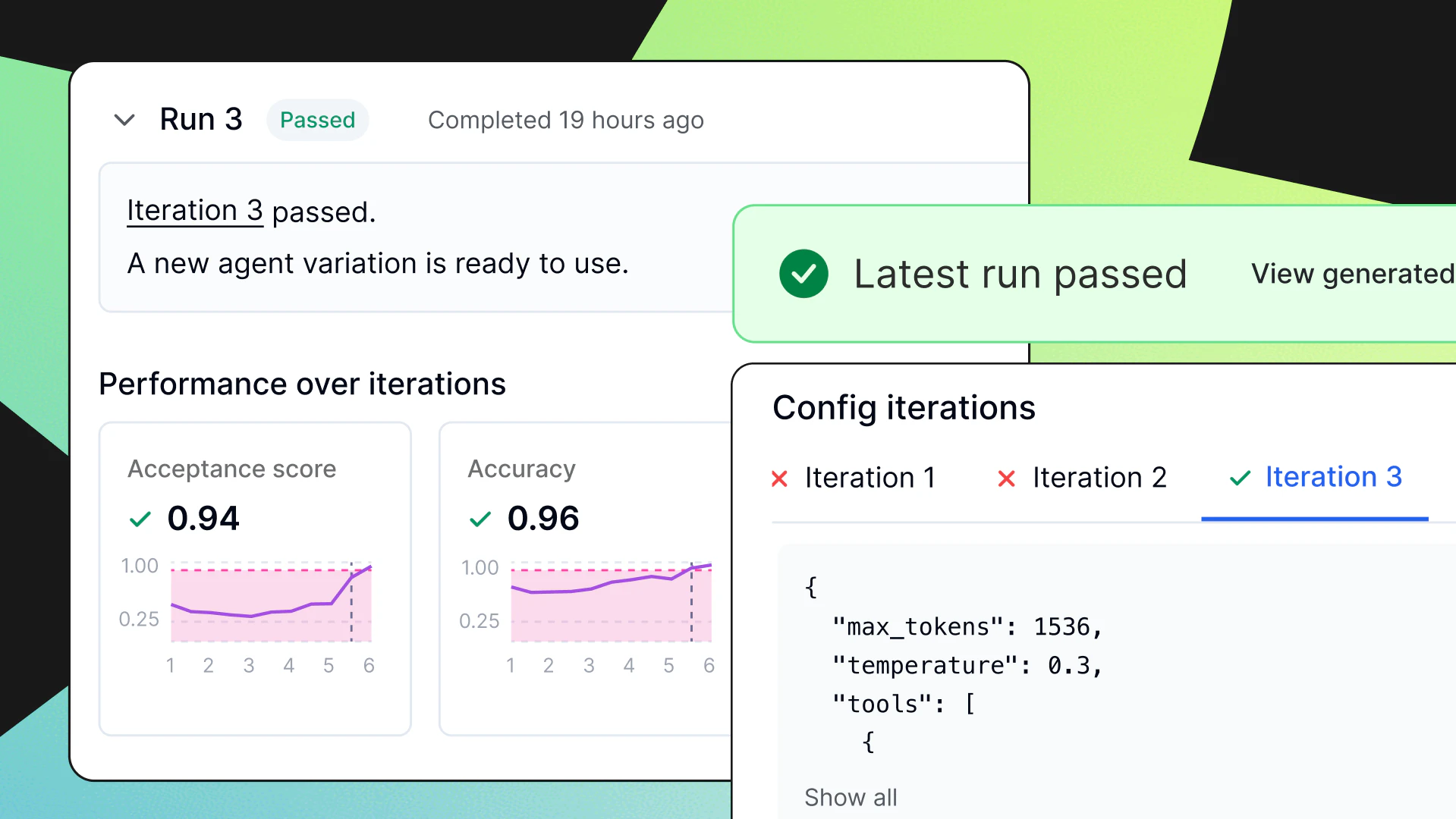
- Offline Evals: Benchmark prompt and model variants against curated test datasets before anything ships, with LLM judges scoring each candidate against the quality criteria the team defines.
- Guarded Rollouts: New agent versions can be rolled out progressively, with automatic rollback triggered by quality, cost, or latency signals, so regressions can be contained before they reach the full user base.
- Online Evals: LLM judges score agent outputs continuously in production against team-defined quality metrics, so teams have a real-time signal on how the system is performing against what matters.
- AI Insights: Tracks how changes to prompts, models, and parameters move key metrics (cost, quality, latency, business outcomes) over time, so teams can correlate configuration decisions to actual outcomes rather than inferring causation from incomplete signals.
- Experimentation: Run A/B and multi-armed bandit experiments on live traffic, scored by LLM judges and business metrics, so the decision about which configuration to ship is based on what actually performs better.
- Agent Optimization (private beta): Teams define the goal and the metrics that matter, and AgentControl creates the variants, runs the evals, and surfaces what performed best on their behalf.
