





Testing software changes is critical to increasing the odds of your code working properly when released to all users. But what are the best approaches to the testing process? And what are the most effective ways to maintain test environments?
At LaunchDarkly, we’re big fans of testing in production. The best way to know if a feature is likely to break production is to test that feature...in production. Thankfully, with LaunchDarky feature flags, you can safely test small code changes in production with a small targeted audience (e.g., a canary test).
While we endorse testing in production, we recognize that some use cases warrant pre-production test environments. This article explores the ins and outs of the testing environment best practices that every engineer and quality assurance (QA) analyst should know when setting up and navigating test beds.
Testing environments best practices snapshot
We'll get deeper into all the details further down the page, but here's a quick snapshot of the test environment best practices we'll be covering:
- Adopt a feature management mindset: Focus your testing efforts on individual features rather than the entire application.
- Prioritize communication: Integrate communication tools into your testing environment.
- Implement robust bug tracking: Set up systems to trace bugs and manage solution lifecycles.
- Leverage feature flags: Use feature flags to safely test in production. This technique allows for controlled rollouts and easy rollbacks if needed.
- Introduce chaos engineering: Introduce controlled failures to identify weaknesses and improve system resilience before issues arise in production.
- Encourage early testing: Encourage testing early in the development cycle. This proactive approach reduces the length and complexity of error logs.
- Optimize resource usage: Recycle test environments and resources where possible.
- Follow a structured framework: Stick to a Software Development Life Cycle (SDLC) framework for testing. This provides a clear, repeatable process for your testing.
- Integrate testing and deployment: Treat testing as an integral part of the deployment process (especially when it comes to testing in production).
- Adopt shift-right testing practices: While many focus on shift-left, also consider shift-right practices that extend testing into production (such as synthetic monitoring and real user monitoring).
Without tests, we would otherwise have gotten used to applications not behaving the way they're supposed to. Let's quickly discuss the concept of test environments as we explain how best to run them.
What is a test environment?
A test environment is what you get when you set aside storage, compute power, and other resources to create space for tests. It includes any new devices, physical and virtual, that you may have provisioned for the cause.
A good example would be a minimum satisfactory server that you list as "required specs" for your applications. If it works therein, it should definitely work with better machines. When testing in the cloud, your environment could be distributed such that tests run across different zones and machines.
As soon as you add test assets to an environment—the app and data to run tests with—you now have a test bed. We'll discuss the building and maintenance parts of test environments shortly. Let's quickly touch on staging environments and differentiate them from test environments before moving on.
Testing vs. staging environments
When you stage changes to an app, you’re essentially putting them through a “dress rehearsal” before moving them to production. If you’re developing an app for a client, for example, the staging environment is what you show them before getting the green light to go live.
While it may sound similar to a test environment, a staging environment exposes your app to more simultaneous tests than with the former. In most cases, a test environment precedes staging in the software development process. And staging tends to more closely resemble a production environment.
The testing environment has a finite set of parameters in which to explore specific features of the app. The staging environment, on the other hand, is accessible through all possible devices and provides interaction with the app as though it was live. Yet it's not.
The idea with a staging environment is, if a bug happens to escape the test environment, then staging can catch it before it gets passed along to customers. New versions and features are often run under staging conditions before final deployment. Teams try painstakingly to replicate production with their staging environments. Unfortunately, no matter how hard you try to simulate production, anomalies will nevertheless arise when you finally do put a feature out into the real world.
This is why, at LaunchDarkly, we encourage software teams to wrap code changes in feature flags and test those changes in production in a controlled manner. It’s not uncommon for our customers to shed their staging environments once they start running canary tests with LaunchDarkly feature flags. For example, Coder saved thousands of dollars a month upon removing their staging environments. Many customers want to get rid of their staging servers, owing to their being a pain to manage.
Of course, not all code changes can be easily feature-flagged. And some cases warrant a staging environment.
Staging environment maintenance
The first difference between a staging environment and production is access. You should make sure the staging is invisible to end-users other than the application’s owner(s). The best way to do this is by white-listing IPs or usernames.
Once approved, you can tear the staging environment down to avoid any confusion on which instance is final. If you absolutely don't want to close the staging application, you should make sure it doesn't have the same address as the live application. A "staging.appname" subdomain or prefix should help in the same manner.
5 best practices for building test environments
Let's discuss some best practices for building test environments. The tips below apply equally to a fresh application as to a live application undergoing continuous versioning.
1. Approach testing with a feature management mindset
Instead of editing and testing your entire codebase, isolate and test individual features. That's the spirit of feature management, a new class of software development and delivery tools and processes anchored in the use of feature flags. Not to belabor the point, but we believe the best use of your time is to test these small features in production. But even if you choose to test these features in pre-production test and staging environments, you can still derive benefits from dividing code changes into small chunks. For instance, testing small code changes requires less time writing out test scripts and running the tests overall.
