Experiment sample size and run time
This topic explains how to determine the number of contexts to include in an experiment and how long to run the experiment for.
The number of contexts you include in an experiment is called the sample size. The larger the sample size for an experiment, the more confident you can be in its outcome. How big your sample size should be and how long you run an experiment for depends on how confident you want to be in the outcome.
Sample sizes for frequentist experiments
Before you start a fixed-horizon frequentist experiment, you can use LaunchDarkly’s sample size calculator to estimate the minimum detectable effect and sample size and duration for your experiments.
To learn more about how to calculate sample sizes, read Sample size calculations for frequentist experiments.
Only fixed-horizon frequentist experiments require that you calculate a sample size. You can run a sequential frequentist experiment without calculating sample size first. To learn more, read Fixed-horizon versus sequential.
Sample sizes for Bayesian experiments
For Bayesian experiments, we recommend you refer to the “Key takeaways” section on the experiment’s Results tab to find out how many more contexts you need exposed to your experiment before you can make a decision about the winning variation.
Generally, we recommend you run experiments for at least one week. You may want to run them longer to account for seasonal effects, such as if your end user’s behavior is different in the spring versus the summer. You can also run experiments for a shorter amount of time if enough contexts have encountered your experiment to determine a winning variation.
Sample size estimator
After you begin running an experiment, the experiment’s Results tab displays a sample size estimator in the “Summary” section that gives an estimate of how much more traffic needs to encounter your experiment before reaching your chosen probability to be best or desired significance level. Experiments with more than two variations do not display a sample size estimator.
In this example, for a probability to be best of 90%, 2,424 more contexts should be in the experiment before you stop the iteration and roll out the winning variation to all contexts:
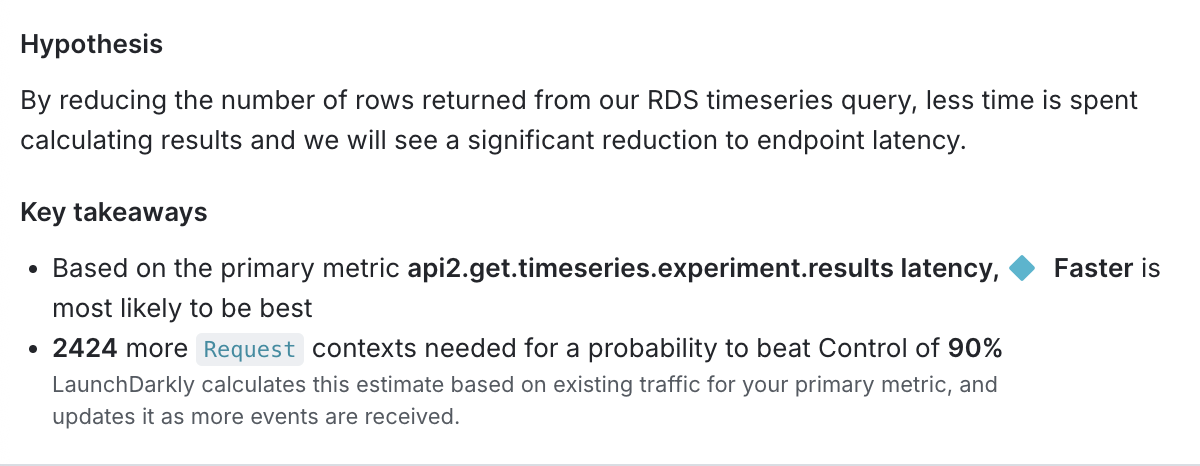
To be confident that the winning variation is the best out of the variations tested, wait until the sample size estimator indicates you have reached the needed number of contexts. Alternatively, if there is a low level of risk in rolling out the winning variation early, or if you don’t anticipate a significant impact on your user base, you can end the experiment before you reach that number.
The exposures graph
You can use the exposures graph to understand how many unique contexts have encountered each variation within the experiment over time:
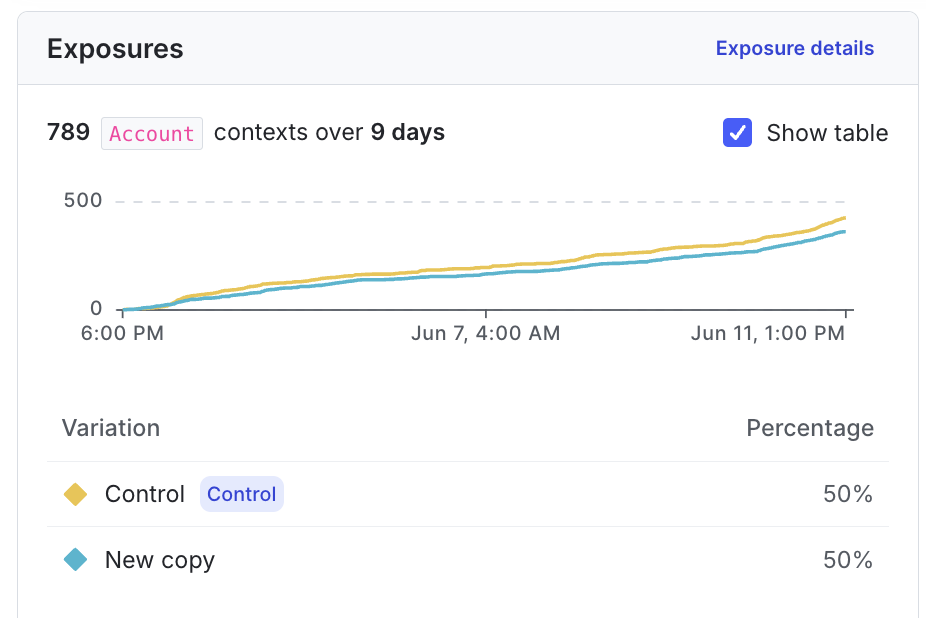
Here’s how the table counts unique contexts:
- The table only counts contexts with the same context kind as the experiment’s randomization unit. For example, if your experiment’s randomization unit is
user, then the table counts onlyusercontexts. The table won’t include anydeviceororganizationcontexts that are in the experiment. To learn more, read Randomization units. - If the same context is in the experiment multiple times, the table counts the context only once.