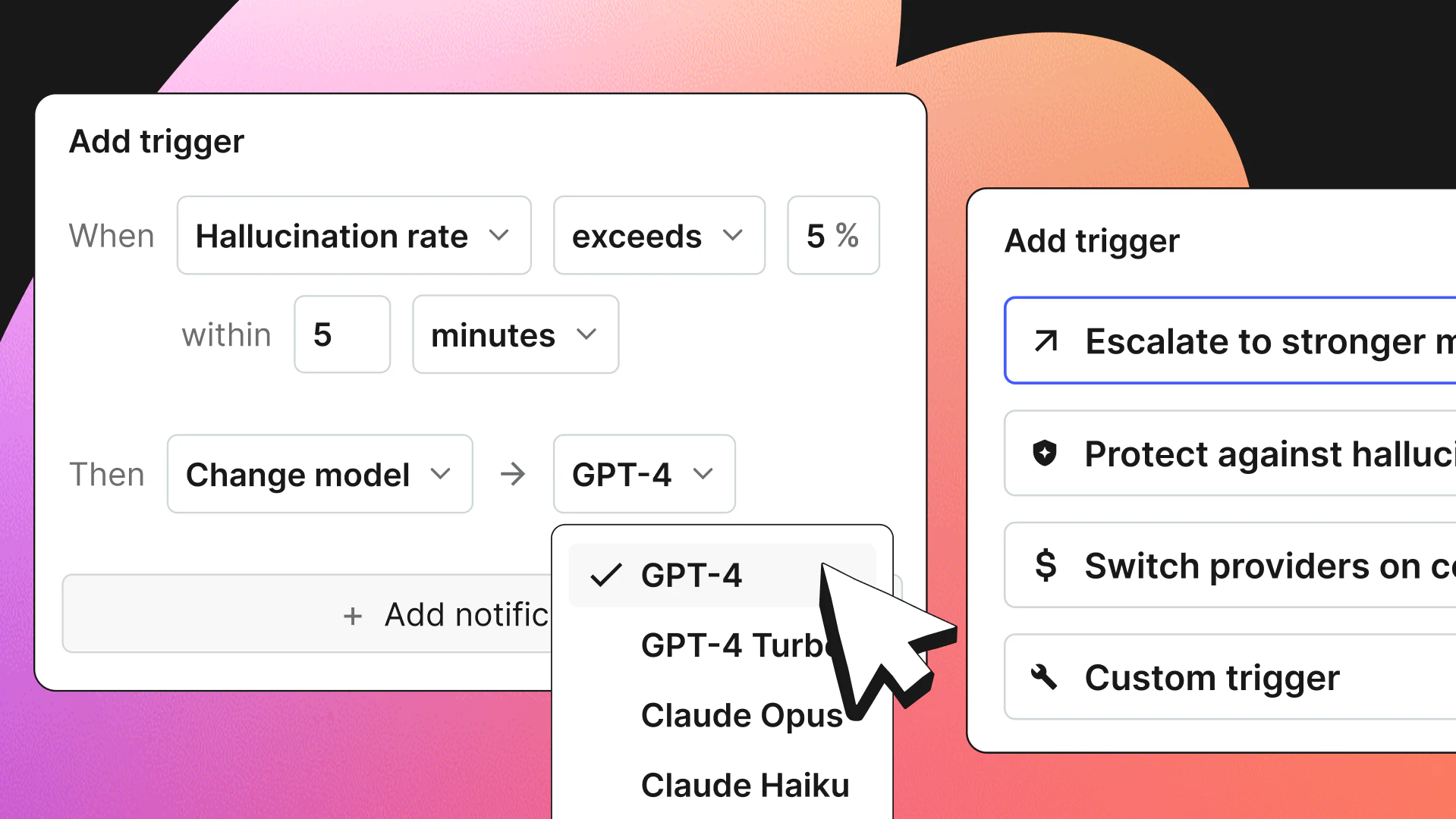
- Adaptive Triggers (private beta): What the other capabilities observe and measure, Adaptive Triggers acts on. Define the conditions and the response in advance: If error rates from a provider breach a threshold, switch to another; if quality scores drop, escalate to a more capable agent. The team decides what to do and AgentControl handles it automatically, before a bad response reaches the user.
“Most of the clients we work with are done proving AI works and need it to actually perform at scale, with real ROI, and enterprise-grade reliability. That's when the operational reality hits: behavior drifting in ways nobody anticipated, definitions scattered across teams and repos, and no reliable way to intervene before a customer feels the impact. This governance problem is one of the first things we tackle when we come in, and AgentControl is the first platform we've found that closes that gap—the ability to change how an agent behaves before a bad response reaches a customer, without touching code, is something our clients now treat as a foundational requirement."
— Clay Campbell, CEO, Seawolf AI
What ships today is the difference between knowing something went wrong and having already handled it. What the platform is building toward is a tighter loop: Production data feeding back into configuration continuously, and the system improving without waiting to be told what to fix.