2. Build communication into the environment
Set up integrations with the chat tools your team uses (e.g., Slack and Microsoft Teams), so that when your automated tests fail, you’re notified instantly. This ensures the right people can fix the errors quickly.
It can also be handy to notify team members who aren’t directly involved in the CI/CD pipeline. If non-developers have better visibility into forthcoming features and app improvements, then they can take actions that result in an enhanced customer experience.
3. Configure bug tracing and solution life cycles into test environments
Having a systematic way of handling test beds makes it easier to improve your tests with time. In the short run, it keeps everyone busy doing their part whenever they're called on. The difference with not having such a structure in place is that testing is often left to testers. No escalation of bugs and no tracing of how often a bug comes up will certainly drain valuable time and effort.
A third-party tool like Plutora BI can help to assign tasks to free and available developers can hasten the speed of deploying new versions. This test optimization tip pays off big-time through happier users down the line.
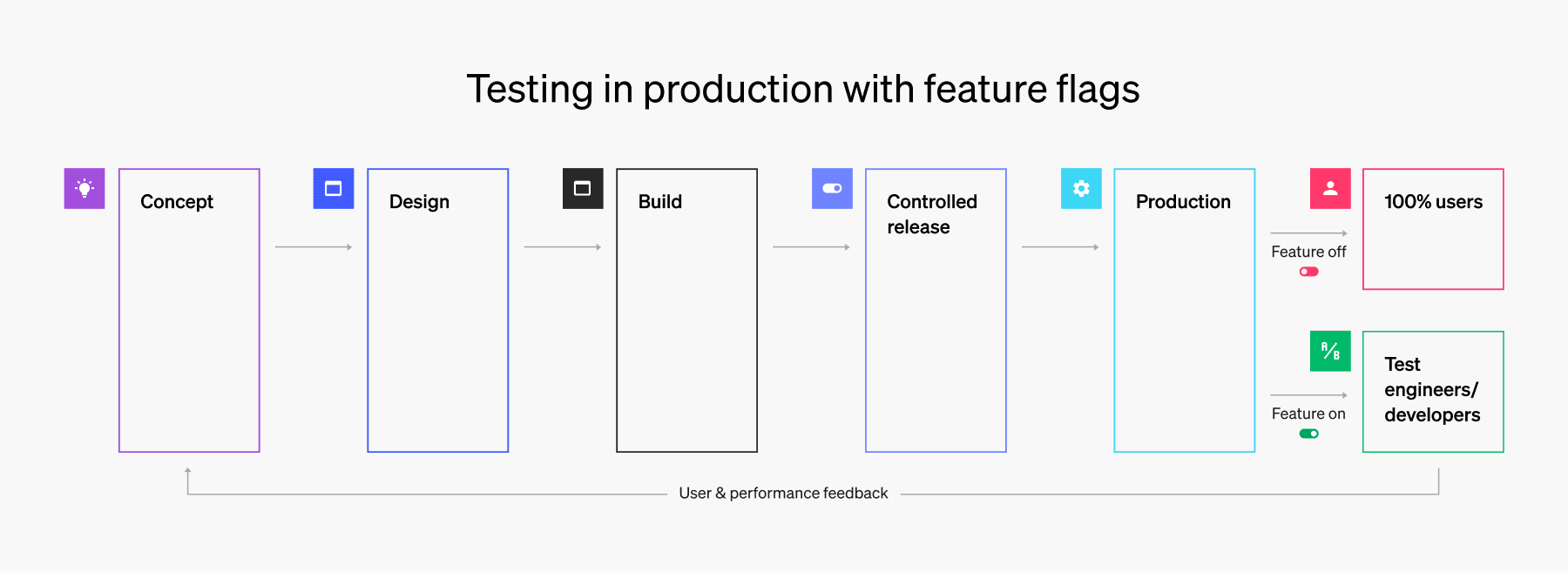
4. Leverage feature flags to test in production
With feature flags, you can reduce the overhead involved in testing. When you implement feature flags proficiently, in some cases, you can do away with testing and staging environments altogether. The same applications your customers are accessing will appear differently depending on feature flag rules. These rules can be based on attributes like location, access device, or even finer details like the user's unique ID.
With feature flags, you can show key stakeholders at your organization new features before releasing those features to users. The features can reside in production but without being exposed to end-users, thus reducing risk. Testing in production saves you money and resources that would otherwise be poured into isolated testing sessions in a setting that is only a shadow of the real world.
5. Introduce chaos engineering
Chaos engineering involves deliberately introducing controlled failures into your test environments to uncover weaknesses and improve system resilience. It's like training your application to handle a worst-case scenario, so when (not if) something goes wrong in production, your system doesn't just survive—it thrives.
Here's how to implement chaos engineering in your test environments:
- Start small: Begin with minor disruptions (like simulating a single server failure) before moving on to more complex scenarios.
- Define 'normal': Determine what constitutes normal behavior for your system under various conditions.
- Form a hypothesis: Predict how your system will respond to the chaos you're about to introduce.
- Unleash controlled chaos: Introduce your planned failure or disruption in the test environment.
- Observe and learn: Monitor how your system responds and compare it to your hypothesis.
- Improve and repeat: Use your findings to strengthen your system. Then, test again with new scenarios.
Test environment management 101 (TEM)
Test environments need more attention than a lot of development teams anticipate. Again, this is why we encourage developers to test features in production with feature flags. It’s cheaper, more efficient, and more realistic.
In any event, when it comes to managing test environments, it’s best to align with whatever software development methodology you’re already employing. A weak testing phase (owing to a mismanaged TEM approach) can strain the rest of your processes and demoralize environment managers.
Configuration management is crucial when doing your TEM upkeep. Making sure the servers, operating systems, the network, and any physical infrastructure are working at peak performance should be top of your management task list. So is making sure testing teams are aware of these variables' statuses.
If you're following the DevOps way of software development and delivery, TEM in the cloud includes making sure containers for tests are always ready when you need them. Some orchestration tools can do that part on your behalf. Either way, making sure your environment is ready for the test (near production) data has to be number one on your tasks list.
On that note, let's quickly expound on a few best practices for test environment management.
5 best practices for TEM
Encourage your teams to do the following when running and managing tests and their environments.
1. Encourage early testing to shorten error logs
Chances are you're using version control systems to build your codebase. Don't wait too long to run tests on every commit. Code reviews are standard, but even before lines of code pile up for a build, make sure your developers strive to keep a steady testing cadence.
It doesn't matter how much you've tweaked a development framework (SDLC, RAD, Agile)—they all involve testing. Rather than leaving it on the back burner, bring it forward and run tests frequently. For example, world-class software teams at companies like Netflix run thousands of tests.
2. Recycle test environments and resources
Recycling isn't just good for the environment—it goes a long way toward saving you time, money, and effort when managing test environments. If you choose to use on-premises infrastructure to run tests, make sure you invest some effort in keeping that in tip-top shape.
The same applies to test beds. Running on a local host doesn't mean every tester should have their own test resources to experiment on. Using the same silo helps gradually see how your tested apps affect given data. You also save on storage device costs while reducing your test environment's risk exposure. The same line of thinking helps when you've taken the infrastructure virtualization route.
3. Follow a software development life cycle (SDLC) for software testing
Just as the software development process follows a framework/methodology such as the SDLC model, so, too, should your testing. This approach creates a nested loop. Testing is already a key stage in the system development life cycle. The use of CI/CD tools and methods alone breeds an iterative mindset to software delivery. Using the same ideas and energy in testing makes your team eager to test in iteration until bugs are ironed out of your apps.
4. Consider testing as a part of deployment (i.e., testing in production)
A more recent way to manage tests and their environments is to consider testing in the production environment itself. This removes the existence of too many detached silos with test data. It also reduces the time it takes for changes to appear on the front-end for users to enjoy.
This way of looking at changes and their corresponding tests brings us back to the first best practice we shared in this post—taking a feature management approach. Duplicating test environments for the same codebase is time-consuming. Using a feature management platform like LaunchDarkly to test in production (live repo) is a better approach.
5. Adopt shift-right testing practices
Shift-left testing might catch the bugs early in building, but shift-right testing keeps the testing going. Shift-right testing extends your testing efforts into production. It's a safety net that catches issues your pre-production tests might have missed. While shift-left focuses on preventing issues, shift-right is all about rapid detection and response in the real world.
It includes automated testing that simulates user behavior in production. During this process, you collect data on how actual users interact with your application. This gives you insights no pre-production test could ever provide. Next, gradually release new features to small subsets of users, monitoring for any issues before a full release.
Shift-right testing doesn't replace your existing testing practices—it complements them.
Test in production safely with feature management
The best way to run tests in production is through the use of feature flags. A feature flag controls access to new code changes and their interpretations based on set rules. These rules can be location-based, for example, making it possible for users in different countries to experience different versions of the same application.
As an example, imagine a streaming service like Netflix using feature flags to control which users see which content based on copyright restrictions in different countries. Performing this kind of geo-targeting with multivariate feature flags is seamless.
LaunchDarkly’s support for early testing of small code changes in a live production environment using feature flags makes it safe to start testing very early in an app's development timeline.
Transcending the need for test environments
Given that feature flags reduce the risk of testing in production dramatically, do we still need pre-production test environments? It depends on who you ask. Some would argue that when you leverage feature management along with other risk-reducing modern development techniques, you can, indeed, toss out your staging environments. Others, however, would contend that teams need a hybrid of pre-production and production testing approaches. To be sure, some application changes do not lend themselves to being feature-flagged. As such, the next best option is to test these changes in an artificial testing environment.
But no doubt, with LaunchDarkly’s feature management platform, developers, DevOps engineers/SREs, and product managers can run vastly more tests in production than they’re doing today. And as a result, they can collect valuable feedback earlier in the software delivery process, shrink the blast radius of performance errors, and improve developer productivity and satisfaction.